ORIGINAL-ARTIKEL
CHAGAS, Edgar Thiago De Oliveira [1]
CHAGAS, Edgar Thiago De Oliveira. Deep Learning und seine Anwendungen heute. Revista Científica Multidisciplinar Núcleo do Conhecimento. 04-Jahr, Ed. 05, Bd. 04, S. 05-26 Mai 2019. ISSN: 2448-0959
ZUSAMMENFASSUNG
Künstliche Intelligenz ist kein Plot mehr für Spielfilme. Die Forschung auf diesem Gebiet nimmt täglich zu und gibt neue Einblicke in das maschinelle Lernen. Tiefe Lernmethoden, auch Deep Learning genannt, werden derzeit an vielen Fronten eingesetzt, etwa an der Gesichtserkennung in sozialen Netzwerken, automatisierten Autos und sogar einigen Diagnosen im Bereich der Medizin. Deep Learning ermöglicht es Computermodellen, die sich aus unzähligen Verarbeitungsschichten zusammensetzen, Daten mit unterschiedlichen Abstraktionsstufen zu "erlernen". Diese Methoden verbesserten die Spracherkennung, visuelle Objekte, Objekterkennung, unter den Möglichkeiten. Diese Technologie ist jedoch noch immer schlecht bekannt, und der Zweck dieser Studie ist es, zu klären, wie Deep Learning funktioniert und seine aktuellen Anwendungen zu demonstrieren. Natürlich kann mit der Verbreitung dieses Wissens das tiefe Lernen in naher Zukunft andere Anwendungen darstellen, die für die gesamte Menschheit noch wichtiger sind.
Stichworte: Deep Learning, Machine Learning, IA, Machine Learning, Intelligence.
EINFÜHRUNG
Tiefes Lernen wird als ein Zweig des maschinellen Lernens verstanden, der auf einer Gruppe von Algorithmen basiert, die versuchen, hochgradige Abstraktionen von Daten mit einem tiefen Diagramm mit mehreren Schichten der Verarbeitung zu formen, Bestehend aus mehreren linearen und nichtlinearen Veränderungen.
Deep Learning arbeitet das Computersystem, um Aufgaben wie Spracherkennung, Bildentifikation und Projektion zu erfüllen. Anstatt die Informationen zu organisieren, um durch vorgegebene Gleichungen zu handeln, bestimmt dieses Lernen die grundlegenden Muster dieser Informationen und lehrt Computer, sich durch die Identifizierung von Mustern in Verarbeitungsschichten zu entwickeln.
Diese Art des Lernens ist ein umfassender Zweig von maschinellen Lernmethoden, die auf Lerndarstellungen von Informationen basieren. In diesem Sinne ist Deep Learning eine Reihe von Lernmaschinen-Algorithmen, die versuchen, mehrere Ebenen zu integrieren, die anerkannte statistische Modelle sind, die verschiedenen Definitionsebenen entsprechen. Niedrigere Niveaus helfen, viele Vorstellungen von höheren Ebenen zu definieren.
In diesem Bereich der künstlichen Intelligenz gibt es unzählige aktuelle Forschungen. Die Verbesserung der Deep Learning-Techniken hat eine Verbesserung der Fähigkeit von Computern, zu verstehen, was gefordert wird, ermöglicht. Die Forschung auf diesem Gebiet zielt darauf ab, bessere Darstellungen und ausgeklügelte Modelle zu fördern, um diese Darstellungen aus Informationen zu identifizieren, die nicht in großem Maßstab gekennzeichnet sind, einige als Grundlage in den Erkenntnissen der Neurowissenschaften und in der Interpretation von Datenverarbeitung und Kommunikationsmuster im Nervensystem. Seit 2006 hat sich diese Art des Lernens zu einem neuen Zweig der maschinellen Lernforschung entwickelt[2].
In jüngster Zeit wurden neue Techniken aus Deep Learning entwickelt, die sich auf mehrere Studien zur Signalverarbeitung und Musteridentifikation ausgewirkt haben. Beachten Sie eine Reihe neuer problematischer Befehle, die durch diese Techniken gelöst werden können, einschließlich Machine Learning und künstliche Intelligenz Schlüsselpunkte.
Laut Yang et al. wird die Aufmerksamkeit der Medien auf die in die[3]sem Bereich erzielten Fortschritte sehr groß gemacht. Große Technologieorganisationen haben viele Investitionen in die Tiefenlernforschung und ihre neuen Anwendungen getätigt.
Deep Learning umfasst das Lernen auf verschiedenen Ebenen der Repräsentation und Unverstehlichkeit, die dabei helfen, Informationen, Bilder, Klänge und Texte zu verstehen.
Unter den Ausstellungen, die über das Tiefenlernen zur Verfügung stehen, ist es möglich, zwei markante Punkte zu identifizieren. Die erste zeigt, dass es sich um Modelle handelt, die von unzähligen Schichten oder Schritten der nichtlinearen Datenverarbeitung gebildet werden und auch überwachte Lernpraktiken sind oder nicht, von der Darstellung von Zuschreibungen in späteren und immateriellen Schichten.
Es versteht sich, dass Deep Learning in den Fugen zwischen den Zweigen der neuronalen Netzwerkforschung, KI, grafischen Modellierung, Identifizierung und Optimierung von Mustern und Signalverarbeitung steckt. Die Aufmerksamkeit, die dem tiefen Lernen gewidmet wird, ist auf die Verbesserung der Chip-Verarbeitungsfähigkeit, die erhebliche Vergrößerung der Informationen, die für die Ausbildung verwendet werden, und die jüngsten Fortschritte in den Studien zum maschinellen Lernen und Verarbeiten zurückzuführen. Signale.
Dieser Fortschritt ermöglichte es Tiefenlernpraktiken, komplexe und nicht-lineare Anwendungen effektiv zu nutzen, Darstellungen von verteilten und hierarchischen Ressourcen zu identifizieren und die effektive Nutzung von Beschriftete und nicht beschriftete Informationen.[4]
Deep Learning bezieht sich auf eine umfassende Klasse von Methoden und Projekten des maschinellen Lernens, die die Eigenschaft zusammenführen, viele Schichten von nicht-linear verarbeiteten Daten hierarchischer Natur zu verwenden. Durch den Einsatz dieser Methoden und Projekte kann ein großer Teil der Studien in diesem Bereich in drei Hauptsätze eingeteilt werden, so Pang [5]et al, die die tiefen Netzwerke für unbeaufsichtigtes Lernen sind; Betreut und hybride.
Tiefe Netzwerke für unbeaufsichtigtes Lernen stehen zur Verfügung, um die hohe Sequenzkorrelation der analysierten oder identifizierbaren Informationen zur Überprüfung oder Assoziation von Standards zu erfassen, wenn keine Daten über die Stereotypen der Klassen vorliegen. In der Datenbank verfügbar. Das Erlernen der Zuordnung oder der unbeaufsichtigten Repräsentation bezieht sich auf tiefe Netzwerke. Außerdem können Sie nach der Zuordnung von gruppierten statistischen Distributionen der sichtbaren Daten und der damit verbundenen Klassen suchen, wenn sie verfügbar sind, und können als Teil der sichtbaren Daten abgedeckt werden.
Tiefe neuronale Netzwerke für überwachtes Lernen sollten Diskriminierungen der Klassifizierung von Mustern bieten, in der Regel Individualisierung der nachfolgenden Verteilung von Klassen mit den sichtbaren Informationen, die immer Verfügbar für dieses betreute Lernen, auch als tiefe diskriminierende Netzwerke bezeichnet.
Die tiefen hybriden Netze werden durch die Diskriminierung hervorgehoben, die mit den Ergebnissen generativer oder unbeaufsichtigter tiefer Netzwerke identifiziert wird, die durch die Verbesserung und die Regularisierung der tief überwachten Netze erreicht werden können. Seine Zuschreibungen können auch erreicht werden, wenn die diskriminierenden Richtlinien für überwachtes Lernen verwendet werden, um Standards in einem generativen oder unbeaufsichtigten tiefen Netzwerk zu bewerten[6].
Die tiefen und wiederkehrenden Netzwerke sind Modelle, die eine hohe Leistung in Fragen der Identifizierung fragwürdiger Muster in Ivain und Sprache darstelle[7]n. Trotz seiner Repräsentationskraft besteht die große Schwierigkeit, tiefe neuronale Netzwerke mit generischem Einsatz zu formen, bis heute. In Bezug auf die wiederkehrenden neuronalen Netzwerke initiierten Studien [8]von Hinton et al. das Formeln in Schichten.
Die vorliegende Studie zielt darauf ab, den Fortschritt des Deep Learning und seine Anwendungen nach den neuesten Forschungsergebnissen zu klären. Dazu wird eine qualitative beschreibende Recherche durchgeführt, bei der Bücher, Thesen, Artikel und Webseiten konzeptionell die Fortschritte im Bereich der künstlichen Intelligenz und insbesondere im tiefen Lernen durchgeführt werden.
Seit dem letzten Jahrzehnt wächst das Interesse am maschinellen Lernen, da es eine immer größere Interaktion zwischen Anwendungen, ob mobile oder Computergeräte, mit Einzelpersonen, durch Programme zur Erkennung von Spam gibt, Anerkennung in Fotos auf sozialen Netzwerken, Smartphones mit Gesichtserkennung, unter anderem. Laut Gartner werde[9]n alle Unternehmensprogramme bis zum Jahr 2020 mit dem maschinellen Lernen verbunden sein. Diese Elemente versuchen, die Ausarbeitung dieser Studie zu rechtfertigen.
HISTORICAL DEVELOPMENT DER DEEP LEARNING
Künstliche Intelligenz ist keine neue Entdeckung. Es stammt aus dem Jahrzehnt 1950, aber trotz der Entwicklung seiner Struktur, fehlten einige Aspekte der Glaubwürdigkeit. Ein solcher Aspekt ist das Volumen der Daten, die in einer großen Vielfalt und Geschwindigkeit entstanden sind, so dass die Schaffung von Standards mit hoher Genauigkeit. Ein relevanter Punkt war jedoch, wie große maschinelle Lernmodelle mit großen Mengen an Informationen verarbeitet wurden, weil Computer solche Maßnahmen nicht durchführen konnten.
In diesem Moment wurde der zweite Aspekt, der sich auf die parallele Programmierung in GPUs bezog, identifiziert. Die grafischen Verarbeitungseinheiten, die die Realisierung von mathematischen Operationen parallel ermöglichen, insbesondere solche mit Matrizen und Vektoren, die in Modellen künstlicher Netzwerke vorhanden sind, ermöglichten die aktuelle Entwicklung, d.h. die Big Data Summation (großes Datenvolumen); Parallel Verarbeitungs-und Maschinenlernmodelle präsentieren sich als Ergebnis künstliche Intelligenz.
Die Grundeinheit eines künstlichen neuronalen Netzwerkes ist ein mathematisches Neuron, auch Knoten genannt, basierend auf dem biologischen Neuron. Die Verbindungen zwischen diesen mathematischen Neuronen sind mit denen des biologischen Gehirns verbunden, und vor allem in der Art und Weise, wie sich diese Assoziationen im Laufe der Zeit entwickeln, genannt "Ausbildung".
Zwischen der zweiten Hälfte des Jahrzehnts von 80 und dem Beginn des Jahrzehnts von 90, gab es mehrere relevante Fortschritte in der Struktur der künstlichen Netze. Die Menge an Zeit und Informationen, die benötigt wurden, um gute Ergebnisse zu erzielen, hinauszögten jedoch die Annahme, was das Interesse an künstlicher Intelligenz beeinflusste.
In den frühen 2000 Jahren expandierte die Rechenleistung und der Markt erlebte einen "Boom" an Computertechniken, der vorher nicht möglich war. Es war, als Deep Learning aus dem großen rechnerischen Wachstum jener Zeit als wesentlicher Mechanismus für die Entwicklung künstlicher Intelligenzsysteme hervorging und mehrere Wettbewerbe des Maschinenlernens gewann. Das Interesse am Tiefenlernen wächst bis heute und es entstehen immer mehrere kommerzielle Lösungen.
Im Laufe der Zeit wurden mehrere Forschungen erstellt, um die Gehirnfunktion zu simulieren, insbesondere während des Lernprozesses, um intelligente Systeme zu schaffen, die Aufgaben wie Klassifizierung und Mustererkennung nachbilden könnten, unter Weitere Aktivitäten. Die Schlussfolgerungen dieser Studien ergaben das Modell des künstlichen Neurons, das später in einem vernetzten Netzwerk namens neuronales Netzwerk platziert wurde.
1943 erstellten Warren McCulloch, Neurophysiologe, und Walter Pitts, Mathematiker, ein einfaches neuronales Netzwerk mit elektrischen Schaltkreisen und entwickelten ein Computermodell für neuronale Netzwerke, das auf mathematischen Konzepten und Algorithmen basiert, die Schwelle genannt werden. Logik oder Schwellenlogik, die die Forschung an dem neuronalen Netzwerk ermöglichte, die in zwei Stränge unterteilt sind: Die Konzentration auf den biologischen Prozess des Gehirns und eine weitere, die sich auf die Anwendung dieser neuronalen Netzwerke konzentrierte, die auf künstliche Intelligenz abzielen.[10]
Donald Hebb[11] schrieb 1949 ein Werk, in dem er berichtete, dass neuronale Schaltkreise verstärkt werden, je mehr sie genutzt werden, als Essenz des Lernens. Mit der Weiterentwicklung der Computer im Jahr 1950 gewann die Idee eines neuronalen Netzwerks an Stärke und Na[12]thanial Rochester aus IBM-Studienabors versuchte, eine zu bilden, gelang aber nicht.
Das Sommerforschungsprojekt von Dartmouth übe[13]r Künstliche Intelligenz im Jahr 1956 förderte die neuronalen Netzwerke sowie die künstliche Intelligenz und förderte die Forschung in diesem Bereich in Bezug auf die neuronale Verarbeitung. In den folgenden Jahren imitierte John Von Neumann einfache Funktionen von Neuronen mit Vakuumröhren oder Telegrafen, während Frank Rosenblatt das Perceptron-Projekt initiierte und die Funktionsweise des Auges einer Fliege analysierte. Das Ergebnis dieser Forschung war eine Hardware, die das älteste neuronale Netzwerk ist, das bis heute genutzt wird. Das Perceptron ist jedoch sehr begrenzt, was Marvin und Papert bewiesen haben.[14]
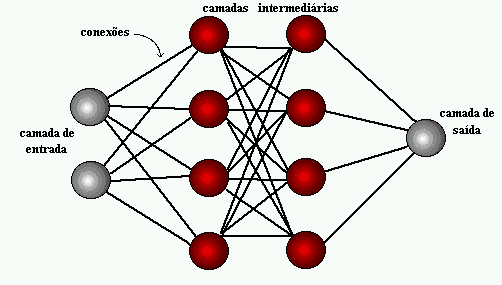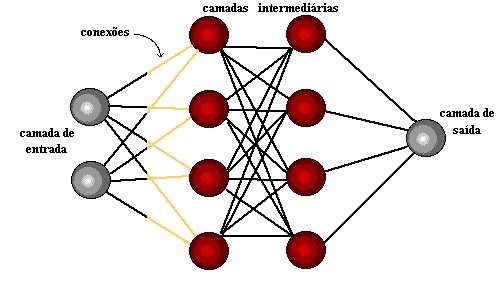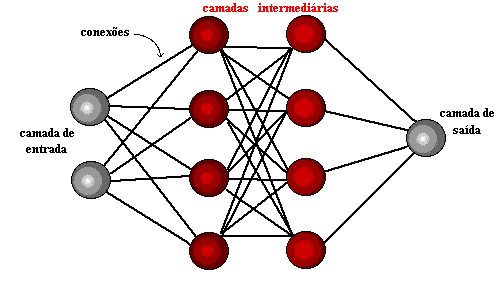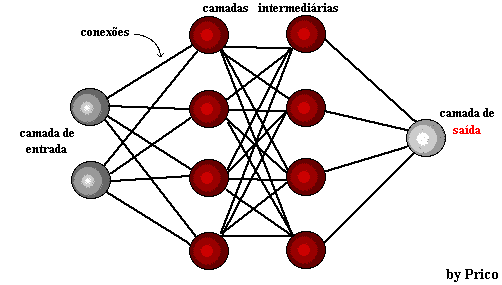
Bild 1: Neuronale Netzstruktur
Ein paar Jahre später, 1959, entwickelten Bernard Widrow und Marcian Hoff zwei Modelle mit den Namen "Adaline" und "Madaline". Die Nomenklatur leitet sich von der Verwendung mehrerer Elemente ab: ADAptive LINear. Adaline wurde erstellt, um binäre Muster zu identifizieren, um Vorhersagen über das nächste Bit zu machen, während "Madaline" das erste neuronale Netzwerk war, das auf ein echtes Problem angewendet wurde, mit einem adaptiven Filter. Das System ist noch im Einsatz, aber nur kommerziell.[15]
Die zuvor erzielten Fortschritte führten zu der Überzeugung, dass sich das Potenzial neuronaler Netzwerke auf die Elektronik beschränkte. Es wurde über die Auswirkungen befragt, die "intelligente Maschinen" auf den Menschen und die Gesellschaft insgesamt haben würden.
Die Debatte darüber, wie sich Künstliche Intelligenz auf den Menschen auswirken würde, übte Kritik an der Forschung in neuronalen Netzwerken, die zu einer Kürzung der Finanzierung führte, und folglich Studien in der Region, die bis 1981 blieben.
Im darauffolgenden Jahr wecken mehrere Veranstaltungen wieder Interesse auf diesem Gebiet. John Hopfield von Caltech präsentierte einen Ansatz, um nützliche Geräte zu erstellen und seine Aufgaben zu demonstriere[16]n. 1985 begann das American Institute of Physics ein jährliches Treffen mit dem Titel Neural Networks for Computation. 1986 begannen die Medien, über die neuronalen Netzwerke mehrerer Schichten zu berichten, und drei Forscher präsentierten ähnliche Ideen, Backpropagationsnetzwerke genannt, weil sie Muster identifizieren Ausfälle über das Netzwerk verteilen.
Die Hybrid-Netzwerke verfügten nur über zwei Schichten, während die Backpropagationsnetz[17]werke viele präsentieren, so dass dieses Netzwerk die Informationen langsamer behält, weil sie Tausende von Iterationen benötigen, um zu lernen, aber auch mehr Ergebnisse präsentieren. Genau. Bereits 1987 fand die erste internationale Konferenz zum Thema Neuralnetze des Instituts für Elektro-und Elektronik-Ingenieure (IEEE) statt.
Im Jahr 1989 schufen Wissenschaftler Algorithmen, die tiefe neuronale Netzwerke nutzten, aber die Zeit des "Lernens" war sehr lang, was ihre Anwendung auf die Realität verhinderte. 1992 wurde Juyang Weng Diulga Die Cresceptron-Methode, um die Erkennung von 3D-Objekten aus turbulenten Szenen durchzuführen.
In der Mitte 2000 Jahre beginnt der Begriff "Deep Learning" oder "Deep Learning" nach einem Artikel von Geoffrey Hinton und Ruslan Salakhutdinov verbreitet zu [18]werden, der zeigte, wie ein vielschichtiges neuronales Netzwerk zuvor trainiert werden konnte, eine Schicht nach der anderen .
Im Jahr 2009 findet der Neural Network Systemverarbeitung Workshop zum Tiefenlernen für Spracherkennung statt, und es wird bestätigt, dass neuronale Netzwerke bei einer umfangreichen Datengruppe keine vorherige Schulung benötigen und die Ausfallraten sinken. vielsagen[19]d.
Im Jahr 2012 lieferten die Recherchen Identifikationsalgorithmen künstlicher Muster mit menschlicher Leistung in einigen Aufgaben. Und der Google-Algorithmus identifiziert Katzen.
2015 nutzt Facebook Deep Learning, um Nutzer in Fotos automatisch zu markieren und zu erkennen. Die Algorithmen führen mit tiefen Netzwerken Gesichtserkennungsaufgaben durch. Im Jahr 2017 gab es eine groß angelegte Verabschiedung des Tiefenlernens in verschiedenen Geschäftsanwendungen und mobilen Geräten sowie Fortschritte in der Forschun[20]g.
Deep Learning hat es sich zur Aufgabe gemacht, zu zeigen, dass ein ziemlich umfangreiches Datenangebot, schnelle Prozessoren und ein ziemlich ausgeklügelter Algorithmus es Computern ermöglichen, Aufgaben wie das Erkennen von Bildern und Sprache zu erfüllen, unter anderem Möglichkeiten.
Die Forschung an neuronalen Netzwerken hat an Bedeutung gewonnen mit vielversprechenden Zuschreibungen, die von den neuronalen Netzwerkmodellen präsentiert werden, die aufgrund der jüngsten technologischen Innovationen der Umsetzung, die es ermöglichen, kühne neuronale Strukturen zu entwickeln Parallel zur Hardware, die zufriedenstellende Leistung dieser Systeme, mit überlegener Leistung als herkömmliche Systeme, einschließlich. Die Entwicklung neuronaler Netzwerke ist Deep Learning.
DEEP LEARNING
Es ist zunächst an, künstliche Intelligenz, maschinelles Lernen und tiefes Lernen zu differenzieren.
Abbildung 2: Künstliche Intelligenz, maschinelles Lernen und tiefes Lernen
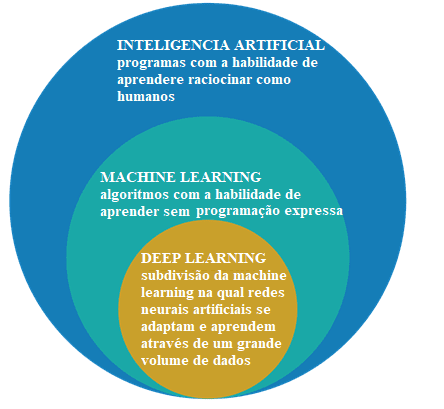
Das Forschungsgebiet der künstlichen Intelligenz ist die Erforschung und Gestaltung intelligenter Quellen, also eines Systems, das Entscheidungen treffen kann, die auf einem Merkmal basieren, das als intelligent gilt. In der künstlichen Intelligenz gibt es mehrere Methoden, die diese Eigenschaft modellieren und unter ihnen ist die Sphäre des maschinellen Lernens, wo Entscheidungen (Intelligenz) auf der Grundlage von Beispielen getroffen werden und nicht eine bestimmte Programmierung.
Maschinenlernalgorithmen benötigen Informationen, um Funktionen und Lernfunktionen zu entfernen, die für zukünftige Entscheidungen verwendet werden können. Deep Learning ist eine Untergruppe von maschinellen Lerntechniken, die in der Regel tiefe neuronale Netzwerke nutzen und eine große Menge an Informationen für die Ausbildung benötigen[21].
Laut Santana gibt es e[22]inige Unterschiede zwischen den Techniken des maschinellen Lernens und den Methoden des Deep Learning, und die wichtigsten sind die Notwendigkeit und die Auswirkungen von Datenvolumen, Rechenleistung und Flexibilität bei der Modellierung von Problemen.
Machine Learning benötigt Daten, um Muster zu identifizieren, aber es gibt zwei Probleme in Bezug auf die Daten, die sich auf die Dimensionalität und Stagnation der Leistung beziehen, indem mehr Daten über die verhaltene Grenze hinaus eingeführt werden. Es wird nachgewiesen, dass es eine Verringerung der signifikanten Leistung, wenn dies geschieht. In Bezug auf die Dimensionalität tritt das gleiche auf, da es viele Informationen gibt, die durch die klassischen Techniken die Dimension des Problems erkennen können.
Abbildung 3: Vergleich des tiefen Lernens mit anderen Algorithmen über die Datenmenge.
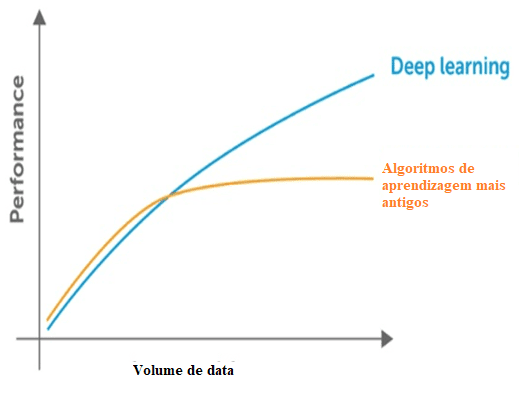
Die klassischen Techniken stellen auch einen Sättigungspunkt in Bezug auf die Datenmenge dar, das heißt, haben eine maximale Grenze, um die Informationen zu extrahieren, die nicht mit tiefem Lernen auftreten, geschaffen, um mit einem großen Datenvolumen zu arbeiten.
In Bezug auf die Rechenleistung für das tiefe Lernen sind seine Strukturen komplex und erfordern für seine Ausbildung eine große Datenmenge, die ihre Abhängigkeit von einer großen Rechenleistung zur Umsetzung dieser Praktiken demonstriert. Während andere klassische Praxen als CPU viel Rechenleistung benötigen, sind Deep Learning-Techniken überlegen.
Die Suche nach parallelem Computing und der Verwendung von GPUs mit CUDA-Compute Unified Device Architecture oder Unified Computing Device Architecture hat Deep Learning initiiert, da es mit der Verwendung einer einfachen CPU nicht möglich war.
Im Vergleich mit der Ausbildung eines tiefen neuralen Netzwerks oder tiefem Lernen mit der Nutzung einer CPU stellt sich heraus, dass es auch bei längerem Training unmöglich wäre, zufriedenstellende Ergebnisse zu erzielen.
Deep Learning, auch bekannt als Deep Learning, ist ein Teil von Machine Learning, und es wendet Algorithmen an, um Daten zu verarbeiten und die Verarbeitung des menschlichen Gehirns zu reproduzieren.
Tiefes Lernen nutzt Schichten von mathematischen Neuronen, um Daten zu verarbeiten, Sprache zu identifizieren und Objekte zu erkennen. Die Daten werden durch jede Ebene übertragen, wobei die Ausgabe aus der vorherigen Ebene die Eingabe auf die nächste Ebene gewährt. Die erste Ebene in einem Netzwerk wird die Eingangsschicht genannt und die letzte ist die Eingangsschicht. Die Zwischenschichten werden versteckte Schichten genannt, und jede Schicht des Netzwerks wird durch einen einfachen und einheitlichen Algorithmus gebildet, der eine Art Aktivierungsfunktion umfasst.
Abbildung 4: Einfaches neuronales Netzwerk und tiefes neuronales Netzwerk oder Deep Learning
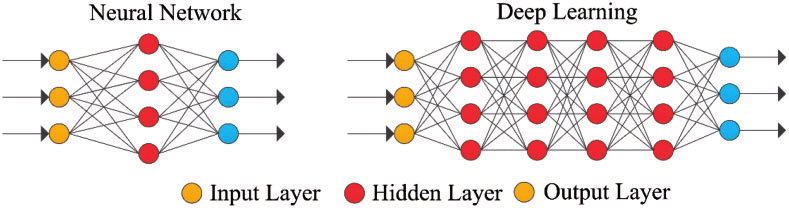
Die äußersten Schichten in Gelb sind die Eingangs-oder Ausgangsschichten, und die Zwischen-oder verborgenen Schichten sind rot. Deep Learning ist verantwortlich für die jüngsten Fortschritte in den Bereichen Computer, Spracherkennung, Sprachverarbeitung und auditive Identifikation, basierend auf der Definition von künstlichen neuronalen Netzwerken oder Computersystemen, die die Weise wirkt das menschliche Gehirn.
Ein weiterer Aspekt von Deep Learning ist die Gewinnung von Ressourcen, die mit einem Algorithmus automatisch relevante Parameter von Informationen für Training, Lernen und Verstehen erstellen, eine Aufgabe des künstlichen Intelligenzingenieurs.
Deep Learning ist eine Entwicklung neuronaler Netzwerke. Das Interesse am Tiefenlernen ist in den Medien allmählich gewachsen, und es wurden mehrere Forschungen in der Region verbreitet und ihre Anwendung hat Autos erreicht, unter anderem in der Diagnose von Krebs und Autismus[23]
Die ersten tiefen Lernalgorithmen mit mehreren Schichten nichtlinearer Zuordnungen präsentieren ihre Ursprünge in Alexey Grigoryevich Ivakhnenko, der die Methode der Datenmanipulation entwickelt hat, und Valentin Grigor ' Evich Lapa, Autor des Werkes Cybernetik und Prognosetechnik im Jahr 1965.[24]
Beide verwendeten dünne und tiefe Modelle mit polynomialen Aktivierungsfunktionen, die mit statistischen Methoden untersucht wurden. Durch diese Methoden wählten sie in jeder Schicht die besten Ressourcen aus und übertrugen sie auf die nächste Ebene, ohne dass die Backpropagation das gesamte Netzwerk "trainiert", sondern minimale Quadrate auf jeder Ebene verwendet wurden, von denen die vorherigen installiert wurden. Unabhängig in den späteren Schichten, manuell.
Abbildung 5: Struktur des ersten tiefen Netzwerkes, das als Alexej Grigorewitsch Ivakhnenko bekannt ist
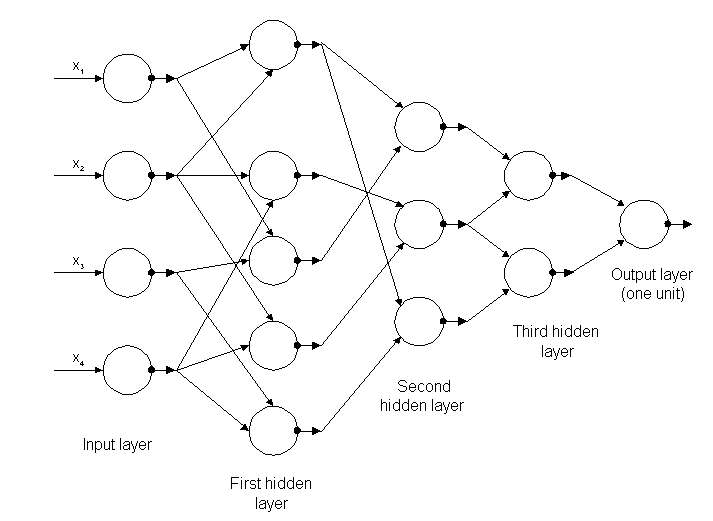
Am Ende des Jahrzehnts von 1970 ereignete sich der Winter der künstlichen Intelligenz, eine drastische Kürzung der Mittel für die Forschung zu diesem Thema. Die Auswirkungen haben die Fortschritte in tiefen neuronalen Netzwerken und Künstlicher Intelligenz begrenzt.
Die ersten konzernrechtlichen Netzwerke wurden 1979 von Kunihiko Fukushima mit mehreren Schichten von Gruppierungen und Konvolutionen genutzt. Er schuf ein künstliches neuronales Netzwerk, Neocognitron genannt, mit einem hierarchischen und mehrschichtigen Layout, das es dem Computer ermöglichte, visuelle Muster zu erkennen. Die Netzwerke ähnelten modernen Versionen, wobei sich "Training" auf die Strategie konzentrierte, die regelmäßige Aktivierung in unzähligen Schichten zu stärken. Darüber hinaus ermöglichte das Design von Fukushima die manuelle Anpassung der wichtigsten Ressourcen, indem die Bedeutung bestimmter Verbindungen erhöht wurd[25]e.
Viele Neocognitron-Richtlinien sind nach wie vor im Einsatz, da Top-Down-Verbindungen und neue Lernpraktiken die Realisierung verschiedener neuronaler Netzwerke gefördert haben. Wenn mehrere Muster gleichzeitig präsentiert werden, kann das selektive Pflegemodell sie trennen und die einzelnen Muster identifizieren, wobei auf jeden Wert geachtet wird. Ein aktuelleres Neocognitron kann Muster mit Datenmangel identifizieren und das Bild vervollständigen, indem es die fehlenden Informationen einfügt, die als Schlussfolgerung bezeichnet werden.
Die Backpropagation, die für das Deep Learning-Fehlertraining verwendet wurde, ging ab 1970 voran, als Seppo Linnainmaa eine Dissertation schrieb und einen FORTRAN-Code für die Backpropagation einfügte, ohne dass es bis 1985 gelang. Rumelhart, Williams und Hinton demonstrierten dann Backpropagierung in einem neuronalen Netzwerk mit Darstellungen der Verteilung.
Diese Entdeckung ermöglichte es der Debatte über die KI, die kognitive Psychologie zu erreichen, die Fragen nach dem menschlichen Verständnis und seiner Beziehung zur symbolischen Logik sowie Verbindungen anzogen. 1989 führte Yann LeCun eine praktische Demonstration der Backpropagation durch, mit der Kombination von konvolutionären neuronalen Netzwerken, um die schriftlichen Ziffern zu identifizieren.
In dieser Zeit gab es wieder einen Mangel an Mitteln für die Forschung in diesem Bereich, bekannt als der zweite Winter der IA, die zwischen 1985 und 1990 stattfand, auch Auswirkungen auf die Forschung in neuronalen Netzwerken und Deep Learning. Die Erwartungen einiger Forscher erreichten nicht das erwartete Niveau, was die Anleger zutiefst irritierte.
Im Jahr 1995 erstellten Dana Cortes und Vladimir Vapnik die unterstützende Vektormasch[26]ine oder die unterstützende Vektormaschine, die ein System zur Kartierung und Identifizierung ähnlicher Informationen war. Das Long Short Memory-LSTM für regelmäßige neuronale Netzwerke wurde 1997 von Sepp Hochreiter und Jürgen Schmidhuber erarbeite[27]t.
Der nächste Schritt in der Evolution des Deep Learning erfolgte 1999, als die Datenverarbeitung und die Grafikverarbeitung (GPUs) schneller wurden. Der Einsatz von GPUs und seine schnelle Verarbeitung bedeuteten eine Steigerung der Geschwindigkeit von Computern. Neuronale Netzwerke konkurrierten mit Support-Vektormaschinen. Das neuronale Netzwerk war langsamer als eine Stützvektormaschine, aber sie erzielten bessere Ergebnisse und entwickelten sich weiter, als mehr Trainingsinformationen hinzugefügt wurden.
Im Jahr 2000 wurde ein Problem mit dem Namen Vanishing Gradient festgestellt. Die in den unteren Schichten erlernten Aufgaben wurden nicht auf die oberen Schichten übertragen, es trat aber nur bei denen mit gradientbasierten Lernmethoden auf. Die Ursache des Problems lag in einigen Aktivierungsfunktionen, die ihre Eingabe, die den Ausgabebereich beeinflusste, reduzierten und große Eingabefelder erzeugten, die in einem sehr kleinen Bereich abgebildet waren, was zu einem sinkenden Farbverlauf führte. Die Lösungen, die zur Lösung des Problems implementiert wurden, waren die Pre-Workout-Schicht für Schicht und die Entwicklung eines Langzeit-und Kurzzeitgedächtnisse[28]s.
Im Jahr 2009 veröffentlichte Fei-Fei Li ImageN[29]et mit einer kostenlosen Datenbank von mehr als 14 Millionen Bildern, die sich auf die "Ausbildung" neuronaler Netzwerke konzentrierte und darauf hinwies, wie Big Data den Betrieb von Machine Learning beeinflussen würde.
Die Geschwindigkeit der GPUs, bis zum Jahr 2011, nahm weiter zu, so dass die Zusammensetzung der konvolutionären neuronalen Netze ohne die Notwendigkeit von Pre-Workout Schicht für Schicht. So wurde es berüchtigt, dass Deep Learning in Bezug auf Effizienz und Geschwindigkeit von Vorteil war.
In der heutigen Zeit sind die Big-Data-Verarbeitung und das Fortschreiten der künstlichen Intelligenz von Deep Learning abhängig, das intelligente Systeme entwickeln und die Schaffung einer vollständig autonomen künstlichen Intelligenz fördern kann, die einen Einfluss auf die Die ganze Gesellschaft.
FLEXIVILITÄT DER NEURAL NETWORKS UND THEIR APPLICATIONS
Trotz der Existenz von mehreren klassischen Techniken, der DEEP Learning Struktur und seiner grundlegenden Einheit, ist das Neuron generisch und sehr flexibel. Wenn wir einen Vergleich mit dem menschlichen Neuron machen, das Synapsen liefert, können wir einige Zusammenhänge zwischen ihnen erkennen.
Abbildung 6: Korrelation zwischen einem menschlichen Neuron und einem künstlichen neuronalen Netzwerk
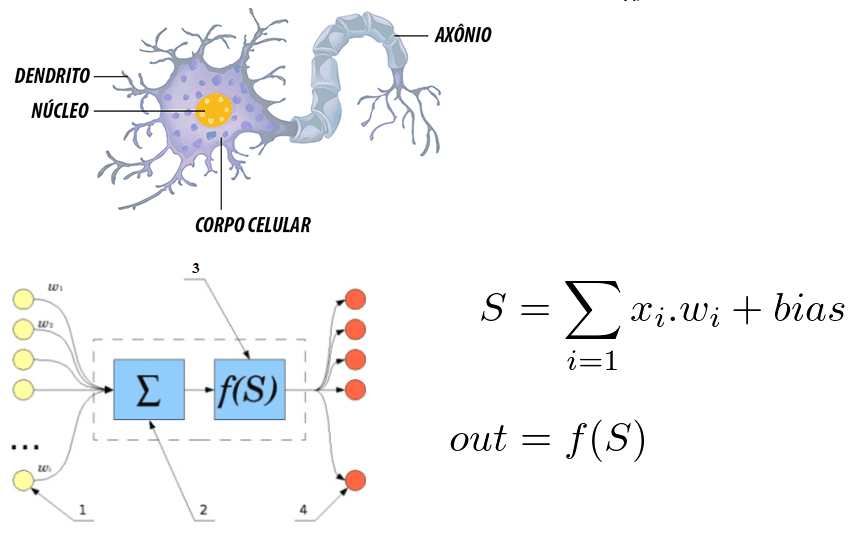
Es wird darauf hingewiesen, dass das Neuron durch die Dendriten gebildet wird, die die Einstiegspunkte sind, ein Kern, der in den künstlichen neuronalen Netzen den Verarbeitungskern und den Ausstiegspunkt darstellt, der durch das Axon repräsentiert wird. In beiden Systemen werden die Informationen eingegeben, verarbeitet und sich heraus.
Wenn man es als mathematische Gleichung betrachtet, reflektiert das Neuron die Summe der Eingänge, die mit Gewichten multipliziert werden, und dieser Wert geht durch eine Aktivierungsfunktion. Diese Summe wurde 1943 von McCulloch und Pitts aufgeführt[30]
In Bezug auf das berüchtigte Interesse an Deep Learning heutzutage, Santana ist[31] der Ansicht, dass es auf zwei Faktoren, die die Menge der verfügbaren Informationen und die Begrenzung der älteren Techniken neben der aktuellen Rechenleistung, um Netze zu trainieren sind, sind Komplex. Die Flexibilität, mehrere Neuronen in einem komplexeren Netzwerk miteinander zu verbinden, ist das Differential von DEEP Learning Strukturen. Ein konvolutionelles neuronales Netzwerk wird bei der Gesichtserkennung, Bilderkennung und Zuweisungsextraktion weit verbreitet.
Ein konventionelles neuronales Netzwerk besteht aus mehreren Schichten, den sogenannten Layers. Je nach zu lösenden Problem kann die Anzahl der Schichten variieren, wobei in der Lage, bis zu Hunderten von Schichten zu haben, wobei Faktoren, die in der Menge beeinflussen die Komplexität des Problems, Zeit und Rechenleistung
Es gibt mehrere verschiedene Strukturen mit zahllosen Zwecken, und ihre Funktionsweise hängt auch von der Struktur ab und alle basieren auf neuronalen Netzwerken.
Abbildung 7: Beispiele für neuronale Netzwerke
Diese architektonische Flexibilität ermöglicht es, verschiedene Probleme zu lösen. Deep Learning ist eine allgemeine objektive Technik, aber die fortschrittlichsten Bereiche waren: Computervision, Spracherkennung, natürliche Sprachverarbeitung, Empfehlungssysteme.
Das Rechenbild umfasst die Objekterkennung, die semantische Segmentierung, insbesondere autonome Autos. Es kann bestätigt werden, dass das Computer-Vision Teil der künstlichen Intelligenz ist und als eine Reihe von Wissen definiert wird, das künstliche Modellierung des menschlichen Sehens mit dem Ziel der Nachahmung seiner Funktionen durch die Entwicklung von Software und Hardware sucht. fortgeschritte[32]n.
Zu den Anwendungen der Rechenvision gehören der militärische Einsatz, der Marketingmarkt, die Sicherheit, die öffentlichen Dienstleistungen und der Produktionsprozess. Autonome Fahrzeuge stellen die Zukunft des sichereren Verkehrs dar, aber es befindet sich noch in der Testphase, da es mehrere Technologien umfasst, die auf eine Funktion angewendet werden. Die rechnerische Vision in diesen Fahrzeugen, da es die Erkennung des Weges und der Hindernisse ermöglicht, die Verbesserung der Routen.
Im Rahmen der Sicherheit wurden Gesichtserkennungssysteme zunehmend hervorgehoben, angesichts des Sicherheitsniveaus an öffentlichen und privaten Orten, die auch in mobilen Geräten umgesetzt werden. Ebenso können sie als Schlüssel für den Zugriff auf Finanztransaktionen dienen, während in sozialen Netzwerken, erkennt es die Anwesenheit des Nutzers oder seiner Freunde in Fotos.
In Bezug auf den Marketingmarkt wies eine von Image Intelligence entwickelte Studie darauf hin, dass 3 Milliarden Bilder täglich von sozialen Netzwerken geteilt werden und 80% Hinweise enthalten, die sich auf bestimmte Unternehmen beziehen, aber ohne textliche Referenzen. Spezialisierte Marketing-Unternehmen bieten Echtzeit-Überwachung und Management-Service. Mit der Computer-Vision-Technologie erreicht die Genauigkeit in der Bildentifikation 99%.
Im öffentlichen Dienst deckt er die Sicherheit des Standorts ab, indem er Kameras überwacht, den Fahrzeugverkehr durch stereoskopische Bilder, die das Sehsystem effizient machen.
Im Produktionsprozess setzen Unternehmen aus verschiedenen Branchen die Rechensicht als Qualitätsinstrument ein. In jeder Branche erhöht die fortschrittlichste Software, die mit der ständig steigenden Verarbeitungskapazität der Hardware verbunden ist, den Einsatz von Computervisionen.
Überwachungssysteme ermöglichen die Erkennung von vorgefertigten Standards und weisen auf Ausfälle hin, die beim Betrachten eines Mitarbeiters in der Produktionslinie nicht erkennbar wären. Im gleichen Zusammenhang wird das Ersatzautomatisierungsprojekt für die Bestandskontrolle eingesetzt. Eine Echtzeit-Inventar-und Verkaufssteuerung ermöglicht es der Technologie, den Betrieb eines Unternehmens zu steuern und so seinen Gewinn zu steigern. Es gibt weitere Anwendungen in den Bereichen Medizin, Bildung und E-Commerce.
Schlussfolgerungen
Die vorliegende Studie versuchte, aufzuklären, was Deep Learning ist, und seine Anwendungen in der heutigen Welt aufzuzeigen. Tiefe Lerntechniken schreiten vor allem durch den Einsatz mehrerer Schichten weiter voran. Allerdings gibt es immer noch Einschränkungen bei der Nutzung von tiefen neuronalen Netzwerken, da sie nur eine Möglichkeit sind, mehrere Änderungen zu lernen, die im Eingangsvektor implementiert werden sollen. Änderungen durch eine Reihe von Parametern, die in der Ausbildungszeit aktualisiert werden.
Es ist unbestreitbar, dass künstliche Intelligenz eine engere Realität ist, aber es fehlt noch ein langer Weg. Die Akzeptanz des tiefen Lernens in verschiedenen Wissensgebieten ermöglicht es der Gesellschaft, insgesamt von den Wundern der modernen Technik zu profitieren.
In Bezug auf die künstliche Intelligenz, wird überprüft, dass diese Technologie lernfähig ist, obwohl sehr wichtig ist, hat eine lineare und nicht formbare Natur als der Mensch, die ein großes Differential und wesentlich für einige Bereiche des Wissens, die Das lässt sich im Tiefenlernen noch nicht umsetzen.
In irgendeiner Weise wird der Einsatz der tiefen Lernmethoden die Maschinen in die Lage versetzen, die Gesellschaft bei verschiedenen Aktivitäten zu unterstützen, wie sie gezeigt werden, indem die kognitive Leistungsfähigkeit des Menschen erweitert wird und eine noch größere Entwicklung in diesen Bereichen des Wissens.
BIBLIOGRAPHISCHE HINWEISE
ALIGER. Saiba o que é visão computacional e como ela pode ser usada. 2018. Disponível em: https://www.aliger.com.br/blog/saiba-o-que-e-visao-computacional/
BITTENCOURT, Guilherme. Breve história da Inteligência Artificial. 2001
CARVALHO, André Ponce de L. Redes Neurais Artificiais. Disponível em: http://conteudo.icmc.usp.br/pessoas/andre/research/neural/
CHUNG, J; GULCEHE, C; CHO, K; BENGIO, Y. Gated feedback recurrent neural networks. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, volume 37 of ICML, pages 2067–2075. 2015
CULTURA ANALITICA. Entenda o que é deep learning e como funciona. Disponível em: https://culturaanalitica.com.br/deep-learning-oquee-como-funciona/cultura-analitica-redes-neurais-simples-profundas/
DENG, Jia et al. Imagenet: Um banco de dados de imagens hierárquicas em grande escala. In: 2009 Conferência IEEE sobre visão computacional e reconhecimento de padrões . Ieee,. p. 248-255. 2009
DETTMERS, Tim. Aprendizagem profunda em poucas palavras: Historia e Treinamento. Disponível em: https://devblogs.nvidia.com/deep-learning-nutshell-history-training/
FUKUSHIMA, Kunihiko. Neocognitron: Um modelo de rede neural auto-organizada para um mecanismo de reconhecimento de padrões não afetado pela mudança de posição. Cibernética biológica , v. 36, n. 4, p. 193-202, 1980.
GARTNER. Gartner diz que a AI Technologies estará em quase todos os novos produtos de software até 2020. Disponível em: https://www.gartner.com/en/newsroom/press-releases/2017-07-18-gartner-says-ai-technologies-will-be-in-almost-every-new-software-product-by-2020
GOODFELLOW, I; BENGIOo, Y; COURVILLE, A. Deep Learning. MIT Press. Disponível em: http://www.deeplearningbook.org
GRAVES, A. Sequence transduction with recurrent neural networks. arXiv preprint arXiv:1211.3711, 2012.
HOCHREITER, Sepp. O problema do gradiente de fuga durante a aprendizagem de redes neurais recorrentes e soluções de problemas. Revista Internacional de Incerteza, Fuzziness and Knowledge-Based Systems , v. 6, n. 02, p. 107-116, 1998.
HEBB, Donald O. The organization of behavior; a neuropsycholocigal theory. A Wiley Book in Clinical Psychology., p. 62-78, 1949.
HINTON, Geoffrey E; SALAKHUTDINOV, Ruslan R. Reduzindo a dimensionalidade dos dados com redes neurais. ciência , v. 313, n. 5786, p. 504-507, 2006.
HOCHREITER, Sepp; SCHMIDHUBER, Jürgen. Longa memória de curto prazo. Computação Neural, v. 9, n. 8, p. 1735-1780, 1997.
INTRODUCTION to artificial neural networks, Proceedings Electronic Technology Directions to the Year 2000, Adelaide, SA, Australia, 1995, pp. 36-62. Disponível em: https://ieeexplore.ieee.org/document/403491
KOROLEV, Dmitrii. Set of different neural nets. Neuron network. Deep learning. Cognitive technology concept. Vector illustration Disponível em: https://stock.adobe.com/br/images/set-of-different-neural-nets-neuron-network-deep-learning-cognitive-technology-concept-vector-illustration/145011568
LIU, C.; CAO, Y; LUO Y; CHEN, G; VOKKARANE, V, MA, Y; CHEN, S; HOU, P. A new Deep Learning-based food recognition system for dietary assessment on an edge computing service infrastructure. IEEE Transactions on Services Computing, PP(99):1–13. 2017
LORENA, Ana Carolina; DE CARVALHO, André CPLF. Uma introdução às support vector machines. Revista de Informática Teórica e Aplicada, v. 14, n. 2, p. 43-67, 2007.
MARVIN, Minsky; SEYMOUR, Papert. Perceptrons. 1969. Disponível em: http://134.208.26.59/math/AI/AI.pdf
MCCULLOCH, Warren S; PITTS, Walter. Um cálculo lógico das idéias imanentes na atividade nervosa. O boletim de biofísica matemática, v. 5, n. 4, p. 115-133, 1943.
NIELSEN, Michael. How the backpropagation algorithm works. 2018. Disponível em: http://neuralnetworksanddeeplearning.com/chap2.html
NIPS. 2009. Disponível em: http://media.nips.cc/Conferences/2009/NIPS-2009-Workshop-Book.pdf
PANG, Y; SUN, M; JIANG, X; LI, X.. Convolution in convolution for network in network. IEEE Transactions on Neural Networks and Learning Systems, PP(99):1–11. 2017
SANTANA, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponível em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
UDACITY. Conheça 8 aplicações de Deep Learning no mercado. Disponível em: https://br.udacity.com/blog/post/aplicacoes-deep-learning-mercado
YANG, S; LUO, P; LOY, C.C; TANG, X. From facial parts responses to face detection: A Deep Learning approach. In Proceedings of 2015 IEEE International Conference on Computer Vision (ICCV), pages 3676–3684. 2015
- Liu, C., Cao, Y., Luo, Y., Chen, G., Vokkarane, V., Ma, Y., Chen, S., and Hou, P. (2017). A new Deep Learning-based food recognition system for dietary assessment on an edge computing service infrastructure. IEEE Transactions on Services Computing, PP(99):1–13.
- Yang, S., Luo; P., Loy, C.-C; Tang, X. From facial parts responses to face detection: A Deep Learning approach. In Proceedings of 2015 IEEE International Conference on Computer Vision (ICCV), p. 3676
- Chung, J; Gulcehre, C; Cho, K; Bengio, Y. Gated feedback recurrent neural networks. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, volume 37 of ICML, p. 2069
- PANG, Y; Sun, M., Jiang, X., and Li, X. (2017). Convolution in convolution for network in network. IEEE Transactions on Neural Networks and Learning Systems, PP(99):5. 2017 ↑
- Goodfellow, I., Bengio, Y., and Courville, A. Deep Learning. MIT Press. http://www.deeplearningbook.org.
- GRAVES, A. Sequence transduction with recurrent neural networks. arXiv preprint arXiv:1211.3711, 2012.
- GARTNER. Gartner diz que a AI Technologies estará em quase todos os novos produtos de software até 2020. Disponível em: https://www.gartner.com/en/newsroom/press-releases/2017-07-18-gartner-says-ai-technologies-will-be-in-almost-every-new-software-product-by-2020
- MCCULLOCH, Warren S; PITTS, Walter. Um cálculo lógico das idéias imanentes na atividade nervosa. O boletim de biofísica matemática , v. 5, n. 4, p. 115-133, 1943.
- HEBB, Donald O. The organization of behavior; a neuropsycholocigal theory. A Wiley Book in Clinical Psychology., p. 62-78, 1949.
- BITTENCOURT, Guilherme. Breve história da Inteligência Artificial. 2001.p. 24
- Idbiem p. 25
- MARVIN, Minsky; SEYMOUR, Papert. Perceptrons. 1969. Disponível em: http://134.208.26.59/math/AI/AI.pdf
- Introduction to artificial neural networks," Proceedings Electronic Technology Directions to the Year 2000, Adelaide, SA, Australia, 1995, pp. 36-62. Disponível em: https://ieeexplore.ieee.org/document/403491
- BITTENCOURT, Guilherme op cit. p. 32
- NIELSEN, Michael. How the backpropagation algorithm works. 2018. Disponível em: http://neuralnetworksanddeeplearning.com/chap2.html
- HINTON, Geoffrey E; SALAKHUTDINOV, Ruslan R. Reduzindo a dimensionalidade dos dados com redes neurais. ciência , v. 313, n. 5786, p. 504-507, 2006.
- NIPS. 2009. Disponível em: http://media.nips.cc/Conferences/2009/NIPS-2009-Workshop-Book.pdf
- Santana, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponivel em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
- SANTANA, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponível em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
- idem
- UDACITY. Conheça 8 aplicações de Deep Learning no mercado. Disponível em: https://br.udacity.com/blog/post/aplicacoes-deep-learning-mercado
- Dettmers, Tim. Aprendizagem profunda em poucas palavras: Historia e Treinamento. Disponível em: https://devblogs.nvidia.com/deep-learning-nutshell-history-training/
- FUKUSHIMA, Kunihiko. Neocognitron: Um modelo de rede neural auto-organizada para um mecanismo de reconhecimento de padrões não afetado pela mudança de posição. Cibernética biológica , v. 36, n. 4, p. 193-202, 1980.
- LORENA, Ana Carolina; DE CARVALHO, André CPLF. Uma introdução às support vector machines. Revista de Informática Teórica e Aplicada, v. 14, n. 2, p. 43-67, 2007.
- HOCHREITER, Sepp; SCHMIDHUBER, Jürgen. Longa memória de curto prazo. Computação Neural, v. 9, n. 8, p. 1735-1780, 1997.
- HOCHREITER, Sepp. O problema do gradiente de fuga durante a aprendizagem de redes neurais recorrentes e soluções de problemas. Revista Internacional de Incerteza, Fuzziness and Knowledge-Based Systems , v. 6, n. 02, p. 107-116, 1998.
- DENG, Jia et al. Imagenet: Um banco de dados de imagens hierárquicas em grande escala. In: 2009 Conferência IEEE sobre visão computacional e reconhecimento de padrões . Ieee, 2009. p. 248-255.
- MCCULLOCH, Warren S.; PITTS, Walter. Um cálculo lógico das idéias imanentes na atividade nervosa. O boletim de biofísica matemática , v. 5, n. 4, p. 115-133, 1943.
- SANTANA, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponivel em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
- ALIGER. Saiba o que é visão computacional e como ela pode ser usada. 2018. Disponível em: https://www.aliger.com.br/blog/saiba-o-que-e-visao-computacional/
[1] Bachelor of Business Administration.
Eingereicht: Mai, 2019
Genehmigt: Mai 2019