ARTICLE ORIGINAL
CHAGAS, Edgar Thiago De Oliveira [1]
CHAGAS, Edgar Thiago De Oliveira. L’apprentissage profond et ses applications aujourd’hui. Revista Científica Multidisciplinar Núcleo do Conhecimento. 04 année, Ed. 05, vol. 04, pp. 05-26 mai 2019. ISSN: 2448-0959
RÉSUMÉ
L’intelligence artificielle n’est plus un complot pour les films de fiction. La recherche dans ce domaine augmente chaque jour et fournit de nouvelles informations sur l’apprentissage automatique. Les méthodes d’apprentissage profond, également connues sous le nom d’apprentissage profond, sont actuellement utilisées sur de nombreux fronts tels que la reconnaissance faciale dans les réseaux sociaux, les voitures automatisées et même certains Diagnostics dans le domaine de la médecine. Deep Learning permet aux modèles computationnels composés d’innombrables couches de traitement d’apprendre des représentations de données à différents niveaux d’abstraction. Ces méthodes améliorent la reconnaissance vocale, les objets visuels, la détection d’objets, entre les possibilités. Cependant, cette technologie est encore mal connue, et le but de cette étude est de clarifier comment Deep Learning fonctionne et de démontrer ses applications actuelles. Bien sûr, avec la diffusion de cette connaissance, l’apprentissage profond peut, dans un avenir proche, présenter d’autres applications, encore plus importantes pour toute l’humanité.
Mots-clés: apprentissage profond, machine learning, IA, machines Learning, intelligence.
INTRODUCTION
L’apprentissage profond est compris comme une branche de machine learning, qui est basée sur un groupe d’algorithmes qui cherchent à façonner des abstractions de haut niveau de données à l’aide d’un graphique profond avec plusieurs couches de traitement, Composé de plusieurs altérations linéaires et non linéaires.
Deep Learning travaille sur le système informatique pour effectuer des tâches telles que la reconnaissance vocale, l’identification de l’image et la projection. Plutôt que d’organiser l’information pour agir par des équations prédéterminées, cet apprentissage détermine les schémas de base de cette information et enseigne aux ordinateurs à se développer par l’identification des modèles dans les couches de traitement.
Ce type d’apprentissage est une branche complète des méthodes de machine learning basées sur l’apprentissage des représentations de l’information. En ce sens, Deep Learning est un ensemble d’algorithmes de machine d’apprentissage qui tentent d’intégrer plusieurs niveaux, qui sont des modèles statistiques reconnus qui correspondent à différents niveaux de définitions. Les niveaux inférieurs aident à définir de nombreuses notions de niveaux plus élevés.
Il existe d’innombrables recherches actuelles dans ce domaine de l’intelligence artificielle. L’amélioration des techniques d’apprentissage profond a mis en œuvre des améliorations dans la capacité des ordinateurs à comprendre ce qui est demandé. La recherche dans ce domaine vise à promouvoir de meilleures représentations et des modèles élaborés pour identifier ces représentations à partir d’informations non étiquetées à grande échelle, certaines comme base dans les résultats des neurosciences et dans l’interprétation de Traitement des données et schémas de communication dans le système nerveux. Depuis 2006, ce genre d’apprentissage est apparu comme une nouvelle branche de la recherche machine learnin[2]g.
Récemment, de nouvelles techniques ont été développées à partir de Deep Learning, qui ont influencé plusieurs études sur le traitement du signal et l’identification des patrons. Notez une série de nouvelles commandes problématiques qui peuvent être résolues grâce à ces techniques, y compris le machine learning et les points clés de l’intelligence artificielle.
Il y a beaucoup d’attention des médias, selon Yang et col[3]l., sur les progrès accomplis dans ce domaine. Les grandes entreprises de technologie ont appliqué de nombreux investissements dans la recherche en apprentissage profond et leurs nouvelles applications.
L’apprentissage profond englobe l’apprentissage à différents niveaux de représentation et d’intangibilité qui aident à comprendre l’information, les images, les sons et les textes.
Parmi les expositions disponibles sur l’apprentissage profond, il est possible d’identifier deux points frappants. La première montre qu’il s’agit de modèles formés par d’innombrables couches ou étapes de traitement de données non linéaires et sont également supervisés pratiques d’apprentissage ou non, de la représentation des attributions dans les couches ultérieures et intangibles.
Il est entendu que l’apprentissage profond est dans les articulations entre les branches de la recherche sur le réseau neuronal, l’IA, la modélisation graphique, l’identification et l’optimisation des modèles et le traitement du signal. L’attention accordée à l’apprentissage profond est due à l’amélioration de la compétence de traitement des copeaux, à l’augmentation considérable de la taille des informations utilisées pour la formation et aux récentes avancées dans les études de machine learning et de traitement des signaux.
Ces progrès ont permis aux pratiques d’apprentissage profond d’exploiter efficacement les applications complexes et non linéaires, d’identifier les représentations des ressources distribuées et hiérarchiques et de permettre l’utilisation efficace des Informations étiquetées et non étiquetées.[4]
L’apprentissage profond fait référence à une classe complète de méthodes et de projets de machine learning, qui réunissent la particularité d’utiliser de nombreuses couches de données non linéaires traitées de nature hiérarchique. En raison de l’utilisation de ces méthodes et projets, une grande partie des études dans ce domaine peut être classée en trois ensembles principaux, selon Pan[5]g et al, qui sont les réseaux profonds pour l’apprentissage non supervisé; Supervisé et hybride.
Des réseaux profonds pour l’apprentissage non supervisé sont disponibles pour appréhender la corrélation de séquence élevée des informations analysées ou identifiables pour la vérification ou l’Association de normes lorsqu’il n’y a pas de données sur les stéréotypes des classes Disponible dans la base de données. L’apprentissage de l’attribution ou de la représentation non supervisée fait référence à des réseaux profonds. En outre, vous pouvez rechercher l’affectation de distributions statistiques groupées des données visibles et de ses classes associées lorsqu’elles sont disponibles, et peuvent être couvertes dans le cadre des données visibles.
Les réseaux neuronaux profonds pour l’apprentissage supervisé devraient fournir une discrimination pour classer les schémas, habituellement individualisant les distributions ultérieures des classes liées à l’information visible, qui sont toujours Disponible pour cet apprentissage supervisé, également appelé réseaux discriminatifs profonds.
Les réseaux hybrides profonds sont mis en évidence par la discrimination identifiée par les résultats de réseaux profonds génératifs ou non supervisés, qui peuvent être obtenus grâce à l’amélioration et/ou à la régularisation des réseaux profonds supervisés. Ses attributions peuvent également être atteintes lorsque les lignes directrices discriminatoires pour l’apprentissage supervisé sont utilisées pour évaluer les normes dans tout réseau profond génératif ou non supervis[6]é.
Les réseaux profonds et récurrents sont des modèles qui présentent une haute performance dans les questions d’identification des schémas douteux dans Ivain et la parol[7]e. Malgré son pouvoir de représentation, la grande difficulté à façonner les réseaux neuronaux profonds avec une utilisation générique persiste jusqu’à nos jours. En ce qui concerne les réseaux neuronaux récurrents, des études menées par Hi[8]nton et al ont initié le moulage en couches.
La présente étude vise à clarifier les progrès de Deep Learning et de ses applications selon les recherches les plus récentes. Pour ce faire, une recherche descriptive qualitative sera menée, avec l’utilisation de livres, de thèses, d’articles et de sites Web pour conceptuellement les progrès dans le domaine de l’intelligence artificielle et en particulier dans l’apprentissage profond.
Il y a eu un intérêt croissant pour le machine learning depuis la dernière décennie, étant donné qu’il y a une interaction toujours croissante entre les applications, que ce soit des appareils mobiles ou informatiques, avec des individus, par le biais de programmes de détection de spam, Reconnaissance en photos sur les réseaux sociaux, smartphones avec reconnaissance faciale, entre autres applications. Selon Gartner, tous le[9]s programmes d’entreprise auront une certaine fonction liée à l’apprentissage machine jusqu’à l’année 2020. Ces éléments visent à justifier l’élaboration de cette étude.
DÉVELOPPEMENT HISTORIQUE DE L’APPRENTISSAGE PROFOND
L’intelligence artificielle n’est pas une découverte récente. Il vient de la décennie de 1950, mais malgré l’évolution de sa structure, certains aspects de la crédibilité manquaient. Un tel aspect est le volume de données, originaire de grande variété et de vitesse, permettant la création de normes avec des niveaux élevés de précision. Toutefois, un point pertinent portait sur la façon dont les grands modèles machine learning ont été traités avec de grandes quantités d’informations, car les ordinateurs n’ont pas pu effectuer une telle action.
À ce moment-là, le deuxième aspect de la programmation parallèle dans les GPU a été identifié. Les unités de traitement graphique, qui permettent la réalisation d’opérations mathématiques en parallèle, en particulier celles avec des matrices et des vecteurs, qui sont présents dans les modèles de réseaux artificiels, ont permis l’évolution actuelle, c’est-à-dire la Big Data Summation (volume de données volumineux); Les modèles de traitement parallèle et de machine learning présentent comme résultat une intelligence artificielle.
L’unité de base d’un réseau neuronal artificiel est un Neuron mathématique, également appelé un nœud, basé sur le Neuron biologique. Les liens entre ces neurones mathématiques sont liés à ceux des cerveaux biologiques, et surtout dans la façon dont ces associations se développent au fil du temps, appelé «formation».
Entre la deuxième moitié de la décennie de 80 et le début de la décennie de 90, plusieurs avancées pertinentes dans la structure des réseaux artificiels se sont produites. Cependant, la quantité de temps et d’informations nécessaires pour obtenir de bons résultats a tergiverser l’adoption, affectant l’intérêt sur l’intelligence artificielle.
Au début des années 2000, le pouvoir de l’informatique s’est élargi et le marché a connu un «boom» des techniques de calcul qui n’étaient pas possibles auparavant. C’est à ce moment-là que Deep Learning a émergé de la grande croissance computationnelle de ce temps comme un mécanisme essentiel pour l’élaboration de systèmes d’intelligence artificielle, remportant plusieurs compétitions de machine learning. L’intérêt pour l’apprentissage profond continue de croître jusqu’à nos jours et plusieurs solutions commerciales émergent à tout moment.
Au fil du temps, plusieurs recherches ont été créées afin de simuler le fonctionnement du cerveau, en particulier pendant le processus d’apprentissage pour créer des systèmes intelligents qui pourraient recréer des tâches telles que la classification et la reconnaissance des modèles, parmi D’autres activités. Les conclusions de ces études ont généré le modèle de Neuron artificiel, placé plus tard dans un réseau interconnecté appelé réseau neuronal.
En 1943, Warren McCulloch, neurophysiologue, et Walter Pitts, mathématicien, ont créé un réseau neuronal simple utilisant des circuits électriques et élaboré un modèle informatique pour les réseaux neuronaux basés sur des concepts mathématiques et des algorithmes appelés seuil Logic ou logique de seuil, qui a permis la recherche sur le réseau neuronal divisé en deux brins: se concentrant sur le processus biologique du cerveau et un autre axé sur l’application de ces réseaux neuronaux destinés à l’intelligence artificielle.[10]
Donald Hebb[11], en 1949, a écrit une œuvre où il a rapporté que les circuits neuronaux sont renforcés plus ils sont utilisés, comme l’essence de l’apprentissage. Avec l’avancement des ordinateurs dans la décennie 1950, l’idée d’un réseau neuronal a gagné en force et Nathan Roc[12]hester des laboratoires d’études d’IBM a essayé de constituer un, mais n’a pas réussi.
Le projet de recherche d’été de Dartmouth sur [13]l’intelligence artificielle, en 1956, a stimulé les réseaux neuronaux, ainsi que l’intelligence artificielle, encourageant la recherche dans ce domaine en relation avec le traitement neuronal. Dans les années qui suivirent, John von Neumann imitait les fonctions simples des neurones avec des tubes à vide ou des télégraphes, tandis que Frank Rosenblatt initia le projet Perceptron, analysant le fonctionnement de l’œil d’une mouche. Le résultat de cette recherche était un matériel, qui est le plus ancien réseau neuronal utilisé jusqu’à nos jours. Cependant, le Perceptron est très limité, ce qui a été prouvé par Marvin et Papert[14]
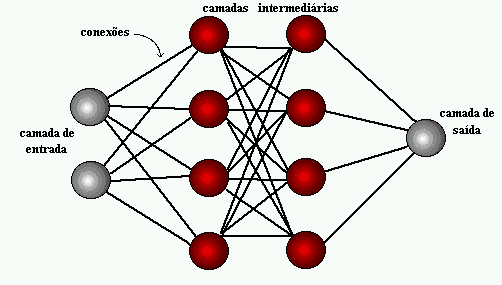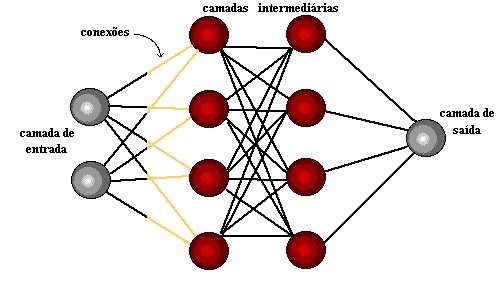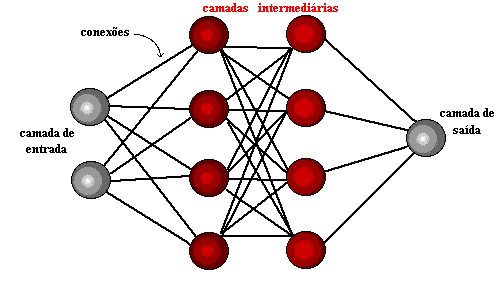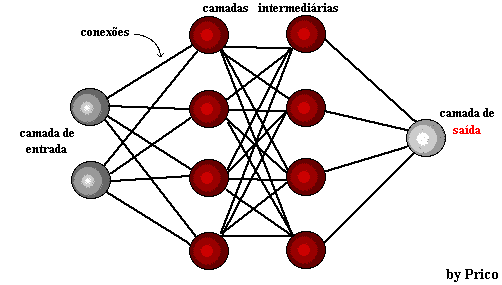
Figure 1: structure du réseau neuronal
Quelques années plus tard, en 1959, Bernard Widrow et Marcian Hoff développent deux modèles appelés «Adaline» et «Madaline». La nomenclature dérive de l’utilisation de plusieurs éléments: ADAptive LINear. Adaline a été créé pour identifier les modèles binaires afin de faire des prédictions sur le bit suivant, tandis que "Madaline" a été le premier réseau neuronal appliqué à un problème réel, à l’aide d’un filtre adaptatif. Le système est toujours en cours d’utilisation, mais seulement commercial.[15]
Les progrès accomplis précédemment ont conduit à la croyance que le potentiel des réseaux neuronaux était limité à l’électronique. Il a été interrogé sur l’impact que les «machines intelligentes» auraient sur l’homme et la société dans son ensemble.
Le débat sur la façon dont l’intelligence artificielle affecterait l’homme, a soulevé des critiques sur la recherche dans les réseaux neuronaux qui a provoqué une réduction du financement et, par conséquent, des études dans la région, qui est resté jusqu’à 1981.
L’année suivante, plusieurs événements ont réacporté l’intérêt dans ce domaine. John Hopfield de Caltech a présenté une approche de la création d’appareils utiles, démontrant ses affectation[16]s. En 1985, l’Institut américain de physique a commencé une réunion annuelle appelée réseaux neuronaux pour le calcul. En 1986, les médias ont commencé à rapporter les réseaux neuronaux de plusieurs couches, et trois chercheurs ont présenté des idées similaires, appelées réseaux de rétropropagation, parce qu’elles distribuent des échecs d’identification de modèles à travers le réseau.
Les réseaux hybrides n’avaient que deux couches, tandis que les réseaux de rétropropagation[17] en présentent beaucoup, de sorte que ce réseau conserve les informations plus lentement, parce qu’ils ont besoin de milliers d’itérations pour apprendre, mais aussi présenter plus de résultats juste. Déjà en 1987, il y a eu la première Conférence internationale sur les réseaux neuronaux de l’Institut de génie électrique et électronique (IEEE).
Dans l’année 1989, les scientifiques ont créé des algorithmes qui utilisaient des réseaux neuronaux profonds, mais le temps de «l’apprentissage» était très long, ce qui a empêché son application à la réalité. En 1992, Juyang Weng Diulga la méthode Cresceptron pour réaliser la reconnaissance d’objets 3D à partir de scènes tumultueuses.
Au milieu de 2000 ans, le terme Deep Learning ou deep learning commence à être diffusé après un article de Geoffrey Hinton et Ruslan Salakhutdin[18]ov, qui démontre comment un réseau neuronal multicouche pourrait être préalablement formé, une couche à la fois .
En 2009, l’atelier de traitement des systèmes de réseau neuronal sur l’apprentissage profond pour la reconnaissance vocale a lieu et il est vérifié qu’avec un groupe de données étendu, les réseaux neuronaux n’ont pas besoin d’une formation préalable et les taux d’échec tombent fait significati[19]f.
En 2012, les recherches ont fourni des algorithmes d’identification de modèles artificiels avec des performances humaines dans certaines tâches. Et l’algorithme de Google identifie les félins.
En 2015, Facebook utilise deep learning pour marquer et reconnaître automatiquement les utilisateurs dans les photos. Les algorithmes effectuent des tâches de reconnaissance faciale à l’aide de réseaux profonds. Au cours de l’année 2017, il y a eu une adoption à grande échelle de l’apprentissage profond dans diverses applications commerciales et appareils mobiles, ainsi que des progrès dans la recherch[20]e.
L’engagement de Deep Learning est de démontrer qu’un ensemble assez étendu de données, de processeurs rapides et d’un algorithme assez sophistiqué, permet aux ordinateurs d’effectuer des tâches telles que la reconnaissance d’images et de voix, entre autres Possibilités.
La recherche sur les réseaux neuronaux a gagné en importance avec des attributions prometteuses présentées par les modèles de réseaux neuronaux créés, en raison des innovations technologiques récentes de mise en œuvre qui permettent de développer des structures neurales audacieuses Parallèlement au matériel, obtenant des performances satisfaisantes de ces systèmes, avec des performances supérieures aux systèmes conventionnels, y compris. L’évolution des réseaux neuronaux est l’apprentissage profond.
DEEP LEARNING
Il s’agit d’abord de différencier l’intelligence artificielle, l’apprentissage automatique et l’apprentissage profond.
Figure 2: intelligence artificielle, apprentissage automatique et apprentissage profond
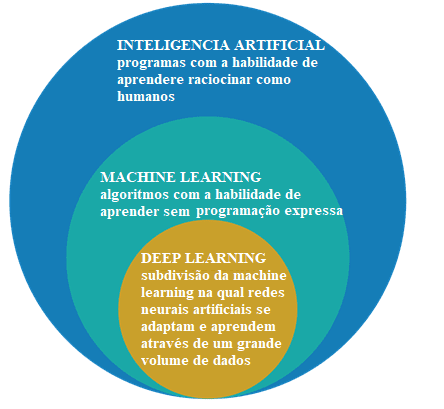
Le domaine d’étude de l’intelligence artificielle est la recherche et la conception de sources intelligentes, c’est-à-dire un système qui peut prendre des décisions basées sur une caractéristique considérée comme intelligente. Dans l’intelligence artificielle, il y a plusieurs méthodes qui modélisez cette caractéristique et parmi eux est la sphère de machine learning, où les décisions sont prises (renseignement) sur la base d’exemples et non pas une programmation déterminée.
Les algorithmes d’apprentissage automatique requièrent des informations pour supprimer des fonctionnalités et des apprentissages qui peuvent être utilisés pour prendre des décisions futures. Deep Learning est un sous-groupe de techniques d’apprentissage automatique, qui utilisent généralement des réseaux neuronaux profonds et ont besoin d’une grande quantité d’informations pour la formatio[21]n.
Selon Santana il y a [22]quelques différences entre les techniques de machine learning et les méthodes d’apprentissage profond, et les principales sont le besoin et l’impact du volume de données, la puissance de calcul et la flexibilité dans la modélisation des problèmes.
Machine Learning a besoin de données pour identifier les modèles, mais il y a deux problèmes concernant les données qui font référence à la dimensionnalité et à la stagnation des performances en introduisant plus de données au-delà de la limite de comportement. Il est vérifié qu’il y a une réduction des performances significatives lorsque cela se produit. En ce qui concerne la dimensionnalité, la même chose se produit, car il y a beaucoup d’informations à détecter, par les techniques classiques la dimension du problème.
Figure 3: Comparaison de l’apprentissage profond avec d’autres algorithmes concernant la quantité de données.
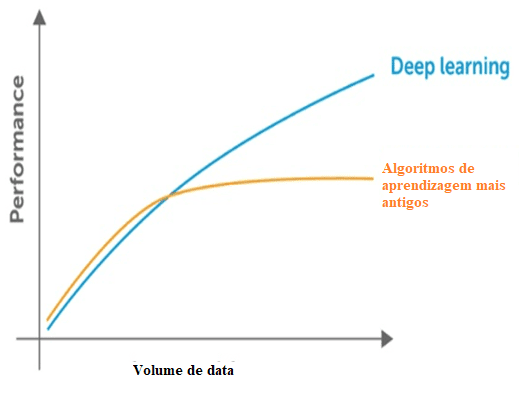
Les techniques classiques présentent également un point de saturation par rapport à la quantité de données, qui est, ont une limite maximale pour extraire l’information, qui ne se produit pas avec l’apprentissage profond, créé pour travailler avec un grand volume de données.
En ce qui concerne la puissance de calcul pour l’apprentissage profond, ses structures sont complexes et exigent un grand volume de données pour sa formation, ce qui démontre sa dépendance à une grande puissance de calcul pour mettre en œuvre ces pratiques. Alors que d’autres pratiques classiques ont besoin de beaucoup de puissance de calcul en tant que CPU, les techniques d’apprentissage profond sont supérieures.
Les recherches relatives à l’informatique parallèle et à l’utilisation de GPU avec CUDA-Compute Unified Device Architecture ou l’architecture de périphérique informatique unifiée ont initié l’apprentissage profond, car il était impossible avec l’utilisation d’un CPU simple.
En comparaison avec la formation d’un réseau neuronal profond ou l’apprentissage profond avec l’utilisation d’un CPU, il s’avère qu’il serait impossible d’obtenir des résultats satisfaisants même avec une formation prolongée.
L’apprentissage profond, également connu sous le nom d’apprentissage profond, fait partie de l’apprentissage automatique, et il applique des algorithmes pour traiter les données et reproduire le traitement effectué par le cerveau humain.
L’apprentissage profond utilise des couches de neurones mathématiques pour traiter les données, identifier la parole et reconnaître les objets. Les données sont transmises par chaque couche, la sortie de la couche précédente accordant l’entrée à la couche suivante. La première couche d’un réseau est appelée couche en entrée et la dernière est la couche en sortie. Les couches intermédiaires sont appelées couches cachées, et chaque couche du réseau est formée par un algorithme simple et uniforme qui englobe une sorte de fonction d’activation.
Figure 4: réseau neuronal simple et réseau neuronal profond ou Deep Learning
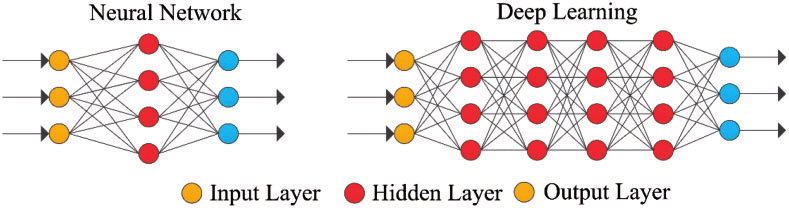
Les couches ultrapériphériques en jaune sont les couches d’entrée ou de sortie, et les couches intermédiaires ou masquées sont en rouge. Deep Learning est responsable des progrès récents dans le calcul, la reconnaissance vocale, le traitement du langage et l’identification auditive, sur la base de la définition de réseaux neuronaux artificiels ou de systèmes de calcul qui reproduisent les La façon dont le cerveau humain agit.
Un autre aspect de Deep Learning est l’extraction des ressources, qui utilise un algorithme pour créer automatiquement des paramètres pertinents de l’information pour la formation, l’apprentissage et la compréhension, une tâche de l’ingénieur de l’intelligence artificielle.
L’apprentissage profond est une évolution des réseaux neuronaux. L’intérêt pour l’apprentissage profond s’est développé graduellement dans les médias et plusieurs recherches dans le domaine ont été diffusées et son application a atteint les voitures, dans le diagnostic du cancer et de l’autisme, entre autres applications[23]
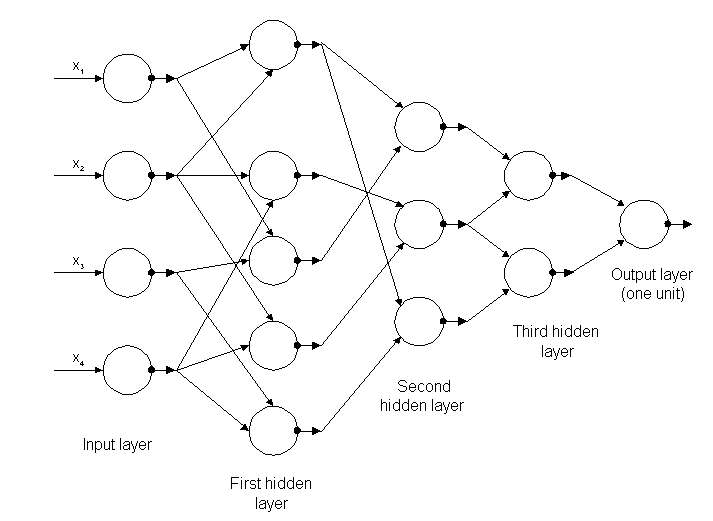
Les premiers algorithmes d’apprentissage profond avec plusieurs couches d’affectations non linéaires présentent leurs origines dans Alexey Grigoryevich Ivakhnenko, qui a développé la méthode de groupe de manipulation de données et Valentin Grigor’evich Lapa, auteur de l’œuvre Cybernétique et techniques de prévision dans l’année 1965.[24]
Les deux ont utilisé des modèles minces et profonds avec des fonctions d’activation polynomiale, qui ont été étudiées à l’aide de méthodes statistiques. Grâce à ces méthodes, ils ont sélectionné dans chaque couche les meilleures ressources et transmis à la couche suivante, sans utiliser Backpropagation pour "former" le réseau complet, mais utilisé des carrés minimaux sur chaque couche, où les précédents ont été installés à partir Indépendamment dans les couches ultérieures, manuellement.
Figure 5: structure du premier réseau profond connu sous le nom de Alexey Grigorevich Ivakhnenko
À la fin de la décennie de 1970, l’hiver de l’intelligence artificielle s’est produit, une réduction drastique du financement de la recherche sur le sujet. L’impact a limité les progrès dans les réseaux neuronaux profonds et l’intelligence artificielle.
Les premiers réseaux neuronaux convolutifs ont été utilisés par Kunihiko Fukushima, avec plusieurs couches de groupement et de convolutions, en 1979. Il a créé un réseau neuronal artificiel, appelé Neocognitron, avec une disposition hiérarchique et multicouche, qui a permis à l’ordinateur d’identifier les modèles visuels. Les réseaux étaient similaires aux versions modernes, avec la «formation» axée sur la stratégie de renforcement de l’activation périodique dans d’innombrables couches. De plus, la conception de Fukushima a permis d’adapter manuellement les ressources les plus pertinentes en augmentant l’importance de certaines connexions[25].
De nombreuses lignes directrices de Neocognitron sont toujours en cours d’utilisation, car les connexions descendentes et les nouvelles pratiques d’apprentissage ont favorisé la réalisation de divers réseaux neuronaux. Lorsque plusieurs modèles sont présentés en même temps, le modèle de soins sélectifs peut les séparer et identifier les modèles individuels, en accordant une attention à chacun. Un Neocognitron plus à jour peut identifier les modèles avec le manque de données et compléter l’image en insérant les informations manquantes, qui est appelée inférence.
La rétropropagation utilisée pour la formation en cas d’échec d’apprentissage profond a progressé à partir de 1970, lorsque Seppo Linnainmaa a écrit une thèse, en insérant un code FORTRAN pour la rétropropagation, sans réussir jusqu’à 1985. Rumelhart, Williams et Hinton ont ensuite démontré la rétropropagation dans un réseau neuronal avec des représentations de distribution.
Cette découverte a permis au débat sur l’IA d’atteindre la psychologie cognitive qui a initié des questions sur la compréhension humaine et sa relation avec la logique symbolique, ainsi que les connexions. En 1989, Yann LeCun a réalisé une démonstration pratique de Backpropagation, avec la combinaison de réseaux neuronaux convolutifs pour identifier les chiffres écrits.
Dans cette période, il y avait encore une pénurie de financement pour la recherche dans ce domaine, connu comme le deuxième hiver de l’IA, qui a eu lieu entre 1985 et 1990, affectant également la recherche dans les réseaux neuronaux et Deep Learning. Les attentes présentées par certains chercheurs n’ont pas atteint le niveau attendu, qui a profondément irrité les investisseurs.
En 1995, Dana Cortes et Vladimir Vapnik ont créé le support vector machine ou mac[26]hine vectorielle de soutien qui était un système de cartographie et d’identification des informations similaires. Le long court terme Memory-LSTM pour les réseaux neuronaux périodiques a été élaboré en 1997 par Sepp Hochreiter et Juergen Schmidhube[27]r.
L’étape suivante de l’évolution de Deep Learning s’est produite en 1999, lorsque le traitement des données et les unités de traitement graphique (GPU) sont devenus plus rapides. L’utilisation de GPU et son traitement rapide représentaient une augmentation de la vitesse des ordinateurs. Les réseaux neuronaux concurrençaient les machines vectorielles de soutien. Le réseau neuronal était plus lent qu’une machine de vecteur de support, mais ils ont obtenu de meilleurs résultats et ont continué à évoluer à mesure que plus d’informations de formation ont été ajoutées.
En l’an 2000, un problème appelé gradient de fuite a été identifié. Les affectations apprises dans les couches inférieures n’ont pas été transmises aux couches supérieures cependant, il n’a eu lieu dans ceux avec des méthodes d’apprentissage basées sur gradient. La source du problème était dans certaines fonctions d’activation qui ont réduit son entrée affectant la plage de sortie, générant de grandes zones d’entrée mappées dans une très petite plage, provoquant un gradient descendant. Les solutions mises en œuvre pour résoudre le problème étaient la couche de pré-entraînement par couche et le développement d’une mémoire à long et à court term[28]e.
En 2009, Fei-Fei Li a publié ImageNet ave[29]c une base de données gratuite de plus de 14 millions images, axée sur la «formation» des réseaux neuronaux, soulignant comment les Mégadonnées affecteraient le fonctionnement du machine learning.
La vitesse des GPU, jusqu’à l’année 2011, a continué à augmenter permettant la composition des réseaux neuronaux convolutifs sans avoir besoin de couche de pré-entraînement par couche. Ainsi, il est devenu notoire que l’apprentissage profond était avantageux en termes d’efficacité et de rapidité.
À l’heure actuelle, le traitement du Big Data et la progression de l’intelligence artificielle dépendent de Deep Learning, qui peut élaborer des systèmes intelligents et promouvoir la création d’une intelligence artificielle entièrement autonome, ce qui créera un impact sur Toute la société.
FLEXIVILITÉ DES RÉSEAUX NEURONAUX ET DE LEURS APPLICATIONS
Malgré l’existence de plusieurs techniques classiques, la structure d’apprentissage profond et son unité de base, le neurone est générique et très flexible. En faisant une comparaison avec le neurone humain qui fournit des synapses, nous pouvons identifier quelques corrélations entre eux.
Figure 6: corrélation entre un neurone humain et un réseau neuronal artificiel
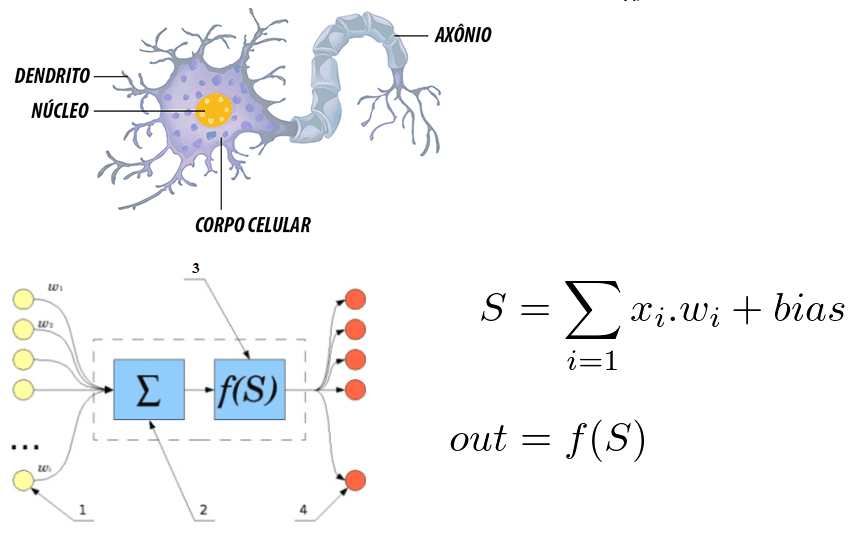
Il est noté que le neurone est formé par les dendrites qui sont les points d’entrée, un noyau qui représente dans les réseaux neuronaux artificiels le noyau de traitement et le point de sortie qui est représenté par l’AXON. Dans les deux systèmes, les informations entrent, sont traitées et changent.
Considérant qu’il s’agit d’une équation mathématique, le neurone reflète la somme des entrées multipliées par les pondérations, et cette valeur passe par une fonction d’activation. Cette somme a été réalisée par McCulloch et Pitts en 1943[30]
En ce qui concerne l’intérêt notoire sur l’apprentissage profond de nos jours, Sant[31]ana considère que c’est dû à deux facteurs qui sont la quantité d’informations disponibles et la limitation des techniques plus anciennes en plus de la puissance de calcul actuelle pour former des réseaux complexe. La souplesse d’interconnexion de plusieurs neurones dans un réseau plus complexe est le différentiel des structures d’apprentissage profond. Un réseau neuronal convolutif est largement utilisé pour la reconnaissance faciale, la détection d’images et l’extraction d’affectation.
Un réseau neuronal conventionnel se compose de plusieurs couches, appelées layers. Selon le problème à résoudre la quantité de couches peut varier, être capable d’avoir jusqu’à des centaines de couches, étant des facteurs qui influencent en quantité la complexité du problème, le temps et la puissance de calcul
Il existe plusieurs structures différentes avec des objectifs innombrables et leur fonctionnement dépend également de la structure et tous sont basés sur les réseaux neuronaux.
Figure 7: exemples de réseaux neuronaux
Cette souplesse architecturale permet un apprentissage approfondi pour résoudre divers problèmes. L’apprentissage profond est une technique d’objectif général, mais les étendues les plus avancées étaient: vision par ordinateur, reconnaissance vocale, traitement du langage naturel, systèmes de recommandation.
La vision computationnelle englobe la reconnaissance d’objets, la segmentation sémantique, en particulier les voitures autonomes. On peut affirmer que la vision computationnelle fait partie de l’intelligence artificielle et est définie comme un ensemble de connaissances qui recherche la modélisation artificielle de la vision humaine avec l’objectif d’imiter ses fonctions, à travers le développement de logiciels et de matériel de point[32]e.
Parmi les applications de la vision computationnelle, on trouve l’utilisation militaire, le marché marketing, la sécurité, les services publics et le processus de production. Les véhicules autonomes représentent l’avenir du trafic plus sûr, mais il est encore en phase de test, car il englobe plusieurs technologies appliquées à une fonction. La vision computationnelle dans ces véhicules, puisqu’elle permet la reconnaissance du chemin et des obstacles, améliorant les itinéraires.
Dans le contexte de la sécurité, les systèmes de reconnaissance faciale ont été de plus en plus mis en évidence, compte tenu du niveau de sécurité dans les lieux publics et privés, également mis en œuvre dans les appareils mobiles. De même, ils peuvent servir de clé pour accéder aux transactions financières, tandis que sur les réseaux sociaux, il détecte la présence de l’utilisateur ou de ses amis dans les photos.
En ce qui concerne le marché de la commercialisation, une recherche développée par image intelligence a souligné que 3 milliards images sont partagées quotidiennement par les réseaux sociaux et 80% contiennent des indications qui renvoient à des sociétés spécifiques, mais sans références textuelles. Les sociétés de marketing spécialisées offrent un service de surveillance et de gestion de présence en temps réel. Avec la technologie de vision d’ordinateur, la précision dans l’identification d’image atteint 99%.
Dans les services publics, son utilisation couvre la sécurité du site en surveillant les caméras, le trafic des véhicules à travers des images stéréoscopiques qui rendent le système de vision efficace.
Dans le processus de production, les entreprises de différentes branches emploient la vision computationnelle comme instrument de contrôle de qualité. Dans n’importe quelle branche, le logiciel le plus avancé associé à la capacité de traitement toujours croissante du matériel augmente l’utilisation de la vision computationnelle.
Les systèmes de surveillance permettent la reconnaissance des normes préétablies et soulignent les défaillances qui ne seraient pas identifiables lorsque l’on regarde un employé dans la ligne de production. Dans le même contexte, appliqué au contrôle des stocks est le projet d’automatisation de remplacement. Un inventaire et un contrôle des ventes en temps réel permettent à la technologie de contrôler les opérations d’une entreprise donnée, augmentant ainsi ses profits. Il existe d’autres applications dans le domaine de la médecine, de l’éducation et du commerce électronique.
Conclusions
La présente étude visait à élucider ce qu’est l’apprentissage profond et à souligner ses applications dans le monde actuel. Les techniques d’apprentissage profond continuent de progresser en particulier avec l’utilisation de plusieurs couches. Cependant, il existe encore des limitations dans l’utilisation des réseaux neuronaux profonds, étant donné qu’ils ne sont qu’un moyen d’apprendre plusieurs modifications à implémenter dans le vecteur d’entrée. Les modifications apportées par une série de paramètres qui sont mis à jour dans la période de formation.
Il est indéniable que l’intelligence artificielle est une réalité plus proche, mais il manque un long chemin à parcourir. L’acceptation de l’apprentissage profond dans divers domaines de la connaissance permet à la société, dans son ensemble, de bénéficier des merveilles de la technologie moderne.
En ce qui concerne l’intelligence artificielle, il est vérifié que cette technologie capable d’apprendre, bien que très importante a une nature linéaire et non-molable comme des êtres humains, qui représente un grand différentiel et essentiel pour certains domaines de la connaissance, le Cela ne peut pas encore être mis en œuvre dans l’apprentissage profond.
En aucune façon, l’utilisation des méthodes d’apprentissage profond permettra aux machines d’aider la société dans diverses activités comme démontré, en élargissant la capacité cognitive de l’homme et un développement encore plus important dans ces domaines de la connaissance.
RÉFÉRENCES BIBLIOGRAPHIQUES
ALIGER. Saiba o que é visão computacional e como ela pode ser usada. 2018. Disponível em: https://www.aliger.com.br/blog/saiba-o-que-e-visao-computacional/
BITTENCOURT, Guilherme. Breve história da Inteligência Artificial. 2001
CARVALHO, André Ponce de L. Redes Neurais Artificiais. Disponível em: http://conteudo.icmc.usp.br/pessoas/andre/research/neural/
CHUNG, J; GULCEHE, C; CHO, K; BENGIO, Y. Gated feedback recurrent neural networks. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, volume 37 of ICML, pages 2067–2075. 2015
CULTURA ANALITICA. Entenda o que é deep learning e como funciona. Disponível em: https://culturaanalitica.com.br/deep-learning-oquee-como-funciona/cultura-analitica-redes-neurais-simples-profundas/
DENG, Jia et al. Imagenet: Um banco de dados de imagens hierárquicas em grande escala. In: 2009 Conferência IEEE sobre visão computacional e reconhecimento de padrões . Ieee,. p. 248-255. 2009
DETTMERS, Tim. Aprendizagem profunda em poucas palavras: Historia e Treinamento. Disponível em: https://devblogs.nvidia.com/deep-learning-nutshell-history-training/
FUKUSHIMA, Kunihiko. Neocognitron: Um modelo de rede neural auto-organizada para um mecanismo de reconhecimento de padrões não afetado pela mudança de posição. Cibernética biológica , v. 36, n. 4, p. 193-202, 1980.
GARTNER. Gartner diz que a AI Technologies estará em quase todos os novos produtos de software até 2020. Disponível em: https://www.gartner.com/en/newsroom/press-releases/2017-07-18-gartner-says-ai-technologies-will-be-in-almost-every-new-software-product-by-2020
GOODFELLOW, I; BENGIOo, Y; COURVILLE, A. Deep Learning. MIT Press. Disponível em: http://www.deeplearningbook.org
GRAVES, A. Sequence transduction with recurrent neural networks. arXiv preprint arXiv:1211.3711, 2012.
HOCHREITER, Sepp. O problema do gradiente de fuga durante a aprendizagem de redes neurais recorrentes e soluções de problemas. Revista Internacional de Incerteza, Fuzziness and Knowledge-Based Systems , v. 6, n. 02, p. 107-116, 1998.
HEBB, Donald O. The organization of behavior; a neuropsycholocigal theory. A Wiley Book in Clinical Psychology., p. 62-78, 1949.
HINTON, Geoffrey E; SALAKHUTDINOV, Ruslan R. Reduzindo a dimensionalidade dos dados com redes neurais. ciência , v. 313, n. 5786, p. 504-507, 2006.
HOCHREITER, Sepp; SCHMIDHUBER, Jürgen. Longa memória de curto prazo. Computação Neural, v. 9, n. 8, p. 1735-1780, 1997.
INTRODUCTION to artificial neural networks, Proceedings Electronic Technology Directions to the Year 2000, Adelaide, SA, Australia, 1995, pp. 36-62. Disponível em: https://ieeexplore.ieee.org/document/403491
KOROLEV, Dmitrii. Set of different neural nets. Neuron network. Deep learning. Cognitive technology concept. Vector illustration Disponível em: https://stock.adobe.com/br/images/set-of-different-neural-nets-neuron-network-deep-learning-cognitive-technology-concept-vector-illustration/145011568
LIU, C.; CAO, Y; LUO Y; CHEN, G; VOKKARANE, V, MA, Y; CHEN, S; HOU, P. A new Deep Learning-based food recognition system for dietary assessment on an edge computing service infrastructure. IEEE Transactions on Services Computing, PP(99):1–13. 2017
LORENA, Ana Carolina; DE CARVALHO, André CPLF. Uma introdução às support vector machines. Revista de Informática Teórica e Aplicada, v. 14, n. 2, p. 43-67, 2007.
MARVIN, Minsky; SEYMOUR, Papert. Perceptrons. 1969. Disponível em: http://134.208.26.59/math/AI/AI.pdf
MCCULLOCH, Warren S; PITTS, Walter. Um cálculo lógico das idéias imanentes na atividade nervosa. O boletim de biofísica matemática, v. 5, n. 4, p. 115-133, 1943.
NIELSEN, Michael. How the backpropagation algorithm works. 2018. Disponível em: http://neuralnetworksanddeeplearning.com/chap2.html
NIPS. 2009. Disponível em: http://media.nips.cc/Conferences/2009/NIPS-2009-Workshop-Book.pdf
PANG, Y; SUN, M; JIANG, X; LI, X.. Convolution in convolution for network in network. IEEE Transactions on Neural Networks and Learning Systems, PP(99):1–11. 2017
SANTANA, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponível em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
UDACITY. Conheça 8 aplicações de Deep Learning no mercado. Disponível em: https://br.udacity.com/blog/post/aplicacoes-deep-learning-mercado
YANG, S; LUO, P; LOY, C.C; TANG, X. From facial parts responses to face detection: A Deep Learning approach. In Proceedings of 2015 IEEE International Conference on Computer Vision (ICCV), pages 3676–3684. 2015
- Liu, C., Cao, Y., Luo, Y., Chen, G., Vokkarane, V., Ma, Y., Chen, S., and Hou, P. (2017). A new Deep Learning-based food recognition system for dietary assessment on an edge computing service infrastructure. IEEE Transactions on Services Computing, PP(99):1–13.
- Yang, S., Luo; P., Loy, C.-C; Tang, X. From facial parts responses to face detection: A Deep Learning approach. In Proceedings of 2015 IEEE International Conference on Computer Vision (ICCV), p. 3676
- Chung, J; Gulcehre, C; Cho, K; Bengio, Y. Gated feedback recurrent neural networks. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, volume 37 of ICML, p. 2069
- PANG, Y; Sun, M., Jiang, X., and Li, X. (2017). Convolution in convolution for network in network. IEEE Transactions on Neural Networks and Learning Systems, PP(99):5. 2017 ↑
- Goodfellow, I., Bengio, Y., and Courville, A. Deep Learning. MIT Press. http://www.deeplearningbook.org.
- GRAVES, A. Sequence transduction with recurrent neural networks. arXiv preprint arXiv:1211.3711, 2012.
- GARTNER. Gartner diz que a AI Technologies estará em quase todos os novos produtos de software até 2020. Disponível em: https://www.gartner.com/en/newsroom/press-releases/2017-07-18-gartner-says-ai-technologies-will-be-in-almost-every-new-software-product-by-2020
- MCCULLOCH, Warren S; PITTS, Walter. Um cálculo lógico das idéias imanentes na atividade nervosa. O boletim de biofísica matemática , v. 5, n. 4, p. 115-133, 1943.
- HEBB, Donald O. The organization of behavior; a neuropsycholocigal theory. A Wiley Book in Clinical Psychology., p. 62-78, 1949.
- BITTENCOURT, Guilherme. Breve história da Inteligência Artificial. 2001.p. 24
- Idbiem p. 25
- MARVIN, Minsky; SEYMOUR, Papert. Perceptrons. 1969. Disponível em: http://134.208.26.59/math/AI/AI.pdf
- Introduction to artificial neural networks," Proceedings Electronic Technology Directions to the Year 2000, Adelaide, SA, Australia, 1995, pp. 36-62. Disponível em: https://ieeexplore.ieee.org/document/403491
- BITTENCOURT, Guilherme op cit. p. 32
- NIELSEN, Michael. How the backpropagation algorithm works. 2018. Disponível em: http://neuralnetworksanddeeplearning.com/chap2.html
- HINTON, Geoffrey E; SALAKHUTDINOV, Ruslan R. Reduzindo a dimensionalidade dos dados com redes neurais. ciência , v. 313, n. 5786, p. 504-507, 2006.
- NIPS. 2009. Disponível em: http://media.nips.cc/Conferences/2009/NIPS-2009-Workshop-Book.pdf
- Santana, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponivel em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
- SANTANA, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponível em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
- idem
- UDACITY. Conheça 8 aplicações de Deep Learning no mercado. Disponível em: https://br.udacity.com/blog/post/aplicacoes-deep-learning-mercado
- Dettmers, Tim. Aprendizagem profunda em poucas palavras: Historia e Treinamento. Disponível em: https://devblogs.nvidia.com/deep-learning-nutshell-history-training/
- FUKUSHIMA, Kunihiko. Neocognitron: Um modelo de rede neural auto-organizada para um mecanismo de reconhecimento de padrões não afetado pela mudança de posição. Cibernética biológica , v. 36, n. 4, p. 193-202, 1980.
- LORENA, Ana Carolina; DE CARVALHO, André CPLF. Uma introdução às support vector machines. Revista de Informática Teórica e Aplicada, v. 14, n. 2, p. 43-67, 2007.
- HOCHREITER, Sepp; SCHMIDHUBER, Jürgen. Longa memória de curto prazo. Computação Neural, v. 9, n. 8, p. 1735-1780, 1997.
- HOCHREITER, Sepp. O problema do gradiente de fuga durante a aprendizagem de redes neurais recorrentes e soluções de problemas. Revista Internacional de Incerteza, Fuzziness and Knowledge-Based Systems , v. 6, n. 02, p. 107-116, 1998.
- DENG, Jia et al. Imagenet: Um banco de dados de imagens hierárquicas em grande escala. In: 2009 Conferência IEEE sobre visão computacional e reconhecimento de padrões . Ieee, 2009. p. 248-255.
- MCCULLOCH, Warren S.; PITTS, Walter. Um cálculo lógico das idéias imanentes na atividade nervosa. O boletim de biofísica matemática , v. 5, n. 4, p. 115-133, 1943.
- SANTANA, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponivel em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
- ALIGER. Saiba o que é visão computacional e como ela pode ser usada. 2018. Disponível em: https://www.aliger.com.br/blog/saiba-o-que-e-visao-computacional/
[1] Bachelor of Business Administration.
Soumis: May, 2019
Approuvé le: mai, 2019