ARTIGO ORIGINAL
CHAGAS, Edgar Thiago De Oliveira [1]
CHAGAS, Edgar Thiago De Oliveira. Deep Learning e suas aplicações na atualidade. Revista Científica Multidisciplinar Núcleo do Conhecimento. Ano 04, Ed. 05, Vol. 04, pp. 05-26 Maio de 2019. ISSN: 2448-0959, Link de acesso: https://www.nucleodoconhecimento.com.br/administracao/deep-learning
RESUMO
A inteligência artificial já não é enredo para filmes de ficção. As pesquisas neste campo aumentam a cada dia e proporcionam novas descobertas sobre o aprendizado das máquinas (Machine Learning). Os Métodos de Aprendizado Profundo, também conhecidos como Deep Learning são atualmente utilizados em muitas frentes como o reconhecimento facial nas redes sociais, nos carros automatizados e até mesmo em alguns diagnósticos no campo da Medicina. O Deep Learning permite que modelos computacionais compostos de inúmeras camadas de processamento possam “aprender” representações de dados com diversos níveis de abstração. Esses métodos melhoraram o reconhecimento de fala, de objetos visuais, detecção de objetos, dentre possibilidades. Contudo, essa tecnologia ainda é pouco conhecida e, o propósito desse estudo é esclarecer como funciona o Deep Learning e demonstrar suas aplicações atuais. De certo, com a disseminação desses conhecimentos, o aprendizado profundo pode, num futuro próximo, apresentar outras aplicações, ainda mais importantes para toda a humanidade.
Palavras-chave: Deep Learning, Aprendizado de Maquina, IA, Machine Learning, Inteligência.
INTRODUÇÃO
Entende-se o aprendizado profundo como um ramo do Machine Learning (aprendizado de máquina), o qual é baseado em um grupo de algoritmos que buscam moldar abstrações de alto nível de dados utilizando-se de um grafo profundo com diversas camadas de processamento, compostas por diversas alterações lineares e não lineares.
O Deep Learning trabalha o sistema do computador para realizar tarefas como reconhecimento de fala, identificação de imagem e realizar projeções. Ao invés de organizar as informações para atuarem através de equações predeterminadas, esse aprendizado determina padrões básicos dessas informações e ensina os computadores a desenvolver-se através da identificação dos padrões em camadas de processamento.
Essa espécie de aprendizagem é um ramo abrangente dos métodos de Machine Learning com fundamento na aprendizagem de representações de informações. Neste sentido, o Deep Learning é um conjunto de algoritmos de learning machine que tentar integrar vários níveis, os quais são modelos estatísticos reconhecidos que correspondem a níveis variados de definições. Os níveis inferiores ajudam a definir muitas noções dos níveis superiores.
São inúmeras as pesquisas atuais nessa área de inteligência artificial. A melhoria nas técnicas de Deep Learning têm implementado melhorias na capacidade de computadores em compreender o que lhe é pedido. As pesquisas nesse âmbito procuram promover melhores representações e elaborar modelos para identificar essas representações a partir de informações não rotuladas em grande escala, algumas como base em achados da neurociência e na interpretação do processamento de dados e padrões de comunicação no sistema nervoso. Desde 2006, essa espécie de aprendizagem surgiu como um novo ramo de pesquisa de aprendizagem de máquina[2].
Recentemente, foram desenvolvidas novas técnicas a partir de Deep Learning, as quais têm impactado em diversos estudos sobre processamento de sinais e identificação de padrões. Nota-se um leque de novos comandos problemáticos que podem ser solucionados através dessas técnicas, incluindo pontos-chave do Machine Learning e da inteligência artificial.
Há uma grande atenção da mídia, segundo Yang et al[3], sobre os avanços atingidos nessa área. Grandes organizações do ramo tecnológico têm aplicado muitos investimentos nas pesquisas de Deep Learning e suas novas aplicações.
O Deep Learning abrange a aprendizagem em diversos níveis de representação e intangibilidade que auxiliam no processo de compreensão das informações, das imagens, dos sons e dos textos.
Dentre as exposições disponíveis sobre o aprendizado profundo é possível identificar dois pontos marcantes. A primeira demonstra que são modelos formados por inúmeras camadas ou etapas de processamento de dados não linear e também são práticas de aprendizagem supervisionada ou não, da representação de atribuições em camadas seguidamente superiores e intangíveis.
Compreende-se que o Deep Learning está nas junções entre aos ramos de pesquisa de redes neurais, AI, modelagem gráfica, identificação e otimização de padrões e processamento de sinais. A atenção conferida ao aprendizado profundo deve-se ao aperfeiçoamento da habilidade de processamento de chips, ao considerável aumento do tamanho das informações utilizadas para treinamento e os avanços recentes nos estudos em Machine Learning e processamento de sinais.
Esse progresso permitiu que as práticas de Deep Learning pudessem explorar, de forma eficaz, aplicabilidades complexas e não lineares, identificassem representações de recursos distribuídos e hierárquicos, bem como possibilitar a utilização efetiva de informações rotuladas e não rotuladas.[4]
O Deep Learning refere-se a uma classe abrangente métodos e projetos de Machine Learning, as quais reúnem a característica de utilizar muitas camadas de dados processados não lineares de natureza hierárquica. Em razão da utilização desses métodos e projetos, pode-se classificar grande parte dos estudos nessa esfera em três conjuntos principais, de acordo com Pang et al[5], quais sejam as redes profundas para aprendizagem não supervisionada; supervisionada e híbridas.
As redes profundas para aprendizagem não supervisionada se dispõem a apreender a correlação de alta sequencia das informações analisadas ou identificáveis para verificação ou associação de padrões quando não houver dados sobre os estereótipos das classes disponíveis no banco de dados. Aprendizagem de atribuição ou representação não supervisionada refere-se às redes profundas. Igualmente, pode procurar a atribuição de distribuições estatísticas agrupadas dos dados visíveis e suas classes relacionadas quando disponíveis, podendo abordadas como parte dos dados visíveis.
As redes neurais profundas para aprendizagem supervisionada devem fornecer discriminação para classificar os padrões, geralmente individualizando as distribuições posteriores de classes vinculadas as informações visíveis, as quais estão sempre disponíveis para essa aprendizagem supervisionada, também denominada como redes profundas discriminativas.
Já as redes profundas híbridas, ressaltam- se pela discriminação identificada com os resultados de redes profundas generativas ou não supervisionada, o que pode ser atingido através de um aprimoramento e/ou regularização das redes profundas supervisionadas. Suas atribuições também podem ser alcançadas quando as diretrizes discriminativas para a aprendizagem supervisionada são utilizadas para avaliar os padrões em qualquer rede profunda generativa ou não supervisionada[6].
As redes profundas e recorrentes são modelos que apresentam um alto desempenho em questões de identificação de padrões questionáveis em ivão e fala[7]. Apesar de sue poder de representação, a grande dificuldade em moldar as redes neurais profundas com uso genérico persiste até os dias atuais. Em relação as redes neurais recorrentes, estudos de Hinton et al[8] deram inicio a moldagem em camadas.
O presente estudo visa esclarecer o progresso do Deep Learning e suas aplicações conforme as pesquisas mais recentes. Para tal, será efetuada um pesquisa descritiva qualitativa, com a utilização de livros, teses, artigos e websites para conceituar os avanços na área de inteligência artificial e em especial na aprendizagem profunda.
Há um interesse crescente pelo Machine Learning desde a última década, haja vista que há uma interação cada vez maior entre os aplicativos, sejam de dispositivos móveis ou de computadores, com os indivíduos, através de programas para detecção de spam, reconhecimento em fotos nas redes sociais, smartphones com reconhecimento facial, dentre outras aplicações. De acordo com Gartner[9] todos os programas coorporativos terão alguma função vinculada a Machine Learning até o ano de 2020. Tais elementos buscam justificar a elaboração deste estudo.
DESENVOLVIMENTO HISTÓRICO DO APRENDIZADO PROFUNDO
A inteligência artificial não é uma descoberta recente. Provem da década de 1950, mas apesar da evolução de sua estrutura, faltavam alguns aspectos que dessem credibilidade. Um desses aspectos é o volume de dados, originado em grande variedade e velocidade, possibilitando a criação de padrões com altos níveis de precisão. Contudo, um ponto relevante versava sobre o modo de processamento de grandes modelos de Machine Learning com grandes quantidades de informações, pois os computadores não conseguiam efetuar tal ação.
Nesse momento, fora identificado o segundo aspecto que se refere a Programação Paralela em GPUs. As unidades de processamento gráfico, que possibilitam a realização de operações matemáticas de modo paralelo, especialmente aquelas com matrizes e vetores, os quais estão presentes em modelos de redes artificiais, permitiram a evolução atual, isto é, o somatório de Big Data (grande volume de dados); processamento paralelo e os modelos de Machine Learning apresentam como resultado a inteligência artificial.
A unidade básica de uma rede neural artificial é um neurônio matemático, também denominado nó, baseado no neurônio biológico. As ligações entre esses neurônios matemáticos são relacionadas com àquelas dos cérebros biológicos, e principalmente no modo com essas associações se desenvolvem ao longo do tempo, denominado “treinamento”.
Entre a segunda metade da década de 80 e o inicio da década de 90, diversos avanços relevantes na estrutura das redes artificiais aconteceram. Entretanto, a quantidade de tempo e informações necessárias para atingir bons resultados procrastinou a adoção, afetando o interesse sobre a inteligência artificial.
No começo dos anos 2000, o poder da computação expandiu-se e o mercado vivenciou um “boom” de técnicas computacionais que não eram possíveis antes. Foi quando o Deep Learning surgiu do crescimento computacional grandioso daquela época como mecanismo essencial de elaboração de sistemas de Inteligência Artificial, ganhando diversas competições de Machine Learning. O interesse pela aprendizagem profunda continua crescendo até os dias atuais e diversas soluções comerciais emergem a todo o momento.
Ao longo do tempo foram criadas diversas pesquisas visando simular o funcionamento cerebral, especialmente durante o processo de aprendizagem para criar sistemas inteligentes que pudessem recriar tarefas como classificação e reconhecimento de padrões, dentre outras atividades. As conclusões desses estudos geraram o modelo do neurônio artificial, colocado posteriormente em uma rede interconectada denominada rede neural.
Em 1943, Warren McCulloch, neurofisiologista, e Walter Pitts, matemático, criaram um rede neural simples utilizando circuitos elétrico e elaboraram um modelo de computador para redes neurais com base em conceitos matemáticos e algoritmos chamados threshold logic ou lógica de limiar, o qual permitiu pesquisas sobre a rede neural dividida em duas vertentes: com foco nos processo biológicos cerebrais e outra com foco na aplicação dessas redes neurais voltadas a inteligência artificial.[10]
Donald Hebb[11], em 1949, escreveu uma obra onde relatava que os circuitos neurais se fortalecem quanto mais forem utilizados, como essência da aprendizagem. Com o avanço dos computadores na década de 1950, a ideia de uma rede neural ganhava força e Nathanial Rochester[12] dos laboratórios de estudo da IBM tentou constituir uma, contudo não logrou êxito.
O projeto de pesquisa de verão de Dartmouth[13] sobre inteligência artificial, em 1956, impulsionou as redes neurais, bem como a inteligência artificial, incentivando as pesquisas nessa área em relação ao processamento neural. Nos anos que se seguiram, John Von Neumann imitou funções simples de neurônios com tubos de vácuo ou reles telegráficos, enquanto Frank Rosenblatt iniciou o projeto Perceptron, analisando o funcionamento do olho de uma mosca. O resultado dessa pesquisa foi um hardware, que a rede neural mais antiga utilizada até os dias atuais. Entretanto, o Perceptron é muito limitado, o que foi comprovado por Marvin e Papert[14]
Figura 1: Estrutura de Redes Neurais
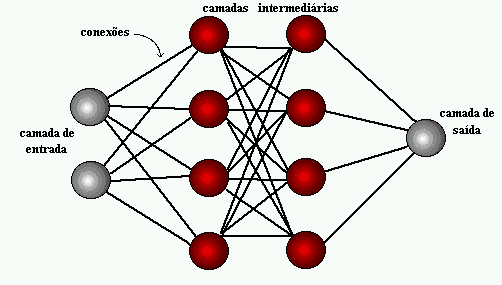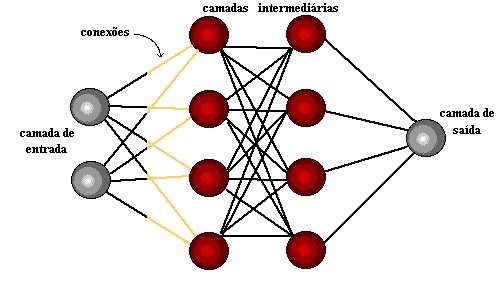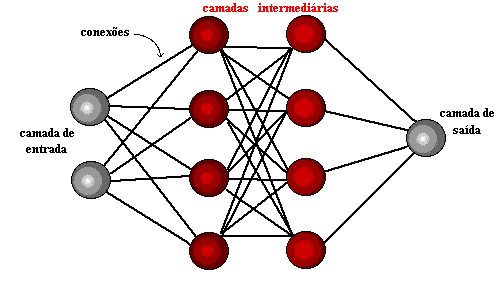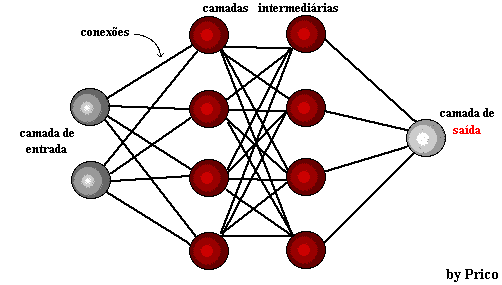
Alguns anos depois, em 1959, Bernard Widrow e Marcian Hoff, desenvolveram dois modelos chamados “adaline” e “madaline”. A nomenclatura é oriunda da utilização de múltiplos elementos: ADAptive LINear. Adaline foi criado para identificar padrões binários de forma a realizar previsões sobre próximo bit, enquanto “Madaline” foi a primeira rede neural aplicada a um problema real, utilizando-se um filtro adaptativo. O sistema ainda está em uso, mas apenas comercial.[15]
Os progressos atingidos anteriormente levaram a crer que o potencial das redes neurais estava limitado à eletrônica. Questionava-se sobre o impacto que as “maquinas inteligentes” teriam sobre o homem e a sociedade como um todo.
O debate sobre como a Inteligência Artificial afetaria o homem, levantaram criticas sobre as pesquisas em redes neurais o que causou uma redução dos financiamentos e, consequentemente, dos estudos na área, o que se manteve até 1981.
No ano seguinte, diversos eventos reacenderam o interesse por esse campo. John Hopfield da Caltech apresentou uma abordagem para criar dispositivos úteis, demonstrando suas atribuições[16]. Já em 1985, O Instituto Americano de Física iniciou uma reunião anual, denominada Redes Neurais para Computação. Em 1986, a mídia começou a noticiar as redes neurais de várias camadas, sendo que três pesquisadores apresentaram ideias similares, denominadas de redes Backpropagation, pois distribuem falhas de identificação de padrões em toda a rede.
As redes híbridas possuíam apenas duas camadas, enquanto as redes de Backpropagation[17] apresentam muitas, de forma que essa rede retém informações de modo mais lento, pois precisam de milhares de iterações para aprender, mas também apresentam resultados mais precisos. Já em 1987, houve a primeira Conferência Internacional sobre Redes Neurais do Institute of Electrical and Electronic Engineer’s (IEEE).
No ano de 1989, cientistas criaram algoritmos que utilizavam-se de redes neurais profundas, mas o tempo de ‘aprendizagem” era muito longo, o que impedia sua aplicação à realidade. Em 1992, Juyang Weng diulga o método Cresceptron para realizar o reconhecimento de objetos 3D a partir de cenas tumultuadas.
Na metade dos anos 2000, o termo Deep Learning ou aprendizagem profunda começa a ser difundido após um artigo de Geoffrey Hinton e Ruslan Salakhutdinov[18], o qual demonstrou como uma rede neural de várias camadas poderia ser previamente treinada, sendo uma camada por vez.
Em 2009, acontece o Workshop de Processamento de sistemas de redes neurais sobre Deep Learning para Reconhecimento de Voz e verifica-se que com um grupo de dados extenso, as redes neurais não precisam de treinamento prévio e os índices de falha caem significativamente[19].
Em 2012, as pesquisas proporcionaram algoritmos de identificação de padrões artificiais com desempenho humano em algumas tarefas. E o algoritmo do Google identifica felinos.
Em 2015, o Facebook utiliza-se do Deep Learning para marcar e reconhecer automaticamente os usuários em fotografias. Os algoritmos executam tarefas de reconhecimento facial utilizando redes profundas. No ano de 2017, houve a adoção em grande escala do aprendizado profundo em várias aplicações empresariais e dispositivos móveis, além do progresso nas pesquisas[20].
O compromisso do Deep Learning é demonstrar que um conjunto de dados bastante extenso, processadores rápidos e um algoritmo bastante sofisticado, possibilita que os computadores possam realizar tarefas como reconhecer imagens e voz, dentre outras possibilidades.
As pesquisas sobre as redes neurais têm ganhado destaque com promissoras atribuições apresentadas pelos modelos de redes neurais criados, devido as inovações tecnológicas recentes de implementação que permitem desenvolver audaciosas estruturas neurais paralelas em hardwares, atingindo performances satisfatórias destes sistemas, com desempenho superior aos sistemas convencionais, inclusive. A evolução das redes neurais é o Deep Learning.
DEEP LEARNING
Cabe, inicialmente, diferenciar a inteligência artificial, Machine Learning e o Deep Learning.
Figura 2: Inteligência artificial, Machine Learning e Deep Learning
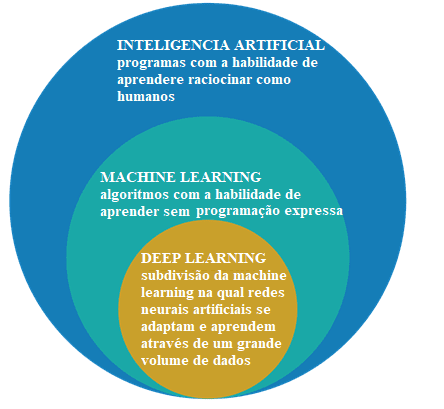
O campo de estudo da inteligência artificial é a pesquisa e o projeto de fontes inteligentes, isto é, um sistema que consiga tomar decisões baseado em uma característica considerada inteligente. Na inteligência artificial existem diversos métodos que modelam essa característica e dentre elas esta a esfera de Machine Learning, onde as decisões são tomadas (inteligência) com base em exemplos e não uma programação determinada.
Os algoritmos de Machine Learning necessitam de informações para retirar características e aprendizados que podem ser utilizados para tomar decisões futuras. Já o Deep Learning é um subgrupo das técnicas de Machine Learning, que geralmente utilizam-se de redes neurais profundas e precisam de um grande volume de informações para o treinamento[21].
De acordo com Santana[22] existem algumas diferenças entre as técnicas de Machine Learning e os métodos de Deep Learning, sendo que os principais são a necessidade e o impacto do volume de dados, o poder computacional e a flexibilidade na modelagem dos problemas.
A Machine Learning precisa de dados para identificar padrões, contudo existem duas questões em relação aos dados que referem-se a dimensionalidade e a estagnação da performance ao introduzir mais dados além do limite comportado. Verifica-se que há uma redução no desempenho significativa quando isso ocorre. Em relação a dimensionalidade ocorre o mesmo, pois são muitas informações para detectar, através das técnicas clássicas a dimensão do problema.
Figura 3: Comparação entre deep learning com outros algoritmos em relação a quantidade de dados.
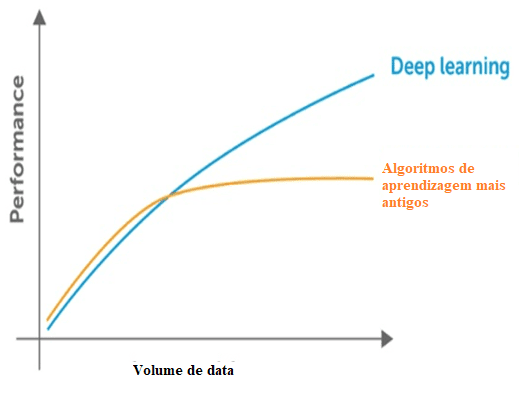
As técnicas clássicas também apresentam um ponto de saturação em relação a quantidade de dados, isto é, possuem um limite máximo para extrair as informações, o que não ocorre com o deep learning, criados para trabalhar com um grande volume de dados.
Em relação ao poder computacional para deep learning, suas estrutuas são complexas e necessitam de um grande volume de dados para seu treinamento, o que demonstra sua dependência de uma grande poder computacional para implementar essas práticas. Apesar de outras práticas clássicas precisarem de muito poder computacional como CPU, as técnicas de Deep Learning estão superiores.
As pesquisas relacionadas a computação paralela e o uso de GPUs com CUDA – Compute Unified Device Architecture ou Arquitetura de Dispositivo de Computação Unificada deram inicio ao Deep Learning, pois era algo inviável com a utilização de um simples CPU.
Em uma comparação com o treinamento de uma Rede Neural profunda ou deep learning com a utilização de uma CPU, verifica-se que seria impossível obter resultados satisfatórios mesmo com um treinamento prolongado.
O Deep Learning, também denominado aprendizagem profunda é uma parte do Machine Learning ou aprendizagem de Máquina, que aplica algoritmos para processar dados e reproduzir o processamento realizado pelo cérebro humano.
A aprendizagem profunda utiliza camadas de neurônios matemáticos para processar dados, identificar a fala e reconhecer objetos. Os dados são transmitidos através de cada camada, com a saída da camada anterior concedendo entrada para a próxima camada. A primeira camada em uma rede é denominada de camada de entrada e a última é a camada de saída. As camadas intermediárias são chamadas de camadas ocultas, sendo que cada camada da rede é formada por um algoritmo simples e uniforme engloba uma espécie de função de ativação.
Figura 4: Rede Neural Simples e Rede Neural Profunda ou Deep Learning
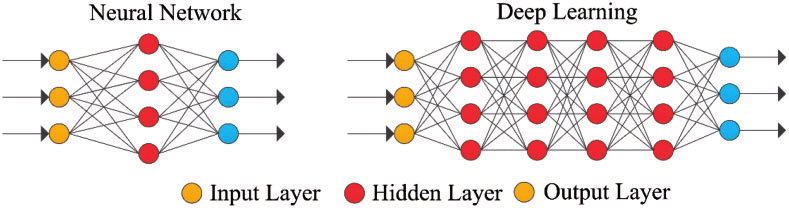
As camadas mais externas em amarelo são as camadas de entrada ou saída e as camadas intermediárias ou ocultas estão em vermelho. O Deep Learning é responsável pelos recentes avanços no âmbito da computação, reconhecimento de fala, processamento de linguagem e identificação auditiva, fundamentando-se na definição de redes neurais artificiais ou sistemas computacionais que reproduzem o modo como o cérebro humano atua.
Outro aspecto do Deep Learning é a extração de recursos, a qual utiliza um algoritmo para criar automaticamente parâmetros relevantes das informações para treinamento, aprendizado e entendimento, uma incumbência do engenheiro de inteligência artificial.
O Deep Learning é uma evolução das Redes Neurais. O interesse na aprendizagem profunda tem crescido gradativamente na mídia e diversas pesquisas na área têm sido divulgadas e sua aplicação chegou aos carros, no diagnóstico de câncer e autismo, dentre outras aplicações[23]
Os primeiros algoritmos de aprendizagem profunda com múltiplas camadas de atribuições não lineares apresentam sua origem em Alexey Grigoryevich Ivakhnenko, o qual desenvolveu o Método do Grupo de Manipulação de Dados e Valentin Grigor’evich Lapa, autor da obra Cybernetics and Forecasting Techniques no ano de 1965.[24]
Ambos usaram modelos finos e profundos com funções de ativação polinomial, averiguados através de métodos estatísticos. Através desses métodos eles selecionavam em cada camada os melhores recursos e transmitiam para a próxima camada, sem utilizar Backpropagation para “treinar” a rede completa, mas utilizaram quadrados mínimos em cada camada, onde as anteriores foram instaladas de forma independente nas camadas posteriores, manualmente.
Figura 5: Estrutura da primeira rede profunda conhecida por Alexey Grigorevich Ivakhnenko
Ao término da década de 1970 ocorreu o inverno de inteligência artificial, uma drástica redução nos financiamentos para pesquisas sobre assunto. O impacto limitou os avanços em Redes Neurais Profundas e Inteligência Artificial.
As primeiras redes neurais convolucionais foram utilizadas por Kunihiko Fukushima, com diversas camadas de agrupamento e convoluções, em 1979. Ele criou uma rede neural artificial, denominada Neocognitron, com um layout hierárquico e multicamadas, o qual possibilitou ao computador identificar padrões visuais. As redes eram similares as versões modernas, com “treinamento” voltado para a estratégia de reforço de ativação periódica em inúmeras camadas. Ademais, o design de Fukushima possibilitou que os recursos mais relevantes fossem adequados manualmente aumentando a importância de determinadas conexões[25].
Muitas diretrizes de Neocognitron ainda estão em uso, como as conexões de cima para baixo e novas práticas de aprendizagem promoveram a concretização de diversas redes neurais. Quando diversos padrões são apresentados ao mesmo tempo, o Modelo de Atenção Seletiva pode separa-los e identificas os padrões individuais, atentando para cada um. Um Neocognitron mais atualizado pode identificar padrões com falta de dados e completar a imagem inserindo as informações que faltam, o que é chamado inferência.
O Backpropagation utilizado para o treinamento de falhas de Deep Learning progrediu a partir de 1970, quando Seppo Linnainmaa escreveu uma tese, inserindo um código FORTRAN para Backpropagation, sem lograr êxito até 1985. Rumelhart, Williams e Hinton demonstraram então o Backpropagation em uma rede neural com representações de distribuição.
Tal descoberta permitiu que o debate sobre AI atingisse a psicologia cognitiva que iniciou os questionamentos sobre a compreensão humana e sua relação com a lógica simbólica, bem como as conexões. Em 1989, Yann LeCun realizou uma demonstração prática de Backpropagation, com a combinação de redes neurais convolucionais para identificar os dígitos escritos.
Nesse período houve novamente uma escassez de financeiamentos para pesquisas neste âmbito, conhecido como segundo inverno da IA, ocorrido entre 1985 e 1990, afetando também as pesquisas em redes neurais e Deep Learning. As expectativas apresentadas por alguns pesquisadores não atingiram o patamar esperado o que irritou profundamente os investidores.
Em 1995, Dana Cortes e Vladimir Vapnik criaram a Support Vector Machine[26] ou máquina de vetor de suporte que era um sistema para mapear e identificar informações similares. O Long Short Term Memory-LSTM para redes neurais periódicas foi elaborado em 1997, por Sepp Hochreiter e Juergen Schmidhuber[27].
O próximo passo na evolução do Deep Learning ocorreu em 1999, quando o processamento de dados e as unidades de processamento de gráficos (GPUs) se tornaram mais rápidos. A utilização de GPUs e seu rápido processamento representou um aumento da velocidade dos computadores. As redes neurais competiam com as máquinas de vetor de suporte. A rede neural era mais lenta que máquina de vetor de suporte, mas obtinham melhores resultados e continuavam evoluindo à medida que mais informações de treinamento eram adicionadas.
No ano 2000, foi identificado um problema chamado Vanishing Gradient. As atribuições aprendidas em camadas mais baixas não eram transmitidas para as camadas superiores Contudo, só ocorria naquelas com métodos de aprendizagem baseados em gradientes. A origem do problema encontrava-se em algumas funções de ativação que reduziam sua entrada afetando a faixa de saída, gerando grandes áreas de entrada mapeadas em uma faixa muito pequena, ocasionando uma gradiente em queda. As soluções implementadas para solucionar a questão foram o pré-treino camada por camada e o desenvolvimento de uma memória longa e de curto prazo[28].
Em 2009, Fei-Fei Li, divulgou o ImageNet[29] com uma base de dados gratuita com mais de 14 milhões de imagens, voltadas para o “treinamento” das redes neurais, apontando como o Big data afetaria o funcionamento do Machine Learning.
A velocidade das GPUs, até o ano de 2011, continuou aumentando permitindo a composição de redes neurais convolucionais sem a necessidade do pré-treino camada por camada. Assim, tornou-se notório que o Deep Learning era vantajoso em termos de eficácia e velocidade.
Nos dias atuais, o processamento de Big Data e a progressão da inteligência artificial são dependentes do Deep Learning, o qual pode elaborar sistemas inteligentes e promover a criação de uma inteligência artificial totalmente autônoma, o que irá gerar impacto em toda a sociedade.
FLEXIVILIDADE DAS REDES NEURAIS E SUAS APLICAÇÕES
Apesar da existência de várias técnicas clássicas, a estrutura de Deep Learning e sua unidade básica, o neurônio é genérico e bem flexível. Fazendo uma comparação com o neurônio humano que proporciona as sinapses podemos identificar algumas correlações entre ambos.
Figura 6: Correlação entre um neurônio humano e um rede neural artificial
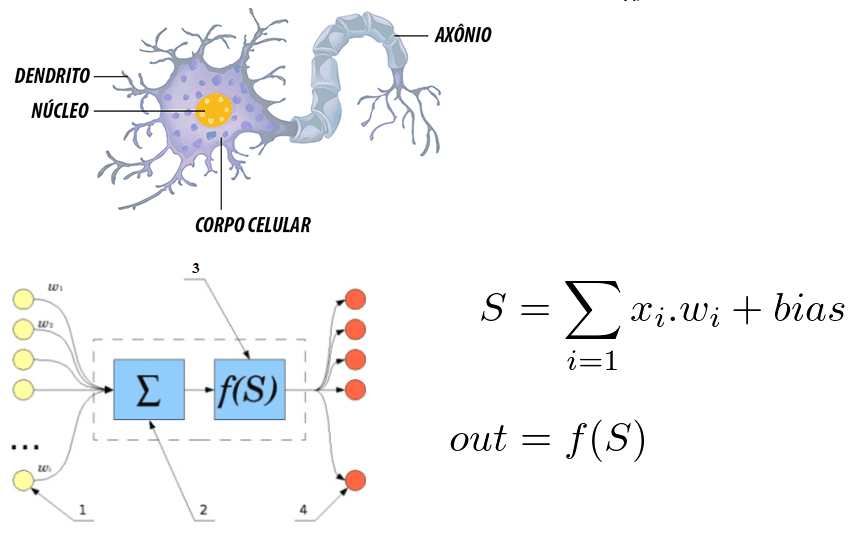
Nota-se que o neurônio é formado pelos dendritos que são os pontos de entrada, um núcleo que representa nas redes neurais artificiais o núcleo de processamento e o ponto de saída que representado pelo axônio. Em ambos os sistemas a informação entra, é processado e sai alterada.
Considerando-o como uma equação matemática, o neurônio reflete o somatório das entradas multiplicado por pesos, sendo que esse valor passa por uma função de ativação. Tal somatório foi realizado por McCulloch e Pitts em 1943[30]
Em relação ao interesse notório sobre Deep Learning nos dias atuais, Santana[31] considera que deve-se a dois fatores quais sejam a quantidade de informações disponíveis e a limitação das técnicas mais antigas além do poder computacional atual para treinar redes complexas. A flexibilidade de interconectar vários neurônios em uma rede mais complexa é o diferencial das estruturas de Deep Learning. Uma rede neural convolucional é amplamente utilizada para reconhecimento facial, detecção de imagens e extração de atribuições.
Uma rede neural convencional é formada por diversas camadas, chamadas Layers. Dependendo da questão a ser solucionada a quantidade de camadas poder variar, podendo ter até centenas de camadas, sendo fatores que influenciam na quantidade a complexidade do problema, tempo e poder computacional
Existem diversas estruturas diferentes com inúmeros propósitos e seu funcionamento também depende da estrutura e todos são baseados em redes neurais.
Figura 7: Exemplos de redes neurais
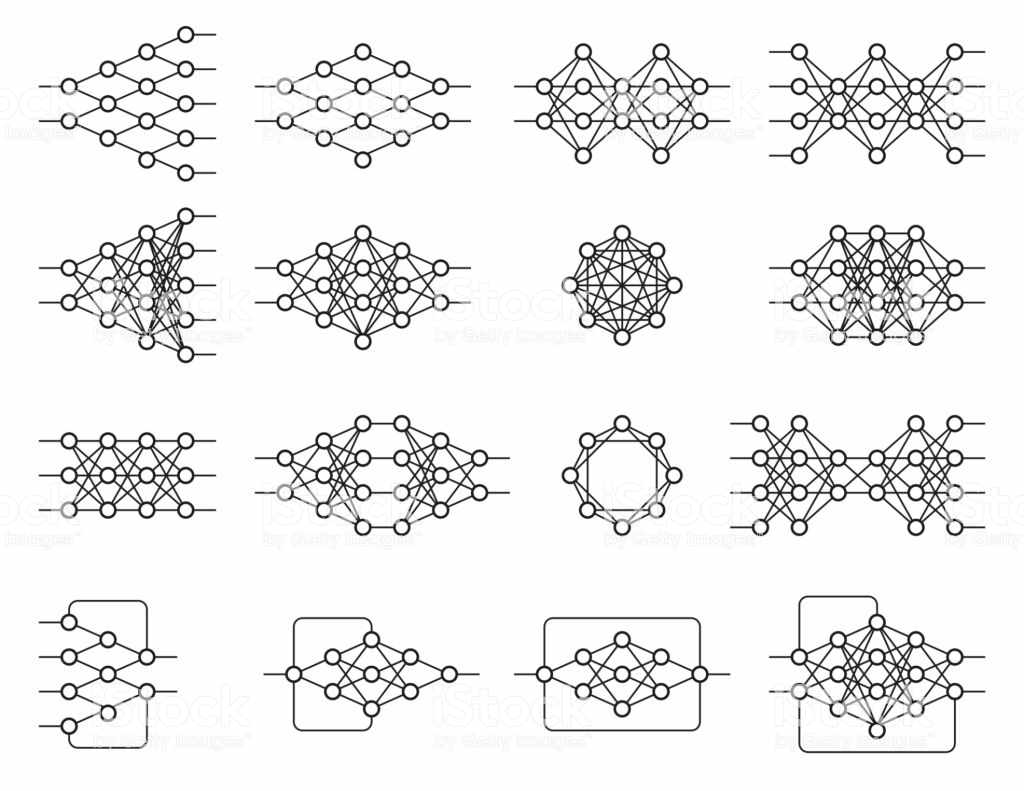
Essa flexibilidade de arquitetura permite que o deep learning solucione diversas questões. O Deep Learning é uma técnica de objetivo geral, contudo os âmbitos que mais avançaram foram: a visão computacional, reconhecimento de fala, processamento de linguagem natural, sistemas de recomendação.
A visão computacional abrange o reconhecimento de objetos, segmentação semântica, principalmente os carros autônomos. Pode-se afirmar que a visão computacional é parte da inteligência artificial e define-se como um conjunto de conhecimento que procura a modelagem artificial da visão humana com o objetivo de imitar suas funções, através do desenvolvimento de softwares e hardwares avançados[32].
Entre as aplicações da visão computacional estão o uso militar, mercado de marketing, segurança, serviços públicos e no processo produtivo. Os veículos autônomos representam o futuro de um transito mais seguro, porém ainda se encontra na fase de testes, pois engloba diversas tecnologias aplicadas a uma função. A visão computacional nesses veículos, uma vez que permite o reconhecimento do trajeto e os obstáculos, aprimorando as rotas.
No âmbito da segurança, os sistemas de reconhecimento facial tem se destacado cada vez mais, dado ao nível de segurança nos locais públicos e privados, implementado também nos dispositivos móveis. Do mesmo modo podem servir como chave de acesso para transações financeiras, enquanto nas redes sociais, detecta a presença do usuário ou seus amigos em fotos.
Em relação ao mercado de marketing, uma pesquisa elaborada por Image Intelligence apontou que 3 bilhões de imagem são compartilhadas diariamente pelas redes sociais e 80% contém indicações que remetem a empresas específicas, mas sem referencias textuais. Empresas de marketing especializadas oferecem o serviço de gestão e monitoramento de presença em tempo real. Com a tecnologia de visão computacional a precisão na identificação de imagens alcança 99%.
Nos serviços públicos sua utilização abrange a segurança do local através do monitoramento de câmeras, o tráfego de veículos através de imagens estereoscópicas que tornam o sistema de visão eficiente.
No processo produtivo, empresas de diferentes ramos empregam a visão computacional como instrumento de controle de qualidade. Em qualquer ramo os softwares mais avançados associados a capacidade de processamento cada vez maior do hardware, aumentam as opções de uso da visão computacional.
Os sistemas de monitoramento permitem o reconhecimento de padrões preestabelecidos, além de apontar falhas que não seriam identificáveis ao olhar de um funcionário na linha de produção. No mesmo contexto, aplicado ao controle de estoque está o projeto de automação de reposição. Um controle de estoque e vendas em tempo real possibilita através da tecnologia o controle das operações de determinada empresa aumentando, consequentemente, seus lucros. Existem outras aplicações no campo da medicina, da educação e comércio eletrônico.
CONCLUSÕES
O presente estudo procurou elucidar o que é o Deep Learning e apontar suas aplicações no mundo atual. As técnicas de aprendizagem profunda continuam progredindo em especial com a utilização de múltiplas camadas. Contudo, ainda existem limitações na utilização de redes neurais profunda, haja vista que são apenas uma forma de aprender diversas mudanças a serem implementadas ao vetor de entrada. Alterações proporcionadas por uma gama de parâmetros que são atualizados no período de treinamento.
É inegável que a inteligência artificial é uma realidade mais próxima, mas falta um longo caminho a percorrer. A aceitação do aprendizado profundo em variados campos de conhecimento permite que a sociedade, como um todo, se beneficie das maravilhas da tecnologia moderna.
Em relação à inteligência artificial, verifica-se que essa tecnologia capaz de aprender, apesar de muito importante tem um caráter linear e não moldável como dos seres humanos, o que representa um grande diferencial e essencial para algumas áreas de conhecimento, o que ainda não pode ser implementado na aprendizagem profunda.
De qualquer forma, a utilização dos métodos de deep learning possibilitará às maquinas auxiliarem a sociedade em diversas atividades como demonstrado, ampliando a capacidade cognitiva do homem e um desenvolvimento ainda maior nessas áreas de conhecimento.
REFERÊNCIAS BIBLIOGRÁFICAS
ALIGER. Saiba o que é visão computacional e como ela pode ser usada. 2018. Disponível em: https://www.aliger.com.br/blog/saiba-o-que-e-visao-computacional/
BITTENCOURT, Guilherme. Breve história da Inteligência Artificial. 2001
CARVALHO, André Ponce de L. Redes Neurais Artificiais. Disponível em: http://conteudo.icmc.usp.br/pessoas/andre/research/neural/
CHUNG, J; GULCEHE, C; CHO, K; BENGIO, Y. Gated feedback recurrent neural networks. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, volume 37 of ICML, pages 2067–2075. 2015
CULTURA ANALITICA. Entenda o que é deep learning e como funciona. Disponível em: https://culturaanalitica.com.br/deep-learning-oquee-como-funciona/cultura-analitica-redes-neurais-simples-profundas/
DENG, Jia et al. Imagenet: Um banco de dados de imagens hierárquicas em grande escala. In: 2009 Conferência IEEE sobre visão computacional e reconhecimento de padrões . Ieee,. p. 248-255. 2009
DETTMERS, Tim. Aprendizagem profunda em poucas palavras: Historia e Treinamento. Disponível em: https://devblogs.nvidia.com/deep-learning-nutshell-history-training/
FUKUSHIMA, Kunihiko. Neocognitron: Um modelo de rede neural auto-organizada para um mecanismo de reconhecimento de padrões não afetado pela mudança de posição. Cibernética biológica , v. 36, n. 4, p. 193-202, 1980.
GARTNER. Gartner diz que a AI Technologies estará em quase todos os novos produtos de software até 2020. Disponível em: https://www.gartner.com/en/newsroom/press-releases/2017-07-18-gartner-says-ai-technologies-will-be-in-almost-every-new-software-product-by-2020
GOODFELLOW, I; BENGIOo, Y; COURVILLE, A. Deep Learning. MIT Press. Disponível em: http://www.deeplearningbook.org
GRAVES, A. Sequence transduction with recurrent neural networks. arXiv preprint arXiv:1211.3711, 2012.
HOCHREITER, Sepp. O problema do gradiente de fuga durante a aprendizagem de redes neurais recorrentes e soluções de problemas. Revista Internacional de Incerteza, Fuzziness and Knowledge-Based Systems , v. 6, n. 02, p. 107-116, 1998.
HEBB, Donald O. The organization of behavior; a neuropsycholocigal theory. A Wiley Book in Clinical Psychology., p. 62-78, 1949.
HINTON, Geoffrey E; SALAKHUTDINOV, Ruslan R. Reduzindo a dimensionalidade dos dados com redes neurais. ciência , v. 313, n. 5786, p. 504-507, 2006.
HOCHREITER, Sepp; SCHMIDHUBER, Jürgen. Longa memória de curto prazo. Computação Neural, v. 9, n. 8, p. 1735-1780, 1997.
INTRODUCTION to artificial neural networks, Proceedings Electronic Technology Directions to the Year 2000, Adelaide, SA, Australia, 1995, pp. 36-62. Disponível em: https://ieeexplore.ieee.org/document/403491
KOROLEV, Dmitrii. Set of different neural nets. Neuron network. Deep learning. Cognitive technology concept. Vector illustration Disponível em: https://stock.adobe.com/br/images/set-of-different-neural-nets-neuron-network-deep-learning-cognitive-technology-concept-vector-illustration/145011568
LIU, C.; CAO, Y; LUO Y; CHEN, G; VOKKARANE, V, MA, Y; CHEN, S; HOU, P. A new Deep Learning-based food recognition system for dietary assessment on an edge computing service infrastructure. IEEE Transactions on Services Computing, PP(99):1–13. 2017
LORENA, Ana Carolina; DE CARVALHO, André CPLF. Uma introdução às support vector machines. Revista de Informática Teórica e Aplicada, v. 14, n. 2, p. 43-67, 2007.
MARVIN, Minsky; SEYMOUR, Papert. Perceptrons. 1969. Disponível em: http://134.208.26.59/math/AI/AI.pdf
MCCULLOCH, Warren S; PITTS, Walter. Um cálculo lógico das idéias imanentes na atividade nervosa. O boletim de biofísica matemática, v. 5, n. 4, p. 115-133, 1943.
NIELSEN, Michael. How the backpropagation algorithm works. 2018. Disponível em: http://neuralnetworksanddeeplearning.com/chap2.html
NIPS. 2009. Disponível em: http://media.nips.cc/Conferences/2009/NIPS-2009-Workshop-Book.pdf
PANG, Y; SUN, M; JIANG, X; LI, X.. Convolution in convolution for network in network. IEEE Transactions on Neural Networks and Learning Systems, PP(99):1–11. 2017
SANTANA, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponível em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
UDACITY. Conheça 8 aplicações de Deep Learning no mercado. Disponível em: https://br.udacity.com/blog/post/aplicacoes-deep-learning-mercado
YANG, S; LUO, P; LOY, C.C; TANG, X. From facial parts responses to face detection: A Deep Learning approach. In Proceedings of 2015 IEEE International Conference on Computer Vision (ICCV), pages 3676–3684. 2015
- Liu, C., Cao, Y., Luo, Y., Chen, G., Vokkarane, V., Ma, Y., Chen, S., and Hou, P. (2017). A new Deep Learning-based food recognition system for dietary assessment on an edge computing service infrastructure. IEEE Transactions on Services Computing, PP(99):1–13.
- Yang, S., Luo; P., Loy, C.-C; Tang, X. From facial parts responses to face detection: A Deep Learning approach. In Proceedings of 2015 IEEE International Conference on Computer Vision (ICCV), p. 3676
- Chung, J; Gulcehre, C; Cho, K; Bengio, Y. Gated feedback recurrent neural networks. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, volume 37 of ICML, p. 2069
- PANG, Y; Sun, M., Jiang, X., and Li, X. (2017). Convolution in convolution for network in network. IEEE Transactions on Neural Networks and Learning Systems, PP(99):5. 2017 ↑
- Goodfellow, I., Bengio, Y., and Courville, A. Deep Learning. MIT Press. http://www.deeplearningbook.org.
- GRAVES, A. Sequence transduction with recurrent neural networks. arXiv preprint arXiv:1211.3711, 2012.
- GARTNER. Gartner diz que a AI Technologies estará em quase todos os novos produtos de software até 2020. Disponível em: https://www.gartner.com/en/newsroom/press-releases/2017-07-18-gartner-says-ai-technologies-will-be-in-almost-every-new-software-product-by-2020
- MCCULLOCH, Warren S; PITTS, Walter. Um cálculo lógico das idéias imanentes na atividade nervosa. O boletim de biofísica matemática , v. 5, n. 4, p. 115-133, 1943.
- HEBB, Donald O. The organization of behavior; a neuropsycholocigal theory. A Wiley Book in Clinical Psychology., p. 62-78, 1949.
- BITTENCOURT, Guilherme. Breve história da Inteligência Artificial. 2001.p. 24
- Idbiem p. 25
- MARVIN, Minsky; SEYMOUR, Papert. Perceptrons. 1969. Disponível em: http://134.208.26.59/math/AI/AI.pdf
- Introduction to artificial neural networks,” Proceedings Electronic Technology Directions to the Year 2000, Adelaide, SA, Australia, 1995, pp. 36-62. Disponível em: https://ieeexplore.ieee.org/document/403491
- BITTENCOURT, Guilherme op cit. p. 32
- NIELSEN, Michael. How the backpropagation algorithm works. 2018. Disponível em: http://neuralnetworksanddeeplearning.com/chap2.html
- HINTON, Geoffrey E; SALAKHUTDINOV, Ruslan R. Reduzindo a dimensionalidade dos dados com redes neurais. ciência , v. 313, n. 5786, p. 504-507, 2006.
- NIPS. 2009. Disponível em: http://media.nips.cc/Conferences/2009/NIPS-2009-Workshop-Book.pdf
- Santana, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponivel em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
- SANTANA, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponível em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
- idem
- UDACITY. Conheça 8 aplicações de Deep Learning no mercado. Disponível em: https://br.udacity.com/blog/post/aplicacoes-deep-learning-mercado
- Dettmers, Tim. Aprendizagem profunda em poucas palavras: Historia e Treinamento. Disponível em: https://devblogs.nvidia.com/deep-learning-nutshell-history-training/
- FUKUSHIMA, Kunihiko. Neocognitron: Um modelo de rede neural auto-organizada para um mecanismo de reconhecimento de padrões não afetado pela mudança de posição. Cibernética biológica , v. 36, n. 4, p. 193-202, 1980.
- LORENA, Ana Carolina; DE CARVALHO, André CPLF. Uma introdução às support vector machines. Revista de Informática Teórica e Aplicada, v. 14, n. 2, p. 43-67, 2007.
- HOCHREITER, Sepp; SCHMIDHUBER, Jürgen. Longa memória de curto prazo. Computação Neural, v. 9, n. 8, p. 1735-1780, 1997.
- HOCHREITER, Sepp. O problema do gradiente de fuga durante a aprendizagem de redes neurais recorrentes e soluções de problemas. Revista Internacional de Incerteza, Fuzziness and Knowledge-Based Systems , v. 6, n. 02, p. 107-116, 1998.
- DENG, Jia et al. Imagenet: Um banco de dados de imagens hierárquicas em grande escala. In: 2009 Conferência IEEE sobre visão computacional e reconhecimento de padrões . Ieee, 2009. p. 248-255.
- MCCULLOCH, Warren S.; PITTS, Walter. Um cálculo lógico das idéias imanentes na atividade nervosa. O boletim de biofísica matemática , v. 5, n. 4, p. 115-133, 1943.
- SANTANA, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponivel em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
- ALIGER. Saiba o que é visão computacional e como ela pode ser usada. 2018. Disponível em: https://www.aliger.com.br/blog/saiba-o-que-e-visao-computacional/
[1] Bachelor of Business Administration.
Enviado: Maio, 2019
Aprovado: Maio, 2019

14 respostas
Realmente depois desse artigo a gente enxerga que a inteligência artificial já não é enredo para filmes de ficção MESMOOOO ! Muito legal, muito gostoso de ler e o artigo muito bem elaborado, aprendi e me surpreendi com coisas que nem imaginava que já estivessem nesse ponto. Obrigado ao autor que brilhantemente desenhou a situação da inteligência artificial de maneira eficiente e eficaz. Simplesmente PERFEITO ! Vamos que vamos, rumo a esse futuro maravilhoso !
Obrigado Pablo!
Edgar, inteligência artificial está entrando aos poucos em nossa realidade, pessoal/profissional. Acredito muito que estamos caminhando para uma situação ainda não vista até então. Tecnologia surpreendente.
Parabéns
Deep learning dentro do campo da IA é sem dúvida umas das mais fantásticas matérias a serem exploradas. Ótimo artigo.
Abraço!
Edgar, este campo da IA me desperta muitas curiosidades. Procuro ficar sempre atualizado. Citando alguns marcos deste modelo, vejo que : compreensão do comportamento das pessoas , reconhecimento facial, classificação de doenças, redução no erro de diagnóstico do câncer, carros autônomos. Podemos ficar falando por horas sobre tudo que a Deep learning pode contribuir para nossa sociedade, ainda mais associada aos outros campos da IA.
Parabéns pelo seu Artigo.
Gostei da forma que voce abordou sobre Deep Learning. Vou referenciar você em meu artigo sobre IA. Parabéns.
Obrigado Dirceu!
Ainda vamos ver muitas novidades sobre IA. Em meu próximo artigo vou abordar o que podemos esperar em um futuro próximo .
Sim Wesley , IA porque vários campos interessantes. Machine learning é uma delas também.
Obrigado Fagner. Em meu próximo artigo a ser publicado estou abordando estes temas também!
Obrigado Leonardo! Espero poder contribuir.
Abraço!
Ótimo Artigo, Edgar.
Muito coerente e tema relevante para o que estamos presenciando.
Olá Edgar! Estou fazendo um MBA em IA, e o seu Artigo nos trás o quanto no início estamos de uma tecnologia que revolucionará, será quebrado muitos paradigmas.
Muito bom!
Muito bom artigo, bem contextualizado.
Parabéns.
Estou lendo este artigo 5 anos depois de seu lançamento. É notório o salto que a inteligência artificial deu de lá pra cá. Muito interessante entender como surgiu o termo que hoje em 2024 é um dos mais buscados/falados.