ARTÍCULO ORIGINAL
CHAGAS, Edgar Thiago De Oliveira [1]
CHAGAS, Edgar Thiago De Oliveira. Aprendizaje profundo y sus aplicaciones hoy. Revista Científica Multidisciplinar Núcleo do Conhecimento. año 04, Ed. 05, Vol. 04, PP. 05-26 mayo 2019. ISSN: 2448-0959
RESUMEN
La inteligencia artificial ya no es una trama para las películas de ficción. La investigación en este campo aumenta cada día y proporciona nuevas perspectivas en el aprendizaje automático. Los métodos de aprendizaje profundo, también conocidos como Deep Learning, se utilizan actualmente en muchos frentes, como el reconocimiento facial en redes sociales, automóviles automatizados e incluso algunos diagnósticos en el campo de la medicina. El aprendizaje profundo permite a los modelos computacionales compuestos de innumerables capas de procesamiento "aprender" representaciones de datos con diferentes niveles de abstracción. Estos métodos mejoraron el reconocimiento de voz, objetos visuales, detección de objeto, entre las posibilidades. Sin embargo, esta tecnología sigue siendo poco conocida, y el propósito de este estudio es aclarar cómo funciona el aprendizaje profundo y demostrar sus aplicaciones actuales. Por supuesto, con la difusión de este conocimiento, el aprendizaje profundo puede, en un futuro próximo, presentar otras aplicaciones, aún más importantes para toda la humanidad.
Palabras clave: aprendizaje profundo, aprendizaje automático, IA, aprendizaje de maquinaria, inteligencia.
INTRODUCCIÓN
El aprendizaje profundo se entiende como una rama del aprendizaje automático, que se basa en un grupo de algoritmos que buscan dar forma a las abstracciones de alto nivel de los datos mediante un gráfico profundo con varias capas de procesamiento, Compuesto por varias alteraciones lineales y no lineales.
Deep Learning trabaja en el sistema informático para realizar tareas como el reconocimiento de voz, la identificación de imágenes y la proyección. En lugar de organizar la información para actuar a través de ecuaciones predeterminadas, este aprendizaje determina los patrones básicos de esta información y enseña a las computadoras a desarrollarse a través de la identificación de patrones en las capas de procesamiento.
Este tipo de aprendizaje es una rama integral de los métodos de aprendizaje automático basado en las representaciones de aprendizaje de la información. En este sentido, el aprendizaje profundo es un conjunto de algoritmos de máquina de aprendizaje que intentan integrar varios niveles, que son modelos estadísticos reconocidos que corresponden a diferentes niveles de definiciones. Niveles más bajos ayudan a definir muchas nociones de niveles más altos.
Hay innumerables investigaciones actuales en esta área de la inteligencia artificial. La mejora en las técnicas de Deep Learning ha implementado mejoras en la capacidad de los ordenadores para entender lo que se solicita. La investigación en este campo busca promover mejores representaciones y modelos elaborados para identificar estas representaciones de información no etiquetada a gran escala, algunas como base en los hallazgos de la neurociencia y en la interpretación de Patrones de procesamiento y comunicación de datos en el sistema nervioso. Desde 2006, este tipo de aprendizaje ha surgido como una nueva rama de la investigación de aprendizaje automátic[2]o.
Recientemente, se han desarrollado nuevas técnicas a partir del Deep Learning, que han impactado varios estudios sobre el procesamiento de señales y la identificación de patrones. Tenga en cuenta una serie de nuevos comandos problemáticos que se pueden resolver a través de estas técnicas, incluyendo el aprendizaje automático y puntos clave de inteligencia artificial.
Hay una gran cantidad de atención de los medios de comunicación, seg[3]ún Yang et al, sobre los avances logrados en esta área. Las grandes organizaciones tecnológicas han aplicado muchas inversiones en investigación de Deep Learning y sus nuevas aplicaciones.
El aprendizaje profundo abarca el aprendizaje en diversos niveles de representación e intangibilidad que ayudan en el proceso de comprensión de la información, imágenes, sonidos y textos.
Entre las exposiciones disponibles sobre el aprendizaje profundo, es posible identificar dos puntos llamativos. El primero demuestra que son modelos formados por innumerables capas o pasos de procesamiento de datos no lineales y también son prácticas supervisadas de aprendizaje o no, de la representación de atribuciones en capas posteriores e intangibles.
Se entiende que Deep Learning está en las articulaciones entre las ramas de la investigación de redes neuronales, IA, modelado gráfico, identificación y optimización de patrones y procesamiento de señales. La atención que se presta al aprendizaje profundo se debe a la mejora de la capacidad de procesamiento de chips, el considerable aumento en el tamaño de la información utilizada para la formación y los recientes avances en los estudios de aprendizaje automático y procesamiento de señales.
Este progreso permitió a las prácticas de Deep Learning explotar eficazmente aplicaciones complejas y no lineales, identificar representaciones de recursos distribuidos y jerárquicos, y permitir el uso efectivo de Información etiquetada y sin etiquetar.[4]
El aprendizaje profundo se refiere a una clase completa de métodos y proyectos de machine learning, que reúnen la característica de usar muchas capas de datos procesados no lineales de carácter jerárquico. Debido al uso de estos métodos y proyectos, una gran parte de los estudios en esta esfera se pueden clasificar en tres conjuntos principales, según Pang [5]et al, que son las redes profundas para el aprendizaje no supervisado; Supervisado e híbrido.
Redes profundas para el aprendizaje no supervisado están disponibles para aprehender la correlación de alta secuencia de la información analizada o identificable para la verificación o asociación de estándares cuando no hay datos sobre los estereotipos de las clases Disponible en la base de datos. El aprendizaje de la atribución o representación no supervisada se refiere a redes profundas. Además, puede buscar la asignación de distribuciones estadísticas agrupadas de los datos visibles y sus clases relacionadas cuando estén disponibles, y puede cubrirse como parte de los datos visibles.
Las redes neuronales profundas para el aprendizaje supervisado deben proporcionar discriminación para clasificar los patrones, por lo general individualizando las distribuciones subsiguientes de clases vinculadas a la información visible, que siempre son Disponible para este aprendizaje supervisado, también conocido como redes discriminativas profundas.
Las redes híbridas profundas se destacan por la discriminación identificada con los resultados de redes profundas generativas o no supervisadas, que se pueden lograr a través de la mejora y/o regularización de las redes supervisadas profundas. Sus atribuciones también pueden lograrse cuando las directrices discriminatorias para el aprendizaje supervisado se utilizan para evaluar las normas en cualquier red profunda generativa o no supervisada[6].
Las redes profundas y recurrentes son modelos que presentan un alto rendimiento en cuestiones de identificación de patrones cuestionables en Ivain y el habl[7]a. A pesar de su poder de representación, la gran dificultad en la conformación de las redes neuronales profundas con el uso genérico persiste hasta el día de hoy. En relación con las redes neuronales recurrentes, los estudios realizados po[8]r Hinton et al iniciaron la moldeo en capas.
El presente estudio tiene como objetivo aclarar el progreso del Deep Learning y sus aplicaciones de acuerdo con las investigaciones más recientes. Para ello, se llevará a cabo una investigación cualitativa descriptiva, con el uso de libros, tesis, artículos y sitios web para conceptualmente los avances en el área de la inteligencia artificial y especialmente en el aprendizaje profundo.
Ha habido un creciente interés en el aprendizaje automático desde la última década, dado que existe una interacción cada vez mayor entre las aplicaciones, ya sean móviles o dispositivos informáticos, con los individuos, a través de programas para detectar el spam, Reconocimiento en fotos en redes sociales, smartphones con reconocimiento facial, entre otras aplicaciones. De acuerdo con Gartner,[9] todos los programas corporativos tendrán alguna función vinculada al aprendizaje automático hasta el año 2020. Estos elementos pretenden justificar la elaboración de este estudio.
DESARROLLO HISTÓRICO DEL APRENDIZAJE PROFUNDO
La inteligencia artificial no es un descubrimiento reciente. Viene de la década de 1950, pero a pesar de la evolución de su estructura, algunos aspectos de la credibilidad faltaban. Uno de estos aspectos es el volumen de datos, originado en amplia variedad y velocidad, permitiendo la creación de estándares con altos niveles de precisión. Sin embargo, un punto relevante fue sobre cómo se procesaron los modelos de aprendizaje automático de gran tamaño con grandes cantidades de información, porque los equipos no pudieron realizar dicha acción.
En ese momento, se identificó el segundo aspecto referido a la programación paralela en GPUs. Las unidades de procesamiento gráfico, que permiten la realización de operaciones matemáticas en paralelo, especialmente aquellas con matrices y vectores, que están presentes en modelos de redes artificiales, permitieron la evolución actual, es decir, la Resumen de Big Data (gran volumen de datos); Los modelos de procesamiento paralelo y aprendizaje automático se presentan como resultado de la inteligencia artificial.
La unidad básica de una neurored artificial es una neurona matemática, también llamada nodo, basada en la neurona biológica. Los vínculos entre estas neuronas matemáticas están relacionados con los de los cerebros biológicos, y especialmente en la forma en que estas asociaciones se desarrollan con el tiempo, llamado "formación".
Entre la segunda mitad de la década de 80 y el comienzo de la década de 90, ocurrieron varios avances relevantes en la estructura de las redes artificiales. Sin embargo, la cantidad de tiempo e información necesaria para lograr buenos resultados procrastinado la adopción, afectando el interés por la inteligencia artificial.
A principios de los 2000 años, el poder de la computación se expandió y el mercado experimentó un "boom" de técnicas computacionales que antes no eran posibles. Fue cuando el Deep Learning surgió del gran crecimiento computacional de ese tiempo como un mecanismo esencial para la elaboración de sistemas de inteligencia artificial, ganando varias competiciones de machine learning. El interés por el aprendizaje profundo sigue creciendo hasta el día de hoy y surgen en todo momento varias soluciones comerciales.
Con el tiempo, se crearon varias investigaciones con el fin de simular el funcionamiento del cerebro, especialmente durante el proceso de aprendizaje para crear sistemas inteligentes que podrían recrear tareas como la clasificación y el reconocimiento de patrones, entre Otras actividades. Las conclusiones de estos estudios generaron el modelo de neurona artificial, colocado posteriormente en una red interconectada llamada red neuronal.
En 1943, Warren McCulloch, neurofisiólogo, y Walter Pitts, matemático, crearon una red neuronal simple utilizando circuitos eléctricos y elaboraron un modelo informático para redes neuronales basado en conceptos matemáticos y algoritmos llamados umbral Lógica lógica o umbral, que permitía la investigación en la red neuronal dividida en dos hilos: centrándose en el proceso biológico del cerebro y otro centrado en la aplicación de estas redes neuronales dirigidas a la inteligencia artificial.[10]
Donald Hebb[11], en 1949, escribió una obra donde informó que los circuitos neuronales se fortalecen cuanto más se utilizan, como la esencia del aprendizaje. Con el avance de las computadoras en la década de 1950, la idea de una red neuronal ganó fuerza y Nathanial Rochester d[12]e los laboratorios de estudio de IBM trató de constituir uno, sin embargo, no tuvo éxito.
El proyecto de investigación de verano de Dart[13]mouth sobre inteligencia artificial, en 1956, impulsó las redes neuronales, así como la inteligencia artificial, fomentando la investigación en esta área en relación con el procesamiento neuronal. En los años que siguieron, John von Neumann imitó las funciones simples de las neuronas con tubos de vacío o telegrafías, mientras que Frank Rosenblatt inició el proyecto Perceptron, analizando el funcionamiento del ojo de una mosca. El resultado de esta investigación fue un hardware, que es la red neuronal más antigua utilizada hasta el día de hoy. Sin embargo, el Perceptron es muy limitado, que fue probado por Marvin y Papert[14]
Figura 1: estructura de red neuronal
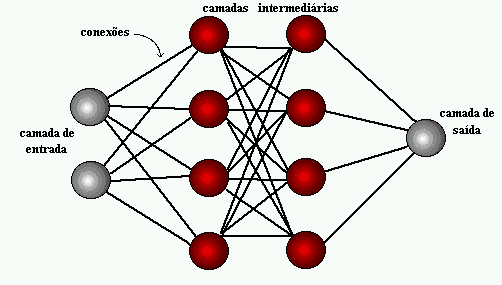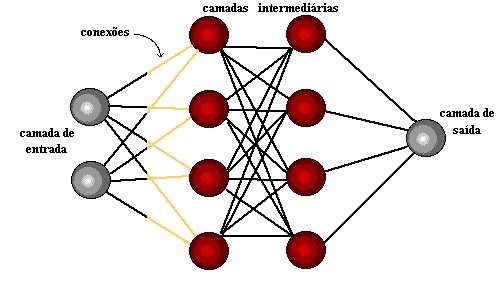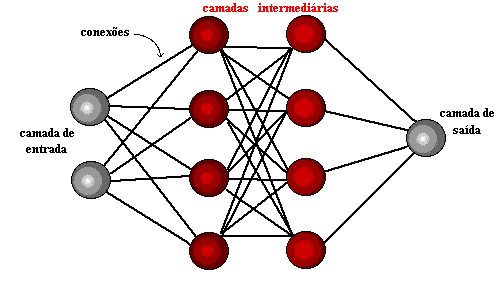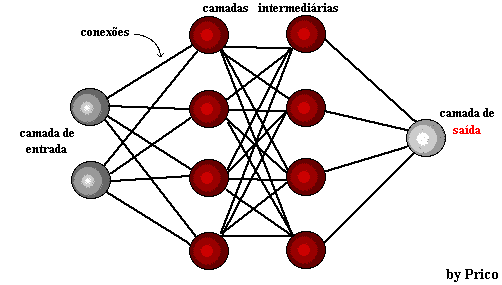
Unos años más tarde, en 1959, Bernard Widrow y Marcian Hoff desarrollaron dos modelos llamados "Adaline" y "Madaline". La nomenclatura se deriva del uso de varios elementos: ADAptive LINear. Adaline fue creada para identificar patrones binarios con el fin de hacer predicciones sobre el próximo bit, mientras que "Madaline" fue la primera red neuronal aplicada a un problema real, usando un filtro adaptativo. El sistema todavía está en uso, pero sólo comercial.[15]
El progreso logrado anteriormente condujo a la creencia de que el potencial de las redes neuronales se limitaba a la electrónica. Se cuestionó el impacto que tendrían las "máquinas inteligentes" en el hombre y en la sociedad en su conjunto.
El debate sobre cómo la inteligencia artificial afectaría al hombre, suscitaron críticas sobre la investigación en redes neuronales que causaron una reducción de la financiación y, en consecuencia, estudios en la zona, que se mantuvo hasta 1981.
Al año siguiente, varios eventos Reacel interés en este campo. John Hopfield de Caltech presentó un enfoque para crear dispositivos útiles, demostrando sus asignaciones[16]. En 1985, el Instituto Americano de física comenzó una reunión anual llamada redes neuronales para la computación. En 1986, los medios empezaron a reportar las redes neuronales de varias capas, y tres investigadores presentaron ideas similares, llamadas redes backpropagation, porque distribuyen fallas de identificación de patrones a través de la red.
Las redes híbridas tenían sólo dos capas, mientras que las redes backpropagation [17]presentan muchas, de modo que esta red retiene la información más lentamente, porque necesitan miles de iteraciones para aprender, pero también presentan más resultados Precisa. Ya en 1987, se celebró la primera Conferencia Internacional sobre redes neuronales del Instituto de ingenieros eléctricos y electrónicos (IEEE).
En el año 1989, los científicos crearon algoritmos que usaban redes neuronales profundas, pero el tiempo de "aprendizaje" fue muy largo, lo que impidió su aplicación a la realidad. En 1992, Juyang Weng Diulga el método Cresceptron para realizar el reconocimiento de objetos 3D de escenas tumultuosas.
A mediados de los 2000 años, el término aprendizaje profundo o aprendizaje profundo comienza a ser difundido después de un artículo de Geoffrey Hinton y [18]Ruslan Salakhutdinov, que demostró cómo una red neuronal multicapa podría ser entrenada previamente, una capa a la vez .
En 2009, se lleva a cabo el taller de procesamiento de sistemas de redes neuronales sobre el aprendizaje profundo para el reconocimiento de voz y se verifica que con un extenso grupo de datos, las redes neuronales no necesitan formación previa y las tasas de fracaso caen Significativament[19]e.
En 2012, las investigaciones proporcionaron algoritmos de identificación de patrones artificiales con rendimiento humano en algunas tareas. Y el algoritmo de Google identifica los felinos.
En 2015, Facebook utiliza el aprendizaje profundo para marcar y reconocer automáticamente a los usuarios en las fotos. Los algoritmos realizan tareas de reconocimiento facial utilizando redes profundas. En el año 2017, hubo una adopción a gran escala de aprendizaje profundo en diversas aplicaciones comerciales y dispositivos móviles, así como el progreso en la investigació[20]n.
El compromiso de Deep Learning es demostrar que un conjunto bastante extenso de datos, procesadores rápidos y un algoritmo bastante sofisticado, hace posible que los equipos realicen tareas como el reconocimiento de imágenes y voz, entre otras Posibilidades.
La investigación en redes neuronales ha ganado prominencia con atribuciones prometedoras presentadas por los modelos de redes neuronales creadas, debido a las recientes innovaciones tecnológicas de implementación que permiten desarrollar estructuras neuronales audaces Paralelamente al hardware, logrando rendimientos satisfactorios de estos sistemas, con un rendimiento superior a los sistemas convencionales, incluyendo. La evolución de las redes neuronales es el aprendizaje profundo.
DEEP LEARNING
Inicialmente es hasta diferenciar la inteligencia artificial, el aprendizaje automático y el aprendizaje profundo.
Figura 2: inteligencia artificial, aprendizaje automático y aprendizaje profundo
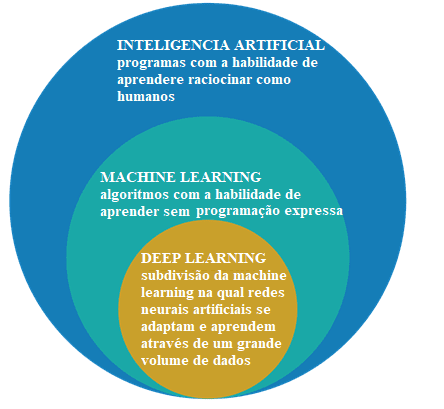
El campo de estudio de la inteligencia artificial es la investigación y el diseño de fuentes inteligentes, es decir, un sistema que puede tomar decisiones basadas en una característica considerada inteligente. En la inteligencia artificial hay varios métodos que modelan esta característica y entre ellos está la esfera del aprendizaje automático, donde se toman decisiones (inteligencia) basadas en ejemplos y no en una programación determinada.
Los algoritmos de aprendizaje automático requieren información para eliminar características y aprendizajes que se pueden usar para tomar decisiones futuras. El aprendizaje profundo es un subgrupo de las técnicas de aprendizaje automático, que generalmente utilizan redes neuronales profundas y necesitan una gran cantidad de información para el entrenamient[21]o.
Según Santana, existe[22]n algunas diferencias entre las técnicas de aprendizaje automático y los métodos de Deep Learning, y las principales son la necesidad y el impacto del volumen de datos, la potencia computacional y la flexibilidad en el modelado de problemas.
El aprendizaje automático necesita datos para identificar patrones, pero hay dos problemas con respecto a los datos que se refieren a la dimensionalidad y el estancamiento del rendimiento mediante la introducción de más datos más allá del límite de comportamiento. Se verifica que hay una reducción en el rendimiento significativo cuando ocurre esto. En relación a la dimensionalidad ocurre lo mismo, ya que hay mucha información para detectar, a través de las técnicas clásicas la dimensión del problema.
Figura 3: comparación del aprendizaje profundo con otros algoritmos relativos a la cantidad de datos.
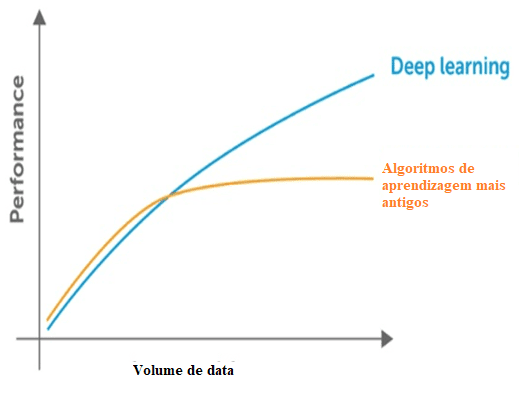
Las técnicas clásicas también presentan un punto de saturación en relación a la cantidad de datos, es decir, tienen un límite máximo para extraer la información, que no se produce con el aprendizaje profundo, creada para trabajar con un gran volumen de datos.
En relación con el poder computacional para el aprendizaje profundo, sus estructuras son complejas y requieren un gran volumen de datos para su formación, lo que demuestra su dependencia de una gran potencia computacional para implementar estas prácticas. Mientras que otras prácticas clásicas necesitan una gran cantidad de potencia computacional como CPU, las técnicas de Deep Learning son superiores.
Las búsquedas relacionadas con la computación paralela y el uso de GPU con la arquitectura unificada de dispositivos CUDA-compute o la arquitectura de dispositivos de computación unificada han iniciado el aprendizaje profundo, ya que era inviable con el uso de una CPU simple.
En una comparación con la formación de una red neuronal profunda o aprendizaje profundo con la utilización de una CPU, resulta que sería imposible obtener resultados satisfactorios incluso con el entrenamiento prolongado.
El aprendizaje profundo, también conocido como aprendizaje profundo, es una parte del aprendizaje automático, y aplica algoritmos para procesar datos y reproducir el procesamiento realizado por el cerebro humano.
El aprendizaje profundo utiliza capas de neuronas matemáticas para procesar datos, identificar el habla y reconocer objetos. Los datos se transmiten a través de cada capa, con la salida de la capa anterior que concede la entrada a la siguiente capa. La primera capa de una red se denomina capa de entrada y la última es la capa de salida. Las capas intermedias se denominan capas ocultas, y cada capa de la red está formada por un algoritmo simple y uniforme que abarca un tipo de función de activación.
Figura 4: red neuronal simple y red neuronal profunda o aprendizaje profundo
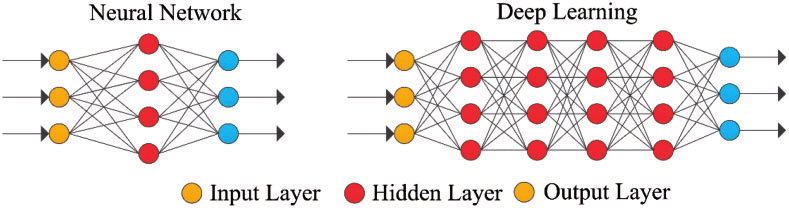
Las capas más externas en amarillo son las capas de entrada o salida, y las capas intermedias o ocultas están en rojo. Deep Learning es responsable de los recientes avances en computación, reconocimiento de voz, procesamiento del lenguaje e identificación auditiva, basados en la definición de redes neuronales artificiales o sistemas computacionales que reproducen el Cómo actúa el cerebro humano.
Otro aspecto del Deep Learning es la extracción de recursos, que utiliza un algoritmo para crear automáticamente parámetros relevantes de la información para la formación, el aprendizaje y la comprensión, una tarea del ingeniero de inteligencia artificial.
El aprendizaje profundo es una evolución de las redes neuronales. El interés por el aprendizaje profundo ha crecido gradualmente en los medios de comunicación y se han difundido varias investigaciones en el área y su aplicación ha llegado a los coches, en el diagnóstico de cáncer y autismo, entre otras aplicaciones[23]
Los primeros algoritmos de aprendizaje profundo con múltiples capas de asignaciones no lineales presentan sus orígenes en Alexey Grigoryevich Ivakhnenko, que desarrolló el método del grupo de manipulación de datos y Valentin Grigor ' Evich Lapa, autor de la obra Cybernetics y técnicas de pronóstico en el año 1965.[24]
Ambos utilizaban modelos delgados y profundos con funciones de activación polinómica, que se investigaron utilizando métodos estadísticos. A través de estos métodos seleccionaron en cada capa los mejores recursos y se transmitieron a la siguiente capa, sin usar backpropagation para "entrenar" la red completa, pero usaron cuadrados mínimos en cada capa, donde los anteriores fueron instalados desde Independientemente en las capas posteriores, manualmente.
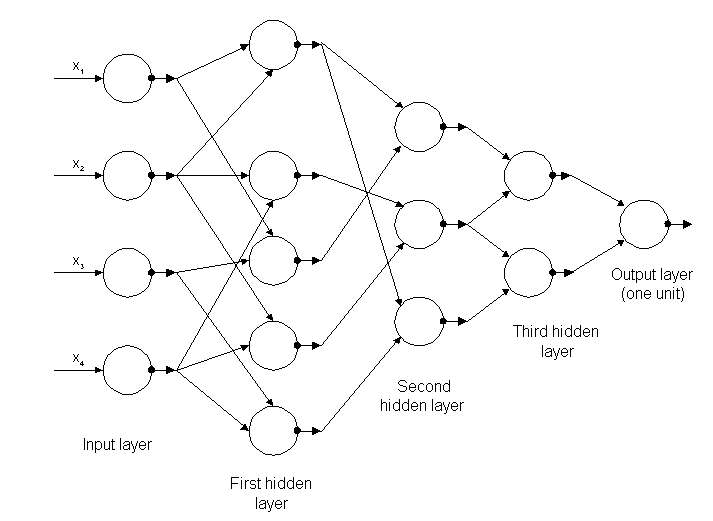
Figura 5: estructura de la primera red profunda conocida como Alexey Grigorevich Ivakhnenko
Al final de la década de 1970 se produjo el invierno de la inteligencia artificial, una reducción drástica de la financiación para la investigación sobre el tema. El impacto ha limitado los avances en las redes neuronales profundas y la inteligencia artificial.
Las primeras redes neuronales convolucionales fueron utilizadas por Kunihiko Fukushima, con varias capas de agrupamiento y convoluciones, en 1979. Creó una red neuronal artificial, llamada Neocognitron, con un diseño jerárquico y multicapa, que permitía a la computadora identificar patrones visuales. Las redes eran similares a las versiones modernas, con "formación" centrada en la estrategia de fortalecimiento de la activación periódica en innumerables capas. Además, el diseño de Fukushima hizo posible que los recursos más relevantes se adaptaran manualmente incrementando la importancia de ciertas conexiones[25].
Muchas pautas de Neocognitron todavía están en uso, ya que las conexiones de arriba hacia abajo y las nuevas prácticas de aprendizaje han promovido la realización de varias redes neuronales. Cuando se presentan varios patrones al mismo tiempo, el modelo de cuidado selectivo puede separarlos e identificar los patrones individuales, prestando atención a cada uno de ellos. Un Neocognitron más actualizado puede identificar patrones con falta de datos y completar la imagen insertando la información que falta, que se llama inferencia.
El backpropagation utilizado para el entrenamiento de fallas de aprendizaje profundo progresó a partir de 1970 en adelante, cuando Seppo Linnainmaa escribió una tesis, insertando un código FORTRAN para backpropagation, sin tener éxito hasta 1985. Rumelhart, Williams y Hinton luego demostraron backpropagation en una red neuronal con representaciones de distribución.
Este descubrimiento permitió que el debate sobre la IA llegara a la psicología cognitiva que iniciara preguntas sobre la comprensión humana y su relación con la lógica simbólica, así como las conexiones. En 1989, Yann LeCun realizó una demostración práctica de backpropagation, con la combinación de redes neuronales convolucionales para identificar los dígitos escritos.
En este período hubo una vez más una escasez de fondos para la investigación en esta área, conocida como el segundo invierno de la IA, que se produjo entre 1985 y 1990, afectando también a la investigación en redes neuronales y Deep Learning. Las expectativas presentadas por algunos investigadores no alcanzan el nivel esperado, que irrita profundamente a los inversionistas.
En 1995, Dana cortes y Vladimir Vapnik crearon la máquina de vectores de [26]soporte o máquina de vectores de apoyo que era un sistema para mapear e identificar información similar. La memory-LSTM a largo plazo para las redes neuronales periódicas fue elaborada en 1997 por Sepp Hochreiter y Juergen Schmidhube[27]r.
El siguiente paso en la evolución del aprendizaje profundo se produjo en 1999, cuando las unidades de procesamiento de datos y de procesamiento de gráficos (GPU) se volvieron más rápidas. El uso de GPUs y su rápido procesamiento representaron un aumento en la velocidad de los ordenadores. Las redes neuronales compitieron con máquinas de vectores de soporte. La red neuronal era más lenta que una máquina de vectores de soporte, pero obtuvieron mejores resultados y continuaron evolucionando a medida que se añadía más información de formación.
En el año 2000, se identificó un problema llamado gradiente de desvanecimiento. Las asignaciones aprendidas en capas inferiores no se transmitieron a las capas superiores sin embargo, solo se produjeron en aquellos con métodos de aprendizaje basados en degradados. El origen del problema estaba en algunas funciones de activación que redujeron su entrada afectando al rango de salida, generando grandes áreas de entrada asignadas en un rango muy pequeño, causando un gradiente descendente. Las soluciones implementadas para resolver el problema fueron el pre-entrenamiento capa por capa y el desarrollo de una memoria a largo y corto plaz[28]o.
En 2009, FEI-FEI Li lanzó ImageNet con una[29] base de datos gratuita de más de 14 millones imágenes, centradas en el "entrenamiento" de las redes neuronales, señalando cómo los macrodatos afectarían el funcionamiento del aprendizaje automático.
La velocidad de las GPU, hasta el año 2011, continuó aumentando permitiendo la composición de redes neuronales convolucionales sin la necesidad de pre-entrenamiento capa por capa. Por lo tanto, se hizo famoso que el Deep Learning era ventajoso en términos de eficiencia y velocidad.
En la actualidad, el procesamiento de Big Data y la progresión de la inteligencia artificial dependen del aprendizaje profundo, que puede elaborar sistemas inteligentes y promover la creación de una inteligencia artificial totalmente autónoma, lo que creará un impacto en Toda la sociedad.
FLEXIVILIDAD DE LAS REDES NEURONALES Y SUS APLICACIONES
A pesar de la existencia de varias técnicas clásicas, la estructura DEEP Learning y su unidad básica, la neurona es genérica y muy flexible. Al hacer una comparación con la neurona humana que proporciona sinapsis podemos identificar algunas correlaciones entre ellos.
Figura 6: correlación entre una neurona humana y una red neuronal artificial
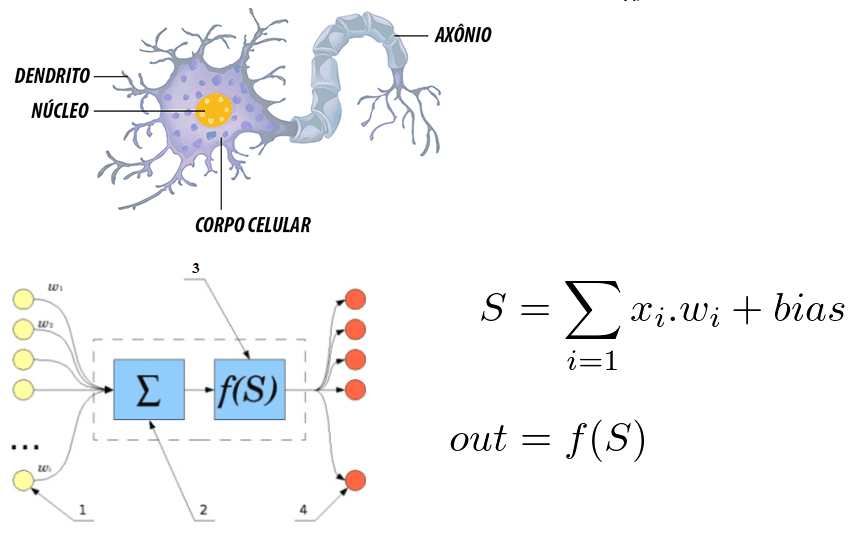
Se observa que la neurona está formada por las dendritas que son los puntos de entrada, un núcleo que representa en las redes neuronales artificiales el núcleo de procesamiento y el punto de salida que representa el axón. En ambos sistemas la información entra, se procesa y cambia.
Considerándola como una ecuación matemática, la neurona refleja la suma de las entradas multiplicadas por pesos, y este valor pasa por una función de activación. Esta suma fue realizada por McCulloch y Pitts en 1943[30]
En relación con el interés notorio en el aprendizaje profundo hoy en día, Santa[31]na considera que se debe a dos factores que son la cantidad de información disponible y la limitación de las técnicas más antiguas, además de la potencia computacional actual para entrenar redes Complejo. La flexibilidad para interconectar múltiples neuronas en una red más compleja es el diferencial de las estructuras de DEEP Learning. Una red neuronal convolucional se utiliza ampliamente para el reconocimiento facial, la detección de imágenes y la extracción de asignación.
Una red neuronal convencional consta de varias capas, denominadas capas. Dependiendo del problema a resolver la cantidad de capas puede variar, pudiendo tener hasta cientos de capas, siendo factores que influyen en la cantidad la complejidad del problema, tiempo y potencia computacional
Hay varias estructuras diferentes con innumerables propósitos y su funcionamiento también depende de la estructura y todos se basan en redes neuronales.
Figura 7: ejemplos de redes neuronales
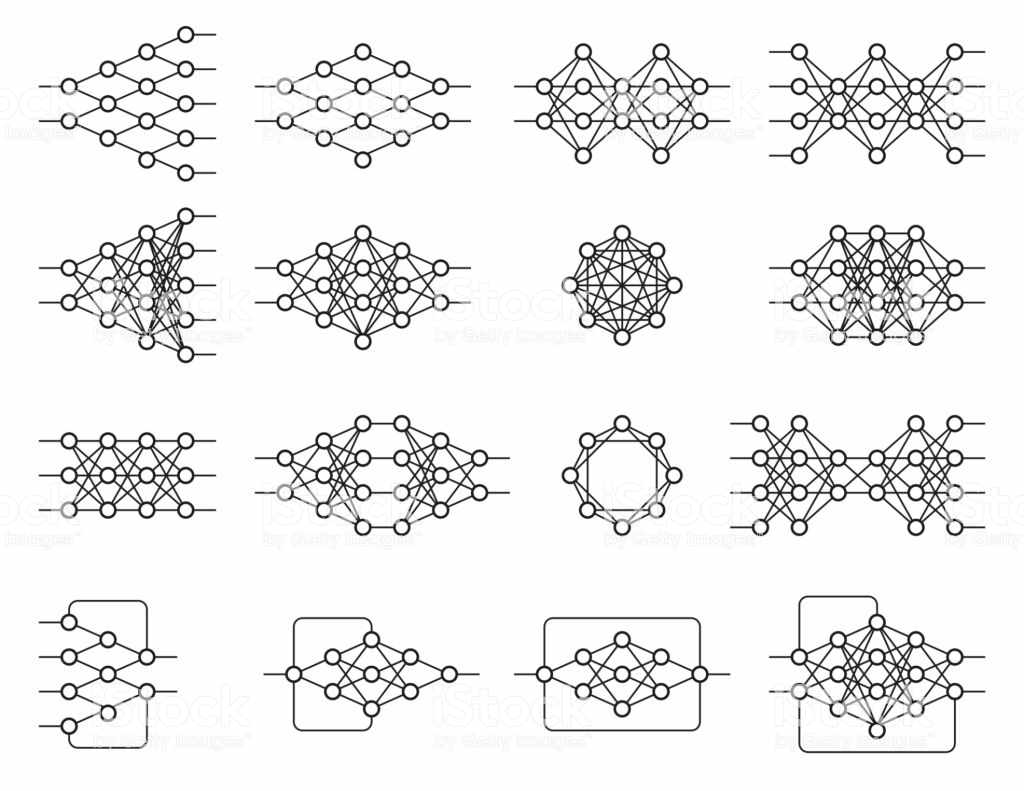
Esta flexibilidad arquitectónica permite el aprendizaje profundo para resolver diversos problemas. El aprendizaje profundo es una técnica objetiva general, pero los alcances más avanzados fueron: visión por computador, reconocimiento de voz, procesamiento de lenguaje natural, sistemas de recomendación.
La visión computacional abarca el reconocimiento de objetos, la segmentación semántica, especialmente los automóviles autónomos. Se puede afirmar que la visión computacional es parte de la inteligencia artificial y se define como un conjunto de conocimientos que busca el modelado artificial de la visión humana con el objetivo de imitar sus funciones, a través del desarrollo de software y hardware Avanzad[32]a.
Entre las aplicaciones de la visión computacional están el uso militar, mercado de marketing, seguridad, servicios públicos y en el proceso de producción. Los vehículos autónomos representan el futuro del tráfico más seguro, pero todavía se encuentra en fase de pruebas, ya que engloba varias tecnologías aplicadas a una función. La visión computacional en estos vehículos, ya que permite el reconocimiento del camino y los obstáculos, mejorando las rutas.
En el contexto de la seguridad, los sistemas de reconocimiento facial se han destacado cada vez más, dado el nivel de seguridad en los lugares públicos y privados, también implementado en dispositivos móviles. Del mismo modo, pueden servir como clave para acceder a las transacciones financieras, mientras que en las redes sociales, detecta la presencia del usuario o de sus amigos en las fotos.
En relación con el mercado de marketing, una investigación desarrollada por Image Intelligence señaló que 3 mil millones imágenes son compartidas diariamente por las redes sociales y el 80% contienen indicaciones que se refieren a empresas específicas, pero sin referencias textuales. Las empresas especializadas en marketing ofrecen servicios de monitorización y gestión de presencia en tiempo real. Con la tecnología de visión por ordenador, la precisión en la identificación de imágenes alcanza el 99%.
En los servicios públicos su uso cubre la seguridad del sitio mediante el monitoreo de cámaras, el tráfico de vehículos a través de imágenes estereoscópicas que hacen que el sistema de visión sea eficiente.
En el proceso de producción, las empresas de diferentes ramas emplean la visión computacional como un instrumento de control de calidad. En cualquier sucursal, el software más avanzado asociado con la capacidad de procesamiento cada vez mayor del hardware aumenta el uso de la visión computacional.
Los sistemas de monitorización permiten el reconocimiento de estándares predefinidos y señalan fallas que no serían identificables al mirar a un empleado en la línea de producción. En el mismo contexto, aplicado al control de inventario es el proyecto de automatización de reemplazo. Un inventario en tiempo real y control de ventas permite que la tecnología controle las operaciones de una empresa determinada, aumentando así sus beneficios. Existen otras aplicaciones en el campo de la medicina, la educación y el comercio electrónico.
Conclusiones
El presente estudio trató de dilucidar qué es el aprendizaje profundo y de señalar sus aplicaciones en el mundo actual. Las técnicas de aprendizaje profundo continúan avanzando en particular con el uso de múltiples capas. Sin embargo, todavía hay limitaciones en el uso de redes neuronales profundas, dado que sólo son una manera de aprender varios cambios que se implementarán en el vector de entrada. Cambios proporcionados por una serie de parámetros que se actualizan en el período de formación.
Es innegable que la inteligencia artificial es una realidad más cercana, pero carece de un largo camino por seguir. La aceptación del aprendizaje profundo en diversos campos del conocimiento permite a la sociedad, en su conjunto, beneficiarse de las maravillas de la tecnología moderna.
En relación con la inteligencia artificial, se verifica que esta tecnología capaz de aprender, aunque muy importante tiene una naturaleza lineal y no moldeable a los seres humanos, que representa un gran diferencial y esencial para algunas áreas de conocimiento, el Eso todavía no se puede implementar en el aprendizaje profundo.
De cualquier manera, el uso de los métodos de aprendizaje profundo permitirá a las máquinas ayudar a la sociedad en diversas actividades como se demuestra, ampliando la capacidad cognitiva del hombre y un desarrollo aún mayor en estas áreas del conocimiento.
REFERENCIAS BIBLIOGRÁFICAS
ALIGER. Saiba o que é visão computacional e como ela pode ser usada. 2018. Disponível em: https://www.aliger.com.br/blog/saiba-o-que-e-visao-computacional/
BITTENCOURT, Guilherme. Breve história da Inteligência Artificial. 2001
CARVALHO, André Ponce de L. Redes Neurais Artificiais. Disponível em: http://conteudo.icmc.usp.br/pessoas/andre/research/neural/
CHUNG, J; GULCEHE, C; CHO, K; BENGIO, Y. Gated feedback recurrent neural networks. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, volume 37 of ICML, pages 2067–2075. 2015
CULTURA ANALITICA. Entenda o que é deep learning e como funciona. Disponível em: https://culturaanalitica.com.br/deep-learning-oquee-como-funciona/cultura-analitica-redes-neurais-simples-profundas/
DENG, Jia et al. Imagenet: Um banco de dados de imagens hierárquicas em grande escala. In: 2009 Conferência IEEE sobre visão computacional e reconhecimento de padrões . Ieee,. p. 248-255. 2009
DETTMERS, Tim. Aprendizagem profunda em poucas palavras: Historia e Treinamento. Disponível em: https://devblogs.nvidia.com/deep-learning-nutshell-history-training/
FUKUSHIMA, Kunihiko. Neocognitron: Um modelo de rede neural auto-organizada para um mecanismo de reconhecimento de padrões não afetado pela mudança de posição. Cibernética biológica , v. 36, n. 4, p. 193-202, 1980.
GARTNER. Gartner diz que a AI Technologies estará em quase todos os novos produtos de software até 2020. Disponível em: https://www.gartner.com/en/newsroom/press-releases/2017-07-18-gartner-says-ai-technologies-will-be-in-almost-every-new-software-product-by-2020
GOODFELLOW, I; BENGIOo, Y; COURVILLE, A. Deep Learning. MIT Press. Disponível em: http://www.deeplearningbook.org
GRAVES, A. Sequence transduction with recurrent neural networks. arXiv preprint arXiv:1211.3711, 2012.
HOCHREITER, Sepp. O problema do gradiente de fuga durante a aprendizagem de redes neurais recorrentes e soluções de problemas. Revista Internacional de Incerteza, Fuzziness and Knowledge-Based Systems , v. 6, n. 02, p. 107-116, 1998.
HEBB, Donald O. The organization of behavior; a neuropsycholocigal theory. A Wiley Book in Clinical Psychology., p. 62-78, 1949.
HINTON, Geoffrey E; SALAKHUTDINOV, Ruslan R. Reduzindo a dimensionalidade dos dados com redes neurais. ciência , v. 313, n. 5786, p. 504-507, 2006.
HOCHREITER, Sepp; SCHMIDHUBER, Jürgen. Longa memória de curto prazo. Computação Neural, v. 9, n. 8, p. 1735-1780, 1997.
INTRODUCTION to artificial neural networks, Proceedings Electronic Technology Directions to the Year 2000, Adelaide, SA, Australia, 1995, pp. 36-62. Disponível em: https://ieeexplore.ieee.org/document/403491
KOROLEV, Dmitrii. Set of different neural nets. Neuron network. Deep learning. Cognitive technology concept. Vector illustration Disponível em: https://stock.adobe.com/br/images/set-of-different-neural-nets-neuron-network-deep-learning-cognitive-technology-concept-vector-illustration/145011568
LIU, C.; CAO, Y; LUO Y; CHEN, G; VOKKARANE, V, MA, Y; CHEN, S; HOU, P. A new Deep Learning-based food recognition system for dietary assessment on an edge computing service infrastructure. IEEE Transactions on Services Computing, PP(99):1–13. 2017
LORENA, Ana Carolina; DE CARVALHO, André CPLF. Uma introdução às support vector machines. Revista de Informática Teórica e Aplicada, v. 14, n. 2, p. 43-67, 2007.
MARVIN, Minsky; SEYMOUR, Papert. Perceptrons. 1969. Disponível em: http://134.208.26.59/math/AI/AI.pdf
MCCULLOCH, Warren S; PITTS, Walter. Um cálculo lógico das idéias imanentes na atividade nervosa. O boletim de biofísica matemática, v. 5, n. 4, p. 115-133, 1943.
NIELSEN, Michael. How the backpropagation algorithm works. 2018. Disponível em: http://neuralnetworksanddeeplearning.com/chap2.html
NIPS. 2009. Disponível em: http://media.nips.cc/Conferences/2009/NIPS-2009-Workshop-Book.pdf
PANG, Y; SUN, M; JIANG, X; LI, X.. Convolution in convolution for network in network. IEEE Transactions on Neural Networks and Learning Systems, PP(99):1–11. 2017
SANTANA, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponível em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
UDACITY. Conheça 8 aplicações de Deep Learning no mercado. Disponível em: https://br.udacity.com/blog/post/aplicacoes-deep-learning-mercado
YANG, S; LUO, P; LOY, C.C; TANG, X. From facial parts responses to face detection: A Deep Learning approach. In Proceedings of 2015 IEEE International Conference on Computer Vision (ICCV), pages 3676–3684. 2015
- Liu, C., Cao, Y., Luo, Y., Chen, G., Vokkarane, V., Ma, Y., Chen, S., and Hou, P. (2017). A new Deep Learning-based food recognition system for dietary assessment on an edge computing service infrastructure. IEEE Transactions on Services Computing, PP(99):1–13.
- Yang, S., Luo; P., Loy, C.-C; Tang, X. From facial parts responses to face detection: A Deep Learning approach. In Proceedings of 2015 IEEE International Conference on Computer Vision (ICCV), p. 3676
- Chung, J; Gulcehre, C; Cho, K; Bengio, Y. Gated feedback recurrent neural networks. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, volume 37 of ICML, p. 2069
- PANG, Y; Sun, M., Jiang, X., and Li, X. (2017). Convolution in convolution for network in network. IEEE Transactions on Neural Networks and Learning Systems, PP(99):5. 2017 ↑
- Goodfellow, I., Bengio, Y., and Courville, A. Deep Learning. MIT Press. http://www.deeplearningbook.org.
- GRAVES, A. Sequence transduction with recurrent neural networks. arXiv preprint arXiv:1211.3711, 2012.
- GARTNER. Gartner diz que a AI Technologies estará em quase todos os novos produtos de software até 2020. Disponível em: https://www.gartner.com/en/newsroom/press-releases/2017-07-18-gartner-says-ai-technologies-will-be-in-almost-every-new-software-product-by-2020
- MCCULLOCH, Warren S; PITTS, Walter. Um cálculo lógico das idéias imanentes na atividade nervosa. O boletim de biofísica matemática , v. 5, n. 4, p. 115-133, 1943.
- HEBB, Donald O. The organization of behavior; a neuropsycholocigal theory. A Wiley Book in Clinical Psychology., p. 62-78, 1949.
- BITTENCOURT, Guilherme. Breve história da Inteligência Artificial. 2001.p. 24
- Idbiem p. 25
- MARVIN, Minsky; SEYMOUR, Papert. Perceptrons. 1969. Disponível em: http://134.208.26.59/math/AI/AI.pdf
- Introduction to artificial neural networks," Proceedings Electronic Technology Directions to the Year 2000, Adelaide, SA, Australia, 1995, pp. 36-62. Disponível em: https://ieeexplore.ieee.org/document/403491
- BITTENCOURT, Guilherme op cit. p. 32
- NIELSEN, Michael. How the backpropagation algorithm works. 2018. Disponível em: http://neuralnetworksanddeeplearning.com/chap2.html
- HINTON, Geoffrey E; SALAKHUTDINOV, Ruslan R. Reduzindo a dimensionalidade dos dados com redes neurais. ciência , v. 313, n. 5786, p. 504-507, 2006.
- NIPS. 2009. Disponível em: http://media.nips.cc/Conferences/2009/NIPS-2009-Workshop-Book.pdf
- Santana, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponivel em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
- SANTANA, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponível em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
- idem
- UDACITY. Conheça 8 aplicações de Deep Learning no mercado. Disponível em: https://br.udacity.com/blog/post/aplicacoes-deep-learning-mercado
- Dettmers, Tim. Aprendizagem profunda em poucas palavras: Historia e Treinamento. Disponível em: https://devblogs.nvidia.com/deep-learning-nutshell-history-training/
- FUKUSHIMA, Kunihiko. Neocognitron: Um modelo de rede neural auto-organizada para um mecanismo de reconhecimento de padrões não afetado pela mudança de posição. Cibernética biológica , v. 36, n. 4, p. 193-202, 1980.
- LORENA, Ana Carolina; DE CARVALHO, André CPLF. Uma introdução às support vector machines. Revista de Informática Teórica e Aplicada, v. 14, n. 2, p. 43-67, 2007.
- HOCHREITER, Sepp; SCHMIDHUBER, Jürgen. Longa memória de curto prazo. Computação Neural, v. 9, n. 8, p. 1735-1780, 1997.
- HOCHREITER, Sepp. O problema do gradiente de fuga durante a aprendizagem de redes neurais recorrentes e soluções de problemas. Revista Internacional de Incerteza, Fuzziness and Knowledge-Based Systems , v. 6, n. 02, p. 107-116, 1998.
- DENG, Jia et al. Imagenet: Um banco de dados de imagens hierárquicas em grande escala. In: 2009 Conferência IEEE sobre visão computacional e reconhecimento de padrões . Ieee, 2009. p. 248-255.
- MCCULLOCH, Warren S.; PITTS, Walter. Um cálculo lógico das idéias imanentes na atividade nervosa. O boletim de biofísica matemática , v. 5, n. 4, p. 115-133, 1943.
- SANTANA, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponivel em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
- ALIGER. Saiba o que é visão computacional e como ela pode ser usada. 2018. Disponível em: https://www.aliger.com.br/blog/saiba-o-que-e-visao-computacional/
[1] Bachelor of Business Administration.
Presentado: mayo, 2019
Aprobado: mayo, 2019