ARTICOLO ORIGINALE
CHAGAS, Edgar Thiago De Oliveira [1]
CHAGAS, Edgar Thiago De Oliveira. Deep Learning e le sue applicazioni oggi. Revista Científica Multidisciplinar Núcleo do Conhecimento. anno 04, Ed. 05, vol. 04, pp. 05-26 maggio 2019. ISSN: 2448-0959
RIEPILOGO
L'intelligenza artificiale non è più un complotto per i film di fiction. La ricerca in questo campo aumenta ogni giorno e fornisce nuove informazioni sul Machine Learning. I metodi di Deep Learning, conosciuti anche come Deep Learning, sono attualmente utilizzati su molti fronti come il riconoscimento facciale nei social network, automobili automatizzate e anche alcune diagnosi nel campo della medicina. Deep Learning consente ai modelli computazionali composti da innumerevoli livelli di elaborazione di "apprendere" rappresentazioni di dati con diversi livelli di astrazione. Questi metodi migliorato il riconoscimento vocale, oggetti visivi, il rilevamento degli oggetti, tra le possibilità. Tuttavia, questa tecnologia è ancora poco conosciuta, e lo scopo di questo studio è quello di chiarire come funziona il Deep Learning e di dimostrare le sue applicazioni attuali. Naturalmente, con la diffusione di questa conoscenza, l'apprendimento profondo può, nel prossimo futuro, presentare altre applicazioni, ancora più importanti per tutta l'umanità.
Parole chiave: Deep Learning, Machine Learning, IA, macchinari Learning, Intelligence.
INTRODUZIONE
L'apprendimento profondo è inteso come un ramo di Machine Learning, che si basa su un gruppo di algoritmi che cercano di modellare astrazioni di alto livello dei dati utilizzando un grafico profondo con diversi livelli di elaborazione, Composto da diverse alterazioni lineari e non lineari.
Deep Learning lavora il sistema informatico per eseguire attività come il riconoscimento vocale, l'identificazione delle immagini e la proiezione. Piuttosto che organizzare le informazioni per agire attraverso equazioni predeterminate, questo apprendimento determina i modelli di base di queste informazioni e insegna ai computer a svilupparsi attraverso l'identificazione di modelli in strati di elaborazione.
Questo tipo di apprendimento è un ramo completo dei metodi di machine learning basati sulle rappresentazioni di apprendimento delle informazioni. In questo senso, Deep Learning è un insieme di algoritmi di Machine Learning che tentano di integrare più livelli, che sono riconosciuti modelli statistici che corrispondono a diversi livelli di definizioni. Livelli più bassi aiutano a definire molte nozioni di livelli più alti.
Ci sono innumerevoli ricerche attuali in questo settore di intelligenza artificiale. Il miglioramento delle tecniche di Deep Learning ha implementato miglioramenti nella capacità dei computer di comprendere ciò che è richiesto. La ricerca in questo campo Cerca di promuovere rappresentazioni migliori e modelli elaborati per identificare queste rappresentazioni da informazioni non etichettate su larga scala, alcune come base nei risultati delle neuroscienze e nell'interpretazione di Elaborazione dati e modelli di comunicazione nel sistema nervoso. Dal 2006 in poi, questo tipo di apprendimento è emerso come un nuovo ramo della ricerca di apprendimento automatic[2]o.
Recentemente, sono state sviluppate nuove tecniche da Deep Learning, che hanno influenzato diversi studi sull'elaborazione del segnale e l'identificazione dei modelli. Si noti una serie di nuovi comandi problematici che possono essere risolti attraverso queste tecniche, tra cui Machine Learning e intelligenza artificiale punti chiave.
C'è molta attenzione ai media, secondo Yang et al, [3]sui progressi raggiunti in questo settore. Le grandi organizzazioni tecnologiche hanno applicato molti investimenti nella ricerca di Deep Learning e nelle loro nuove applicazioni.
L'apprendimento profondo comprende l'apprendimento a vari livelli di rappresentazione e di intangibilità che aiutano nel processo di comprensione di informazioni, immagini, suoni e testi.
Tra le mostre disponibili sul Deep Learning, è possibile identificare due punti di notevole impatto. Il primo dimostra che sono modelli formati da innumerevoli livelli o fasi di elaborazione dei dati non lineari e sono anche pratiche di apprendimento supervisionati o meno, della rappresentazione di attribuzioni in strati successivi e immateriali.
È inteso che Deep Learning è nelle articolazioni tra i rami della ricerca di reti neurali, AI, la modellazione grafica, l'identificazione e l'ottimizzazione dei modelli e l'elaborazione del segnale. L'attenzione rivolta al Deep Learning è dovuta al miglioramento delle capacità di lavorazione del truciolo, al considerevole aumento delle dimensioni delle informazioni utilizzate per la formazione e ai recenti progressi negli studi di machine learning e di elaborazione di segnali.
Questi progressi hanno consentito alle pratiche di Deep Learning di sfruttare efficacemente le applicazioni complesse e non lineari, identificare le rappresentazioni di risorse distribuite e gerarchiche e consentire l'uso efficace di Informazioni etichettate e senza etichetta.[4]
Deep Learning si riferisce a una classe completa di metodi e progetti di Machine Learning, che riuniscono la caratteristica di utilizzare molti strati di dati elaborati non lineari di natura gerarchica. A causa dell'uso di questi metodi e progetti, una gran parte degli studi in questa sfera può essere classificata in tre insiemi principali, secondo Pang et [5]al, che sono le reti profonde per l'apprendimento non supervisionato; Supervisionato e ibrido.
Sono disponibili reti profonde per l'apprendimento non supervisionato per arrestare la correlazione ad alta sequenza delle informazioni analizzate o identificabili per la verifica o l'associazione di standard quando non vi sono dati sugli stereotipi delle classi Disponibile nel database. L'apprendimento dell'attribuzione o della rappresentazione non supervisionata si riferisce a reti profonde. Inoltre, è possibile cercare l'assegnazione di distribuzioni statistiche raggruppate dei dati visibili e delle relative classi correlate quando disponibili e possono essere coperte come parte dei dati visibili.
Le reti neurali profonde per l'apprendimento supervisionato dovrebbero fornire discriminazioni per classificare i modelli, di solito individualizzando le successive distribuzioni di classi collegate alle informazioni visibili, che sono sempre Disponibile per questo apprendimento supervisionato, anche indicato come reti profonde discriminatori.
Le profonde reti ibride sono evidenziate dalla discriminazione identificata con i risultati di reti profonde generativa o non supervisionate, che possono essere raggiunte attraverso il miglioramento e/o la regolarizzazione delle reti supervisionate profonde. Le sue attribuzioni possono essere raggiunte anche quando le linee guida discriminatorie per l'apprendimento supervisionato sono utilizzate per valutare gli standard in qualsiasi rete profonda generativa o non sorvegliat[6]a.
Le reti profonde e ricorrenti sono modelli che presentano un alto rendimento in questioni di identificazione di modelli discutibili in Ivain e discors[7]o. Nonostante il suo potere di rappresentazione, la grande difficoltà nella modellazione di reti neurali profonde con uso generico persiste fino ai giorni nostri. In relazione alle reti neurali ricorrenti, gli studi di Hinton et a[8]l hanno avviato lo stampaggio a strati.
Il presente studio mira a chiarire il progresso del Deep Learning e delle sue applicazioni secondo le più recenti ricerche. Per fare questo, sarà condotta una ricerca descrittiva qualitativa, con l'uso di libri, tesi, articoli e siti Web per concettualmente i progressi nel campo dell'intelligenza artificiale e soprattutto nel Deep Learning.
Dall'ultimo decennio si è registrato un crescente interesse per l'apprendimento automatico, dato che esiste un'interazione sempre crescente tra applicazioni, dispositivi mobili o informatici, con individui, attraverso programmi per rilevare lo spam, Riconoscimento in foto sui social network, smartphone con riconoscimento facciale, tra le altre applicazioni. Secondo Gartner tut[9]ti i programmi aziendali avranno qualche funzione legata al Machine Learning fino all'anno 2020. Questi elementi mirano a giustificare l'elaborazione di questo studio.
SVILUPPO STORICO DEL DEEP LEARNING
L'intelligenza artificiale non è una scoperta recente. Proviene dal decennio del 1950, ma nonostante l'evoluzione della sua struttura, mancano alcuni aspetti della credibilità. Uno di questi aspetti è il volume di dati, originato da un'ampia varietà e velocità, che consente la creazione di standard con elevati livelli di accuratezza. Tuttavia, un punto rilevante era su come i modelli di Machine Learning di grandi dimensioni sono stati elaborati con grandi quantità di informazioni, perché i computer non potevano eseguire tale azione.
In quel momento è stato identificato il secondo aspetto riferito alla programmazione parallela nelle GPU. Le unità di elaborazione grafica, che consentono la realizzazione di operazioni matematiche in parallelo, in particolare quelle con matrici e vettori, presenti in modelli di reti artificiali, hanno permesso l'evoluzione attuale, cioè la Sommatoria dei Big Data (grande volume di dati); I modelli di elaborazione parallela e Machine Learning presentano un'intelligenza artificiale di conseguenza.
L'unità di base di una rete neurale artificiale è un Neuron matematico, chiamato anche un nodo, basato sul Neuron biologico. I legami tra questi neuroni matematici sono legati a quelli del cervello biologico, e soprattutto nel modo in cui queste associazioni si sviluppano nel tempo, chiamato "formazione".
Tra la seconda metà del decennio di 80 e l'inizio del decennio di 90, sono avvenuti diversi progressi significativi nella struttura delle reti artificiali. Tuttavia, la quantità di tempo e le informazioni necessarie per ottenere buoni risultati hanno procrastinato l'adozione, influenzando l'interesse per l'intelligenza artificiale.
Nei primi 2000 anni, la potenza del computing ampliato e il mercato sperimentato un "boom" di tecniche computazionali che non erano possibili prima. È stato quando il Deep Learning è emerso dalla grande crescita computazionale di quel tempo come un meccanismo essenziale per l'elaborazione di sistemi di intelligenza artificiale, vincendo diverse competizioni di machine learning. L'interesse per l'apprendimento profondo continua a crescere fino ai giorni nostri e diverse soluzioni commerciali emergono in ogni momento.
Nel corso del tempo, sono state create diverse ricerche al fine di simulare il funzionamento del cervello, soprattutto durante il processo di apprendimento per creare sistemi intelligenti che potrebbero ricreare compiti come la classificazione e il riconoscimento dei modelli, tra Altre attività. Le conclusioni di questi studi hanno generato il modello di Neuron artificiale, posto più tardi in una rete interconnessa chiamata rete neurale.
Nel 1943, Warren McCulloch, neurofisiologo e Walter Pitts, matematico, creò una semplice rete neurale utilizzando circuiti elettrici e elaborò un modello informatico per reti neurali basata su concetti matematici e algoritmi chiamati soglia Logica o logica di soglia, che ha permesso la ricerca sulla rete neurale divisa in due filoni: concentrandosi sul processo biologico del cervello e un altro concentrandosi sull'applicazione di queste reti neurali finalizzate all'intelligenza artificiale.[10]
Donald Hebb[11], nel 1949, ha scritto un lavoro in cui ha riferito che i circuiti neurali sono rafforzati più sono utilizzati, come l'essenza dell'apprendimento. Con l'avanzamento dei computer nel decennio 1950, l'idea di una rete neurale ha guadagnato forza e Nathanial Rocheste[12]r dai laboratori di studio di IBM ha cercato di costituire uno, ma non ha avuto successo.
Il progetto di ricerca estiva di Dartmouth su[13]ll'intelligenza artificiale, in 1956, ha potenziato le reti neurali, così come l'intelligenza artificiale, incoraggiando la ricerca in questo settore in relazione all'elaborazione neurale. Negli anni che seguirono, John von Neumann imitò semplici funzioni di neuroni con tubi a vuoto o telegrafi, mentre Frank Rosenblatt iniziò il progetto perceptron, analizzando il funzionamento dell'occhio di una Mosca. Il risultato di questa ricerca è stato un hardware, che è la più antica rete neurale utilizzata fino ai giorni nostri. Tuttavia, il perceptron è molto limitato, che è stato dimostrato da Marvin e Papert[14]
Figura 1: struttura della rete neurale
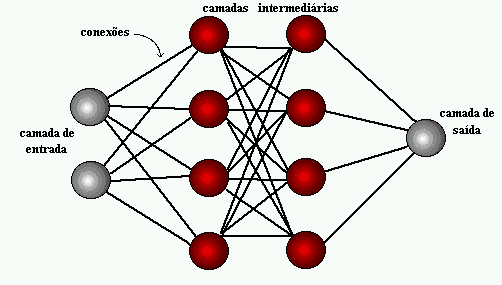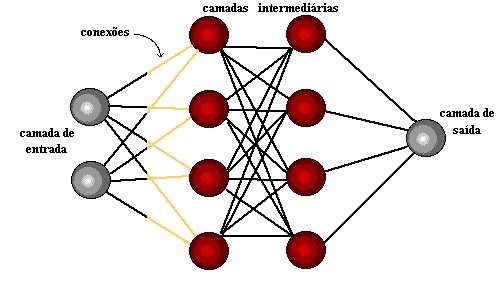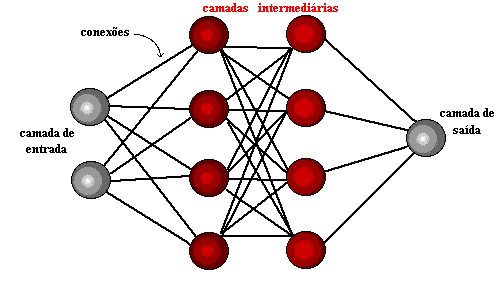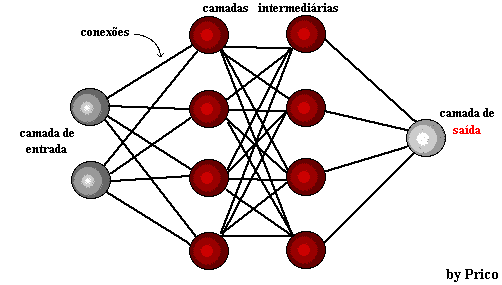
Pochi anni dopo, nel 1959, Bernard Widrow e Marcian Hoff svilupparono due modelli denominati "Adaline" e "Madaline". La nomenclatura deriva dall'uso di più elementi: ADAptive LINear. Adaline è stato creato per identificare i modelli binari al fine di fare previsioni circa il bit successivo, mentre "Madaline" è stata la prima rete neurale applicata a un problema reale, utilizzando un filtro adattivo. Il sistema è ancora in uso, ma solo commerciale.[15]
I progressi raggiunti in precedenza portarono alla convinzione che il potenziale delle reti neurali fosse limitato all'elettronica. È stato interrogato sull'impatto che le "macchine intelligenti" avrebbero sull'uomo e sulla società nel suo complesso.
Il dibattito su come l'intelligenza artificiale avrebbe influenzato l'uomo, ha sollevato critiche sulla ricerca nelle reti neurali che ha causato una riduzione dei finanziamenti e, di conseguenza, studi nella zona, che è rimasta fino al 1981.
L'anno successivo, diversi eventi hanno reacl'interesse in questo campo. John Hopfield di Caltech ha presentato un approccio alla creazione di dispositivi utili, dimostrando i suoi incarich[16]i. In 1985, l'American Institute of Physics ha iniziato un incontro annuale chiamato Neural Networks per il calcolo. Nel 1986, i media cominciarono a segnalare le reti neurali di diversi livelli, e tre ricercatori hanno presentato idee simili, chiamate reti di Backpropagazione, perché distribuiscono errori di identificazione dei modelli in tutta la rete.
Le reti ibride avevano solo due livelli, mentre le reti di Backpropagazione presen[17]tano molti, in modo che questa rete conservi le informazioni più lentamente, perché hanno bisogno di migliaia di iterazioni per imparare, ma anche presentare più risultati esatto. Già nel 1987, c'è stata la prima conferenza internazionale sulle reti neurali dell'Istituto di ingegneria elettrica ed elettronica (IEEE).
Nell'anno 1989, gli scienziati hanno creato algoritmi che usavano reti neurali profonde, ma il tempo di ' apprendimento ' era molto lungo, il che impediva la sua applicazione alla realtà. In 1992, Juyang Weng Diulga il metodo Cresceptron per eseguire il riconoscimento di oggetti 3D da scene tumultuose.
A metà degli anni 2000, il termine Deep Learning o Deep Learning comincia ad essere diffuso dopo un articolo di Geoffrey Hinton e Ruslan Salakhutdinov, [18]che ha dimostrato come una rete neurale multilivello potesse essere precedentemente addestrata, uno strato alla volta .
In 2009, i sistemi di rete neurale elaborazione workshop sul Deep learning per il riconoscimento vocale avviene ed è verificato che con un vasto gruppo di dati, reti neurali non hanno bisogno di formazione preventiva e tassi di fallimento cadono Significativamente[19].
In 2012, le ricerche hanno fornito algoritmi di identificazione di modelli artificiali con prestazioni umane in alcuni compiti. E l'algoritmo di Google identifica i felini.
In 2015, Facebook utilizza Deep learning per contrassegnare e riconoscere automaticamente gli utenti nelle foto. Gli algoritmi eseguono attività di riconoscimento facciale utilizzando reti profonde. Nell'anno 2017, c'è stata un'adozione su larga scala di Deep Learning in varie applicazioni aziendali e dispositivi mobili, nonché progressi nella ricerca[20].
L'impegno di Deep Learning è quello di dimostrare che un insieme abbastanza esteso di dati, processori veloci e un algoritmo abbastanza sofisticato, rende possibile per i computer di eseguire attività come il riconoscimento di immagini e voce, tra gli altri Possibilità.
La ricerca sulle reti neurali ha guadagnato risalto con attribuzioni promettenti presentate dai modelli di rete neurale creati, a causa delle recenti innovazioni tecnologiche di implementazione che consentono di sviluppare strutture neurali audaci Parallelo all'hardware, ottenendo prestazioni soddisfacenti di questi sistemi, con prestazioni superiori ai sistemi convenzionali, tra cui. L'evoluzione delle reti neurali è Deep Learning.
DEEP LEARNING
Si tratta inizialmente di differenziare l'intelligenza artificiale, l'apprendimento automatico e il Deep Learning.
Figura 2: intelligenza artificiale, apprendimento automatico e Deep Learning
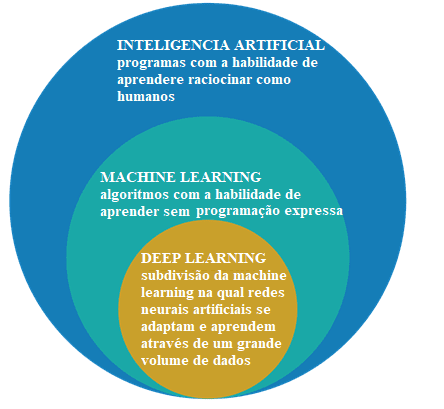
Il campo di studio dell'intelligenza artificiale è la ricerca e la progettazione di fonti intelligenti, cioè un sistema che può prendere decisioni basate su una caratteristica considerata intelligente. Nell'intelligenza artificiale ci sono diversi metodi che modellino questa caratteristica e tra questi è la sfera del machine learning, dove vengono prese le decisioni (intelligenza) basate su esempi e non una programmazione determinata.
Gli algoritmi di Machine Learning richiedono informazioni per rimuovere funzionalità e apprendi che possono essere utilizzate per prendere decisioni future. Deep Learning è un sottogruppo di tecniche di Machine Learning, che generalmente utilizzano reti neurali profonde e necessitano di una grande quantità di informazioni per la formazione[21].
Secondo Santana ci s[22]ono alcune differenze tra le tecniche di machine learning e i metodi di Deep Learning, e le principali sono la necessità e l'impatto del volume dei dati, la potenza computazionale e la flessibilità nella modellazione dei problemi.
Machine Learning ha bisogno di dati per identificare i modelli, ma ci sono due problemi relativi ai dati che si riferiscono alla dimensionalità e alla stagnazione delle prestazioni introducendo più dati oltre il limite comportato. Si è verificato che vi sia una riduzione delle prestazioni significative quando ciò si verifica. In relazione alla dimensionalità lo stesso avviene, in quanto vi sono molte informazioni per rilevare, attraverso le tecniche classiche la dimensione del problema.
Figura 3: confronto tra Deep Learning e altri algoritmi per quanto riguarda la quantità di dati.
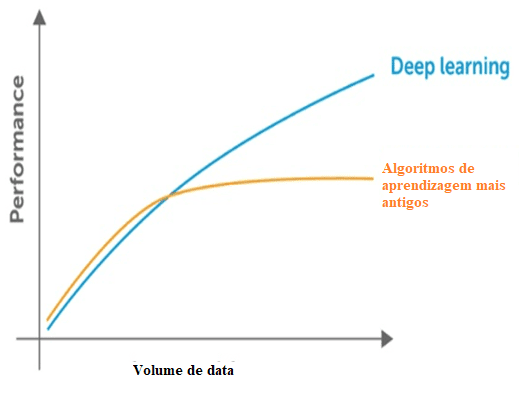
Le tecniche classiche presentano anche un punto di saturazione in relazione alla quantità di dati, cioè hanno un limite massimo per estrarre le informazioni, che non si verificano con il Deep Learning, create per lavorare con un grande volume di dati.
In relazione alla potenza computazionale per l'apprendimento profondo, le sue strutture sono complesse e richiedono un grande volume di dati per la sua formazione, che dimostra la sua dipendenza da un grande potere computazionale per implementare queste pratiche. Mentre altre pratiche classiche necessitano di molta potenza computazionale come CPU, le tecniche di Deep Learning sono superiori.
Le ricerche relative al calcolo parallelo e all'utilizzo delle GPU con CUDA-Compute Unified Device Architecture o l'architettura dei dispositivi di elaborazione unificata hanno avviato Deep Learning, poiché non era fattibile con l'uso di una semplice CPU.
In un confronto con la formazione di una rete neurale profonda o Deep Learning con l'utilizzo di una CPU, si scopre che sarebbe impossibile ottenere risultati soddisfacenti anche con un allenamento prolungato.
Il Deep Learning, noto anche come Deep Learning, fa parte del machine learning e applica algoritmi per elaborare i dati e riprodurre l'elaborazione eseguita dal cervello umano.
Deep Learning utilizza strati di neuroni matematici per elaborare i dati, identificare la voce e riconoscere gli oggetti. I dati vengono trasmessi attraverso ogni livello, con l'output del livello precedente che concede l'input al livello successivo. Il primo livello di una rete è chiamato livello di input e l'ultimo è il livello di output. I livelli intermedi sono chiamati livelli nascosti, e ogni livello della rete è formato da un algoritmo semplice e uniforme che comprende una sorta di funzione di attivazione.
Figura 4: rete neurale semplice e profonda rete neurale o Deep Learning
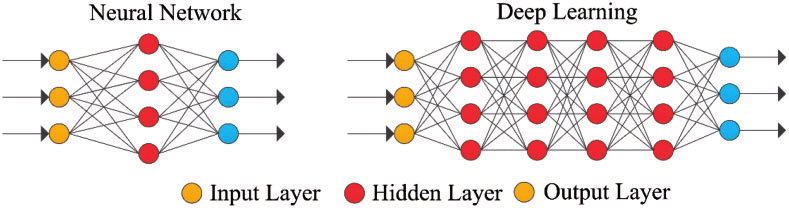
I livelli più esterni in giallo sono i livelli di input o output e i livelli intermedi o nascosti sono in rosso. Deep Learning è responsabile dei recenti progressi nel calcolo, del riconoscimento vocale, dell'elaborazione linguistica e dell'identificazione uditiva, sulla base della definizione di reti neurali artificiali o di sistemi computazionali che riproducono il Come agisce il cervello umano.
Un altro aspetto del Deep Learning è l'estrazione di risorse, che utilizza un algoritmo per creare automaticamente parametri rilevanti di informazioni per la formazione, l'apprendimento e la comprensione, un compito dell'ingegnere di intelligenza artificiale.
Deep Learning è un'evoluzione delle reti neurali. L'interesse per l'apprendimento profondo è cresciuto gradualmente nei media e diverse ricerche nella zona sono state diffuse e la sua applicazione ha raggiunto automobili, nella diagnosi del cancro e dell'autismo, tra le altre applicazioni[23]
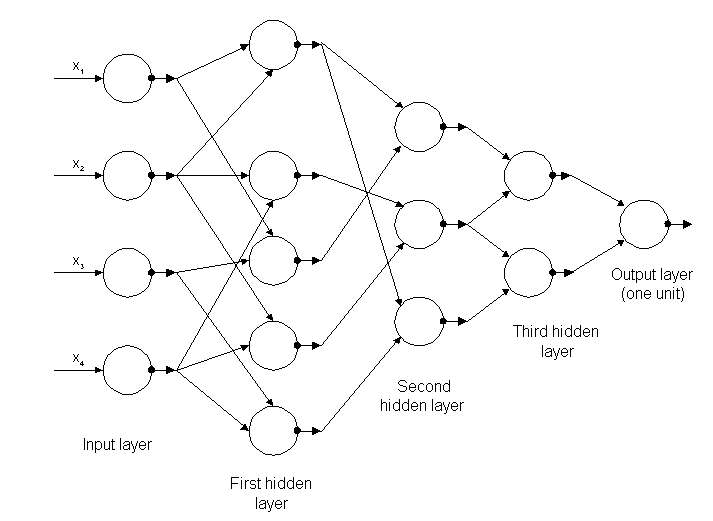
I primi algoritmi di Deep Learning con più livelli di assegnazioni non lineari presentano le loro origini in Alexey Grigoryevich Ivakhnenko, che ha sviluppato il metodo del gruppo di manipolazione dei dati e Valentin Grigor ' evich Lapa, autore del lavoro Cybernetics e tecniche di previsione nell'anno 1965.[24]
Entrambi utilizzati modelli sottili e profondi con funzioni di attivazione polinomiale, che sono stati studiati utilizzando metodi statistici. Attraverso questi metodi hanno selezionato in ogni livello le migliori risorse e trasmessi al livello successivo, senza utilizzare Backpropagazione per "addestrare" la rete completa, ma utilizzato quadrati minimi su ogni livello, dove quelli precedenti sono stati installati da In modo indipendente nei livelli successivi, manualmente.
Figura 5: struttura della prima rete profonda conosciuta come Alexey Grigorevich Ivakhnenko
Alla fine del decennio di 1970 si è verificato l'inverno dell'intelligenza artificiale, una drastica riduzione dei finanziamenti per la ricerca sul tema. L'impatto ha limitato i progressi nelle reti neurali profonde e intelligenza artificiale.
Le prime reti neurali convoluzionali furono usate da Kunihiko Fukushima, con diversi strati di raggruppamento e convoluzioni, in 1979. Ha creato una rete neurale artificiale, denominata Neocognitron, con un layout gerarchico e multistrato, che ha consentito al computer di identificare i modelli visivi. Le reti erano simili alle versioni moderne, con "Training" incentrato sulla strategia di rafforzare l'attivazione periodica in innumerevoli strati. Inoltre, il progetto di Fukushima ha consentito di adattare manualmente le risorse più rilevanti aumentando l'importanza di determinate connessioni[25].
Molte linee guida Neocognitron sono ancora in uso, come connessioni top-down e nuove pratiche di apprendimento hanno promosso la realizzazione di varie reti neurali. Quando diversi modelli sono presentati allo stesso tempo, il modello di cura selettiva può separarli e identificare i singoli modelli, prestando attenzione a ciascuno. Un Neocognitron più aggiornato può identificare i modelli con mancanza di dati e completare l'immagine inserendo le informazioni mancanti, che è chiamata inferenza.
Il Backpropagazione utilizzato per l'addestramento di fallimento Deep Learning progrediva da 1970 in poi, quando Seppo LINNAINMAA scrisse una tesi, inserendo un codice FORTRAN per la Backpropagazione, senza riuscire fino a 1985. Rumelhart, Williams e Hinton hanno poi dimostrato la Backpropagazione in una rete neurale con rappresentazioni di distribuzione.
Questa scoperta ha permesso al dibattito sull'IA di raggiungere la psicologia cognitiva che ha iniziato domande sulla comprensione umana e il suo rapporto con la logica simbolica, così come le connessioni. Nel 1989, Yann LeCun eseguì una dimostrazione pratica di Backpropagazione, con la combinazione di reti neurali convoluzionali per identificare le cifre scritte.
In questo periodo c'è stata ancora una carenza di finanziamenti per la ricerca in questo settore, noto come il secondo inverno della IA, che si è verificato tra 1985 e 1990, interessando anche la ricerca nelle reti neurali e Deep Learning. Le aspettative presentate da alcuni ricercatori non hanno raggiunto il livello atteso, che ha profondamente irritato gli investitori.
Nel 1995, Dana Cortes e Vladimir Vapnik hanno creato la macchina Vector di s[26]upporto o la macchina vettoriale portante che era un sistema per mappare e identificare informazioni simili. Il lungo periodo di memoria-LSTM per le reti neurali periodiche è stato elaborato in 1997, da Sepp Hochreiter e Juergen Schmidhube[27]r.
Il passo successivo nell'evoluzione del Deep Learning si è verificato in 1999, quando le unità di elaborazione dati e di elaborazione grafica (GPU) sono diventate più veloci. L'uso delle GPU e la sua rapida elaborazione hanno rappresentato un aumento della velocità dei computer. Le reti neurali competevano con macchine vettoriali di supporto. La rete neurale era più lenta di una macchina vettoriale di supporto, ma ha ottenuto risultati migliori e ha continuato a evolversi Man parte che sono state aggiunte informazioni di training.
Nell'anno 2000 è stato identificato un problema denominato Vanishing gradient. Gli incarichi appresi in livelli inferiori non sono stati trasmessi agli strati superiori Tuttavia, si è verificato solo in quelli con metodi di apprendimento basati su gradiente. La fonte del problema era in alcune funzioni di attivazione che riduceva il suo input che interessava l'intervallo di output, generando grandi aree di input mappate in un intervallo molto piccolo, causando un gradiente discendente. Le soluzioni implementate per risolvere il problema erano lo strato pre-allenamento per strato e lo sviluppo di una memoria a lungo e breve termin[28]e.
In 2009, Fei-Fei li ha rilasciato ImageN[29]et con un database gratuito di oltre 14 milioni immagini, incentrata sulla "formazione" delle reti neurali, sottolineando come i Big Data influenzerebbero il funzionamento di machine learning.
La velocità delle GPU, fino all'anno 2011, ha continuato ad aumentare permettendo la composizione di reti neurali convoluzionali senza la necessità di pre-allenamento strato per strato. Così, è diventato noto che Deep Learning è stato vantaggioso in termini di efficienza e velocità.
Al giorno d'oggi, l'elaborazione dei Big Data e la progressione dell'intelligenza artificiale dipendono dal Deep Learning, che può elaborare sistemi intelligenti e promuovere la creazione di un'intelligenza artificiale completamente autonoma, che creerà un impatto sulla Tutta la societa '.
FLESSIVILITÀ DELLE RETI NEURALI E DELLE LORO APPLICAZIONI
Nonostante l'esistenza di diverse tecniche classiche, la struttura DEEP Learning e la sua unità di base, il neurone è generico e molto flessibile. Facendo un confronto con il neurone umano che fornisce sinapsi possiamo identificare alcune correlazioni tra di loro.
Figura 6: correlazione tra un neurone umano e una rete neurale artificiale
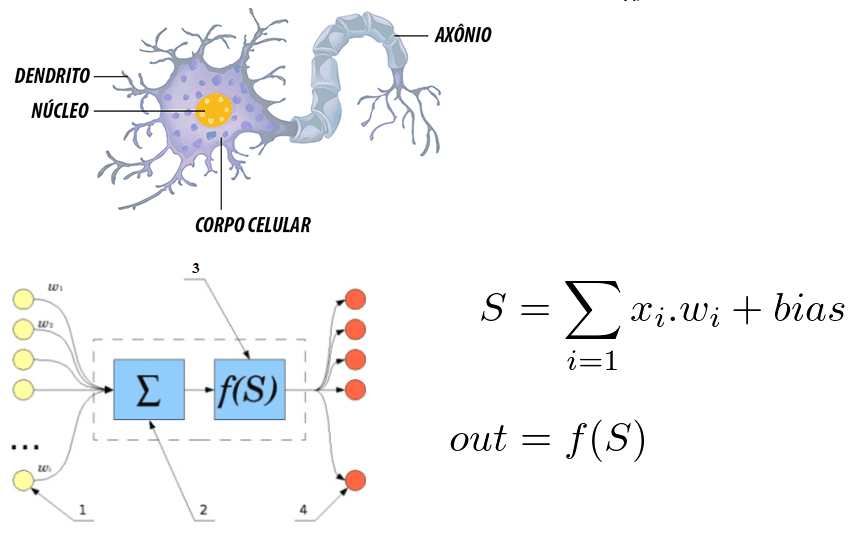
Si nota che il neurone è formato dai dendriti che sono i punti di ingresso, un nucleo che rappresenta nelle reti neurali artificiali il nucleo di elaborazione e il punto di uscita che è rappresentato dall'AXON. In entrambi i sistemi le informazioni entrano, vengono elaborate e modificate.
Considerandolo come un'equazione matematica, il neurone riflette la somma degli input moltiplicati per i pesi, e questo valore passa attraverso una funzione di attivazione. Questa somma è stata eseguita da McCulloch e Pitts nel 1943[30]
In relazione al famigerato interesse per il Deep Learning al giorno d'oggi, Santa[31]na ritiene che sia dovuto a due fattori che sono la quantità di informazioni disponibili e la limitazione delle tecniche più vecchie oltre all'attuale potere computazionale per addestrare le reti complesso. La flessibilità di interconnessione di più neuroni in una rete più complessa è il differenziale delle strutture di DEEP Learning. Una rete neurale convoluzionale è ampiamente utilizzata per il riconoscimento facciale, il rilevamento delle immagini e l'estrazione delle assegnazioni.
Una rete neurale convenzionale è costituita da diversi livelli, denominati layers. A seconda del problema da risolvere la quantità di strati può variare, essendo in grado di avere fino a centinaia di strati, essendo fattori che influenzano in quantità la complessità del problema, tempo e potenza computazionale
Ci sono diverse strutture con innumerevoli scopi e il loro funzionamento dipende anche dalla struttura e tutti sono basati su reti neurali.
Figura 7: esempi di reti neurali
Questa flessibilità architettonica consente un apprendimento profondo per risolvere vari problemi. Deep Learning è una tecnica oggettiva generale, ma gli ambiti più avanzati sono stati: visione artificiale, riconoscimento vocale, elaborazione del linguaggio naturale, sistemi di raccomandazione.
La visione computazionale comprende il riconoscimento degli oggetti, la segmentazione semantica, soprattutto auto autonome. Si può affermare che la visione computazionale fa parte dell'intelligenza artificiale ed è definita come un insieme di conoscenze che cerca la modellazione artificiale della visione umana con l'obiettivo di imitare le sue funzioni, attraverso lo sviluppo di software e hardware avanzat[32]o.
Tra le applicazioni della visione computazionale ci sono l'uso militare, il mercato del marketing, la sicurezza, i servizi pubblici e il processo produttivo. I veicoli autonomi rappresentano il futuro del traffico più sicuro, ma è ancora in fase di sperimentazione, in quanto comprende diverse tecnologie applicate a una funzione. La visione computazionale in questi veicoli, in quanto permette il riconoscimento del percorso e degli ostacoli, migliorando le rotte.
Nel contesto della sicurezza, i sistemi di riconoscimento facciale sono stati sempre più evidenziati, dato il livello di sicurezza in luoghi pubblici e privati, anche implementato in dispositivi mobili. Allo stesso modo possono servire come chiave per accedere alle transazioni finanziarie, mentre sui social network, rileva la presenza dell'utente o dei suoi amici in foto.
In relazione al mercato del marketing, una ricerca sviluppata da Image Intelligence ha sottolineato che 3 miliardi immagini sono condivise quotidianamente dai social network e 80% contengono indicazioni che si riferiscono a società specifiche, ma senza riferimenti testuali. Le aziende specializzate di marketing offrono un servizio di monitoraggio e gestione della presenza in tempo reale. Con la tecnologia di visione artificiale, la precisione nell'identificazione dell'immagine raggiunge 99%.
Nei servizi pubblici il suo utilizzo copre la sicurezza del sito monitorando le telecamere, il traffico veicolare attraverso immagini stereoscopiche che rendono efficiente il sistema di visione.
Nel processo produttivo, le aziende di diverse filiali impiegano la visione computazionale come strumento di controllo della qualità. In qualsiasi ramo, il software più avanzato associato alla sempre maggiore capacità di elaborazione dell'hardware aumenta l'uso della visione computazionale.
I sistemi di monitoraggio consentono il riconoscimento di standard prestabiliti e indicano errori che non sarebbero identificabili quando si guarda un dipendente nella linea di produzione. Nello stesso contesto, applicato al controllo magazzino è il progetto di automazione di sostituzione. Un inventario in tempo reale e controllo delle vendite consente alla tecnologia di controllare le operazioni di una determinata azienda, aumentando così i suoi profitti. Ci sono altre applicazioni nel campo della medicina, dell'istruzione e del commercio elettronico.
Conclusioni
Il presente studio ha cercato di chiarire ciò che è il Deep Learning e di sottolineare le sue applicazioni nel mondo attuale. Le tecniche di Deep Learning continuano a progredire in particolare con l'uso di più livelli. Tuttavia, esistono ancora limitazioni nell'uso di reti neurali profonde, dato che sono solo un modo per apprendere diverse modifiche da implementare nel vettore di input. Modifiche fornite da un intervallo di parametri che vengono aggiornati nel periodo di training.
È innegabile che l'intelligenza artificiale è una realtà più vicina, ma manca una lunga strada da percorrere. L'accettazione del Deep Learning in vari ambiti della conoscenza permette alla società, nel suo insieme, di trarre vantaggio dalle meraviglie della tecnologia moderna.
In relazione all'intelligenza artificiale, si verifica che questa tecnologia capace di apprendere, sebbene molto importante abbia una natura lineare e non modellabile rispetto agli esseri umani, che rappresenta un grande differenziale ed essenziale per alcune aree di conoscenza, il Questo non può ancora essere implementato nel Deep Learning.
In qualsiasi modo, l'uso dei metodi di Deep Learning permetterà alle macchine di assistere la società in varie attività come dimostrato, ampliando la capacità cognitiva dell'uomo e uno sviluppo ancora più grande in queste aree di conoscenza.
RIFERIMENTI BIBLIOGRAFICI
ALIGER. Saiba o que é visão computacional e como ela pode ser usada. 2018. Disponível em: https://www.aliger.com.br/blog/saiba-o-que-e-visao-computacional/
BITTENCOURT, Guilherme. Breve história da Inteligência Artificial. 2001
CARVALHO, André Ponce de L. Redes Neurais Artificiais. Disponível em: http://conteudo.icmc.usp.br/pessoas/andre/research/neural/
CHUNG, J; GULCEHE, C; CHO, K; BENGIO, Y. Gated feedback recurrent neural networks. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, volume 37 of ICML, pages 2067–2075. 2015
CULTURA ANALITICA. Entenda o que é deep learning e como funciona. Disponível em: https://culturaanalitica.com.br/deep-learning-oquee-como-funciona/cultura-analitica-redes-neurais-simples-profundas/
DENG, Jia et al. Imagenet: Um banco de dados de imagens hierárquicas em grande escala. In: 2009 Conferência IEEE sobre visão computacional e reconhecimento de padrões . Ieee,. p. 248-255. 2009
DETTMERS, Tim. Aprendizagem profunda em poucas palavras: Historia e Treinamento. Disponível em: https://devblogs.nvidia.com/deep-learning-nutshell-history-training/
FUKUSHIMA, Kunihiko. Neocognitron: Um modelo de rede neural auto-organizada para um mecanismo de reconhecimento de padrões não afetado pela mudança de posição. Cibernética biológica , v. 36, n. 4, p. 193-202, 1980.
GARTNER. Gartner diz que a AI Technologies estará em quase todos os novos produtos de software até 2020. Disponível em: https://www.gartner.com/en/newsroom/press-releases/2017-07-18-gartner-says-ai-technologies-will-be-in-almost-every-new-software-product-by-2020
GOODFELLOW, I; BENGIOo, Y; COURVILLE, A. Deep Learning. MIT Press. Disponível em: http://www.deeplearningbook.org
GRAVES, A. Sequence transduction with recurrent neural networks. arXiv preprint arXiv:1211.3711, 2012.
HOCHREITER, Sepp. O problema do gradiente de fuga durante a aprendizagem de redes neurais recorrentes e soluções de problemas. Revista Internacional de Incerteza, Fuzziness and Knowledge-Based Systems , v. 6, n. 02, p. 107-116, 1998.
HEBB, Donald O. The organization of behavior; a neuropsycholocigal theory. A Wiley Book in Clinical Psychology., p. 62-78, 1949.
HINTON, Geoffrey E; SALAKHUTDINOV, Ruslan R. Reduzindo a dimensionalidade dos dados com redes neurais. ciência , v. 313, n. 5786, p. 504-507, 2006.
HOCHREITER, Sepp; SCHMIDHUBER, Jürgen. Longa memória de curto prazo. Computação Neural, v. 9, n. 8, p. 1735-1780, 1997.
INTRODUCTION to artificial neural networks, Proceedings Electronic Technology Directions to the Year 2000, Adelaide, SA, Australia, 1995, pp. 36-62. Disponível em: https://ieeexplore.ieee.org/document/403491
KOROLEV, Dmitrii. Set of different neural nets. Neuron network. Deep learning. Cognitive technology concept. Vector illustration Disponível em: https://stock.adobe.com/br/images/set-of-different-neural-nets-neuron-network-deep-learning-cognitive-technology-concept-vector-illustration/145011568
LIU, C.; CAO, Y; LUO Y; CHEN, G; VOKKARANE, V, MA, Y; CHEN, S; HOU, P. A new Deep Learning-based food recognition system for dietary assessment on an edge computing service infrastructure. IEEE Transactions on Services Computing, PP(99):1–13. 2017
LORENA, Ana Carolina; DE CARVALHO, André CPLF. Uma introdução às support vector machines. Revista de Informática Teórica e Aplicada, v. 14, n. 2, p. 43-67, 2007.
MARVIN, Minsky; SEYMOUR, Papert. Perceptrons. 1969. Disponível em: http://134.208.26.59/math/AI/AI.pdf
MCCULLOCH, Warren S; PITTS, Walter. Um cálculo lógico das idéias imanentes na atividade nervosa. O boletim de biofísica matemática, v. 5, n. 4, p. 115-133, 1943.
NIELSEN, Michael. How the backpropagation algorithm works. 2018. Disponível em: http://neuralnetworksanddeeplearning.com/chap2.html
NIPS. 2009. Disponível em: http://media.nips.cc/Conferences/2009/NIPS-2009-Workshop-Book.pdf
PANG, Y; SUN, M; JIANG, X; LI, X.. Convolution in convolution for network in network. IEEE Transactions on Neural Networks and Learning Systems, PP(99):1–11. 2017
SANTANA, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponível em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
UDACITY. Conheça 8 aplicações de Deep Learning no mercado. Disponível em: https://br.udacity.com/blog/post/aplicacoes-deep-learning-mercado
YANG, S; LUO, P; LOY, C.C; TANG, X. From facial parts responses to face detection: A Deep Learning approach. In Proceedings of 2015 IEEE International Conference on Computer Vision (ICCV), pages 3676–3684. 2015
- Liu, C., Cao, Y., Luo, Y., Chen, G., Vokkarane, V., Ma, Y., Chen, S., and Hou, P. (2017). A new Deep Learning-based food recognition system for dietary assessment on an edge computing service infrastructure. IEEE Transactions on Services Computing, PP(99):1–13.
- Yang, S., Luo; P., Loy, C.-C; Tang, X. From facial parts responses to face detection: A Deep Learning approach. In Proceedings of 2015 IEEE International Conference on Computer Vision (ICCV), p. 3676
- Chung, J; Gulcehre, C; Cho, K; Bengio, Y. Gated feedback recurrent neural networks. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, volume 37 of ICML, p. 2069
- PANG, Y; Sun, M., Jiang, X., and Li, X. (2017). Convolution in convolution for network in network. IEEE Transactions on Neural Networks and Learning Systems, PP(99):5. 2017 ↑
- Goodfellow, I., Bengio, Y., and Courville, A. Deep Learning. MIT Press. http://www.deeplearningbook.org.
- GRAVES, A. Sequence transduction with recurrent neural networks. arXiv preprint arXiv:1211.3711, 2012.
- GARTNER. Gartner diz que a AI Technologies estará em quase todos os novos produtos de software até 2020. Disponível em: https://www.gartner.com/en/newsroom/press-releases/2017-07-18-gartner-says-ai-technologies-will-be-in-almost-every-new-software-product-by-2020
- MCCULLOCH, Warren S; PITTS, Walter. Um cálculo lógico das idéias imanentes na atividade nervosa. O boletim de biofísica matemática , v. 5, n. 4, p. 115-133, 1943.
- HEBB, Donald O. The organization of behavior; a neuropsycholocigal theory. A Wiley Book in Clinical Psychology., p. 62-78, 1949.
- BITTENCOURT, Guilherme. Breve história da Inteligência Artificial. 2001.p. 24
- Idbiem p. 25
- MARVIN, Minsky; SEYMOUR, Papert. Perceptrons. 1969. Disponível em: http://134.208.26.59/math/AI/AI.pdf
- Introduction to artificial neural networks," Proceedings Electronic Technology Directions to the Year 2000, Adelaide, SA, Australia, 1995, pp. 36-62. Disponível em: https://ieeexplore.ieee.org/document/403491
- BITTENCOURT, Guilherme op cit. p. 32
- NIELSEN, Michael. How the backpropagation algorithm works. 2018. Disponível em: http://neuralnetworksanddeeplearning.com/chap2.html
- HINTON, Geoffrey E; SALAKHUTDINOV, Ruslan R. Reduzindo a dimensionalidade dos dados com redes neurais. ciência , v. 313, n. 5786, p. 504-507, 2006.
- NIPS. 2009. Disponível em: http://media.nips.cc/Conferences/2009/NIPS-2009-Workshop-Book.pdf
- Santana, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponivel em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
- SANTANA, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponível em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
- idem
- UDACITY. Conheça 8 aplicações de Deep Learning no mercado. Disponível em: https://br.udacity.com/blog/post/aplicacoes-deep-learning-mercado
- Dettmers, Tim. Aprendizagem profunda em poucas palavras: Historia e Treinamento. Disponível em: https://devblogs.nvidia.com/deep-learning-nutshell-history-training/
- FUKUSHIMA, Kunihiko. Neocognitron: Um modelo de rede neural auto-organizada para um mecanismo de reconhecimento de padrões não afetado pela mudança de posição. Cibernética biológica , v. 36, n. 4, p. 193-202, 1980.
- LORENA, Ana Carolina; DE CARVALHO, André CPLF. Uma introdução às support vector machines. Revista de Informática Teórica e Aplicada, v. 14, n. 2, p. 43-67, 2007.
- HOCHREITER, Sepp; SCHMIDHUBER, Jürgen. Longa memória de curto prazo. Computação Neural, v. 9, n. 8, p. 1735-1780, 1997.
- HOCHREITER, Sepp. O problema do gradiente de fuga durante a aprendizagem de redes neurais recorrentes e soluções de problemas. Revista Internacional de Incerteza, Fuzziness and Knowledge-Based Systems , v. 6, n. 02, p. 107-116, 1998.
- DENG, Jia et al. Imagenet: Um banco de dados de imagens hierárquicas em grande escala. In: 2009 Conferência IEEE sobre visão computacional e reconhecimento de padrões . Ieee, 2009. p. 248-255.
- MCCULLOCH, Warren S.; PITTS, Walter. Um cálculo lógico das idéias imanentes na atividade nervosa. O boletim de biofísica matemática , v. 5, n. 4, p. 115-133, 1943.
- SANTANA, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponivel em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
- ALIGER. Saiba o que é visão computacional e como ela pode ser usada. 2018. Disponível em: https://www.aliger.com.br/blog/saiba-o-que-e-visao-computacional/
[1] Bachelor of Business Administration.
Inviato: maggio, 2019
Approvato: maggio, 2019