ARTÍCULO DE REVISIÓN
VICTORINO, Samuel Carlos [1]
VICTORINO, Samuel Carlos. Otro enfoque en la elaboración de tablas de frecuencias utilizando la teoría de distribución normal de GAUSS. Revista Científica Multidisciplinar Núcleo do Conhecimento. Año 06, Ed. 03, Vol. 07, pp. 139-154. Marzo de 2021. ISSN:2448-0959, Enlace de acceso: https://www.nucleodoconhecimento.com.br/agronomia-es/tablas-de-frecuencias
RESUMEN
La correcta organización de los datos es de extrema importancia para el análisis en el proceso de inferencia estadística, con el objetivo de elaborar conclusiones válidas y recomendaciones genéricas sobre un determinado tema objeto de estudio. La literatura científica especializada describe varios procedimientos para la organización de datos en tablas de distribución de frecuencias. Sin embargo, no es frecuente que se realicen inexactitudes en el uso de herramientas de organización de datos. Estas inexactitudes han dado lugar a análisis distorsionados y conclusiones incongruentes. Este documento presenta un análisis crítico de los métodos y procedimientos de la organización de datos descritos en la literatura, específicamente la distribución de datos en tablas de distribución de frecuencias y propone un enfoque diferente en la elaboración de tablas de distribución de frecuencias de clase. Para todas las variables con categorías predefinidas, estos y sus respectivos valores de referencia sirven como cuerpo de la tabla. Para las variables que no tienen categorías predefinidos, se propone y justifica el uso de la teoría de distribución normal de Gauss como criterio de categorización. Las categorías generadas sirven como cuerpo de tabla. Se concluye que las tablas de distribución de frecuencias se pueden distinguir en dos tipos, es decir, tablas de distribución de frecuencias de clases o categorías predefinidas y tablas de distribución de frecuencias de clases o categorías por definir, lo que sugiere su adopción como concepto.
Palabras clave: Distribución normal, Tabla de distribución de frecuencia simple, Tabla de distribución de frecuencia de las clases que se definirán.
1. INTRODUCCIÓN
Las estadísticas, como ciencia, se resumen en un conjunto de métodos y procedimientos que permiten la recopilación, organización y presentación de datos para su análisis, con el fin de obtener conclusiones válidas y la elaboración de recomendaciones genéricas sobre una población determinada estudiada.
Las estadísticas encuentran aplicación en las más diversas áreas del conocimiento como la economía, la psicología, la sociología, la agricultura y la salud, ayudando en el proceso de toma de decisiones basado en el análisis de datos. Para que las estadísticas cumplan con este papel, es imperativo que los métodos y procedimientos se apliquen correctamente. La recopilación de datos implica la correcta aplicación de métodos de muestreo que culminan en la selección de muestras representativas y garantizan la validez de los datos y, al mismo tiempo, la validez de los estudios; la organización y presentación de datos tiene como objetivo la simplificación y compresión de datos en tablas de distribución de frecuencias, ya sean tablas de frecuencia única o tablas de frecuencia de clase. Los datos resumidos en tablas se visualizan generalmente y, en su caso, en gráficos, diagramas y otras herramientas estadísticas. Su correcta organización es de extrema importancia para el análisis de datos en el proceso de inferencia estadística.
La literatura científica especializada describe una amplia gama de procedimientos para la organización de datos en tablas de distribución de frecuencias. Se ha constatado que a menudo se cometen inexactitudes en el uso de herramientas de organización de datos, lo que resulta en una interpretación distorsionada y conclusiones incongruentes. Este artículo tiene como objetivo presentar un análisis crítico de los métodos y procedimientos de la organización de datos descritos en la literatura, específicamente la distribución de datos en tablas de frecuencias y propone un enfoque diferente en la elaboración de tablas de distribución de frecuencias.
2 . MARCO TEÓRICO SOBRE TABLAS DE DISTRIBUCIÓN DE FRECUENCIAS
La estadística se divide en dos grupos principales: estadísticas descriptivas y estadísticas inferenciales.
Estadísticas descriptivas es la parte que se ocupa de la descripción, clasificación, organización y presentación de los datos de una variable. Permite resumir datos y ayuda a describir los atributos de un grupo de datos determinado o una población mediante el cálculo de medidas descriptivas como la media y la desviación estándar. Las técnicas tabulares y gráficas descriptivas utilizadas con el soporte de las capacidades gráficas de los ordenadores modernos y el diverso software disponible para hacer este tipo de resumen más factible y más comprensible.
Las estadísticas inferenciales, por otro lado, son las encargadas de analizar los datos con el fin de obtener conclusiones válidas y la elaboración de recomendaciones genéricas sobre la población que se está estudiando.
2.1 TÉCNICAS TABULARES Y GRÁFICAS DESCRIPTIVAS
Los datos sin procesar de una variable obtenida en un proceso de muestreo no permiten la visualización de ninguna característica de la muestra y mucho menos de la población en estudio. Por lo tanto, las tablas y gráficos son recursos estadísticos esenciales en el procesamiento de datos.
Las tablas permiten resumir y compactar una gran cantidad de información que proporciona un análisis claro al investigador. Los gráficos son el complemento de la tabla que tienen la función de transmitir una idea visual del comportamiento de los datos. Hay una amplia variedad de gráficos, entre ellos, gráficos de líneas, gráficos de barras, gráficos de área y gráficos circulares como los más comunes.En cuanto a las tablas de distribución de frecuencias, los siguientes tipos son fundamentalmente diferentes:
1 – Tabla única de distribución de frecuencias
2 – Tabla de distribución de frecuencia de clase
Una sola tabla de distribución de frecuencias contiene dos columnas principales. En la primera columna, cada valor recopilado se inserta secuencialmente, una vez y en orden ascendente. En la segunda columna de la línea correspondiente a cada valor observado se inserta el número de veces que estos valores se repiten en el conjunto de datos, que corresponde a la frecuencia absoluta respectiva.
La tabla de distribución de frecuencia de clase también contiene dos columnas, la primera para los intervalos de clase de la variable y la segunda para el número de individuos que pertenecen a cada clase, es decir, la frecuencia absoluta de la clase.
Las tablas de distribución de frecuencia única tienen la principal desventaja de ser demasiado largas, debido al hecho de que todos los valores muestreados tienen que ser enumerados y, sobre todo, no permiten la lectura de características de datos. Este tipo de tablas son totalmente inapropiadas cuando el propósito es resumir grandes cantidades de datos. Para estos casos, las tablas de distribución de frecuencia de clase son más adecuadas, ya que compactan grandes cantidades de datos en unas pocas clases y vinculan los atributos cuantitativos de la variable al significado actual de las características de la variable.
El aspecto fundamental en la elaboración de tablas de distribución de frecuencias de clase es la determinación del número de clases, en las que se enmarcarán los datos. Para ello, se describen varios criterios para determinar el número de clases en la literatura, la mayoría de las cuales están estrictamente basadas en matemáticas.
Milton y Tsokos (1991) indican el uso de las siguientes fórmulas para determinar el número de clases:
1 – Número de clases = 5 x lg n donde n es el tamaño de la muestra
2 – Número de clases =
![]()
Beiguelman (2002) indica que el número de clases está entre 8 y 20, dependiendo de los datos. Para Dawson y Trapp (2003) 6 y 14 clases son adecuadas para proporcionar suficiente información sin detalles excesivos. Triola y Triola (2006) recomiendan que el número de clases debe estar entre 5 y 20, mientras que Kuzma y Bohnenblust (2001) consideran que el número de clases debe ser de 5 a 15. Reis (2005) establece que el número de clases debe estar entre 4 y 14 y también sugiere el uso de una de las siguientes soluciones:
![]()
1 – Número de clases iguales 5 para muestras con tamaño inferior a 25 y número de clases = para muestras con un tamaño igual o superior a 25.
2 – Utilice la fórmula Sturges: número de clases = 1 + 3.22 n registro
Lo anterior muestra la variedad de criterios descritos en la literatura para la construcción de tablas de distribución de frecuencias. Sin embargo, estos criterios tienen una desventaja común que los hace inadecuados como base para determinar el número de clases de datos para ciertas variables, como variables en el campo de la biología y las ciencias de la salud, economía, industria, entre otras, que tienen categorías predefinidos, es decir, categorías estandarizadas. Algunas de estas variables se describen a continuación y se indican los valores de referencia respectivos de las categorías predefinidos.En el campo de la biología:
Ejemplo1: Valores de referencia del colesterol total en humanos Tabla 1: Categorías y valores de referencia del colesterol total en los seres humanos.
| Colesterol total | categoría |
| < 200 mg/dl | Deseable o normal |
| 200 – 239 mg/dl | frontera |
| ≥ 240 mg/dl | Alto |
Fuente: Third Report of the National Cholesterol Education Program (NCEP) Expert Panel on detection, evaluation, and treatment of high blood cholesterol in adults (Adult Treatment Panel III). Final report. Circulation, 2002, 106:3143–3421
Ejemplo 2: Valores de referencia para el índice de masa corporal (IMC).
El IMC ayuda a definir el grado de obesidad de una persona según la Organización Mundial de la Salud. Al calcular e interpretar el IMC es posible saber si una persona está por encima o por debajo de los parámetros de peso recomendados para su estructura física. Para calcular el IMC, el peso medido en kg se divide por la altura al cuadrado (IMC = kg / m2).
Tabla 2: Categorías y valores de referencia del Índice de Masa corporal
| categoría | IMC (kg/m2) |
| Peso insuficiente | < 18,5 |
| Normal (peso saludable) | 18,5 – 24,9 |
| Pre-obeso | 25,0 – 29,9 |
| Grado de obesidad I | 30,0 – 34,9 |
| Grado de obesidad II | 35,0 – 39,9 |
| Grado de obesidad III | ≥ 40,0 |
Fuente: World Health Organization. Obesity (1998): Preventing and managing the global epidemic: report of a WHO Consultation on Obesity, Geneva, 3–5 June 1997. Geneva (CH): World Health Organization; 1998. http://whqlibdoc.who.int/hq/1998/WHO_NUT_NCD_98.1_(p1-158).pdf.
Ejemplo 3 – Clasificación de la hipertensión arterial.Tabla 3: Clasificación de la hipertensión arterial
| Clasificación de la presión arterial | Presión arterial sistólica (mmHg) | Presión arterial diastólica (mmHg) |
| normal | < 120 | < 80 |
| Preintens hipertensión | 120 – 139 | 80 – 89 |
| Hipertensión en estadio 1 (grado I) | 140 – 159 | 90 – 99 |
| Hipertensión en estadio 2 (grado II) | ³ 160 | ³ 100 |
Fuente: The seventh report of the Joint National Committee on prevention, detection, evaluation, and treatment of high blood pressure. JAMA 2003; 289: 2560-72. Citado por PEDROSA y DRAGER (2010).
Ejemplo 4: El ácido úrico es el resultado del metabolismo de las purinas, los principales elementos estructurales del ADN y el ARN, gran parte de él de los alimentos. El consumo excesivo de carne o alcohol puede elevar los niveles de ácido úrico en la sangre.
Los valores de referencia son en general de 40 a 60 mg/L para los hombres, de 30 a 50 mg/L para las mujeres y de 25 a 40 mg/L para niños (CAQUET, 2011).
En el campo de la economía:
Ejemplo 5: El Índice de Desarrollo Humano (IDH) es un dato estadístico creado por el Programa de las Naciones Unidas para el Desarrollo (PNUD) para contrarrestar los datos puramente económicos utilizados para medir la riqueza de los países y analizar el desarrollo mediante la inclusión de otros factores.
Para esta variable se estandarizan las siguientes categorías en las que los países se dividen en función de su IDH respectivo:
IDH baja: reúne a todos los países con IDH por debajo de 0,500.
IDH media: países con IDH entre 0,500 y 0,799.
Alta IDH: países con IDH entre 0,800 y 0,899.
IDH muy alta: países cuya IDH es igual o superior a 0,900.
Fuente: PENA, Rodolfo F. Alves. “Como é feito o cálculo do IDH?”; Brasil Escola. Disponible en: https://brasilescola.uol.com.br/geografia/desenvolvimento-humano.htm. Consultado el 25 de marzo de 2020.
Los ejemplos citados anteriormente muestran que los criterios con base matemática no son adecuados para todas las situaciones. En la definición de clases para construir una tabla de frecuencias, las reglas que se conocen en la literatura y se presentan aquí son meramente indicativas. La definición de clases, así como el número de clases, deben basarse primero en el conocimiento del fenómeno en estudio y sus objetivos. No hay fórmulas que se apliquen correctamente a todas las situaciones. Incluso cuando el número de clases resultantes del cálculo es igual al número de clases predefinidas, los intervalos de clase no coincidirán con los valores predefinidos. Y ahí es exactamente donde está el problema. Los intervalos de clase son atributos cuantitativos que deben significar una condición o un estado de la variable. Por ejemplo, una persona con un nivel de colesterol de 260 mg/dl no es saludable, porque tiene colesterol por encima de lo normal. Asimismo, un país con un Índice de Desarrollo Humano valorado por debajo del 0,5 está subdesarrollado, ya que sin duda es de baja IDH. Por lo tanto, agrupar datos variables con categorías predefinidos sin respetar estas mismas categorías da como resultado la incapacidad de enlazar el intervalo de clases a su significado respectivo de los valores del intervalo de clases. Esta falta de conexión entre los valores cuantitativos (valores de intervalo de clase) y las (categorías variables) cualitativas empobrece la interpretación de los datos e incluso puede tergiversar la interpretación de los datos y dar lugar a conclusiones erróneas.
Por lo tanto, para las variables con categorías predefinidas, el criterio más adecuado para la construcción de la distribución de frecuencias es el uso de estas categorías y sus respectivos valores como cuerpo de la tabla. Este criterio asocia los valores de las categorías con los atributos cualitativos respectivos que permiten una interpretación clara de los datos.
Cuando las variables no tienen categorías predefinidas y agotan la búsqueda de pistas o indicadores que ayuden a crear las categorías, sin ser por criterio matemático, aquí se sugiere el uso de la teoría de la Distribución Normal de Gauss para la categorización variable. Con ello se pretende crear categorías que permita vincular lo cuantitativo a lo cualitativo y hacer más perceptible la interpretación de los datos.
La teoría de distribución normal de Gauss, ampliamente referenciada en la literatura (RICE y SCOTT, 2005), establece que para un conjunto de datos normales (simétricos, unimodales), aproximadamente el 68% de los datos se encuentran hasta una unidad de desviación estándar de la media, aproximadamente el 95% de los datos se encuentran hasta dos unidades de desviación estándar media y el 99% de los datos se encuentran hasta tres unidades de desviación estándar media.
Tabla 4: Caracterización como la distribuición normal
| ± 1S | 68% de los datos |
| ± 2S | 95% de los datos |
| ± 3S | 99% de los datos |
Fuente: adaptado por Rice y Scott (2005)
Así, se establece como criterio para la definición de categorías de la Teoría de la Distribución Normal, el uso del rango de variación del 68%, de la siguiente manera: Cuadro 5: Base para la categorización variable
| Categoría o nombre de grado | Categoría o valor de grado |
| Por encima de la media | Arriba ( + 1S) |
| Dentro de la media | Entre (± 1S) |
| Por debajo de la media | Abajo ( 1S ) |
Fuente: autor.
Esta sugerencia de categorización de variables se basa en el cálculo de una medida de tendencia central, la media y una medida de variabilidad, la desviación estándar. Los valores que se encuentran en una desviación estándar de la media se consideran cercanos a la media, por lo que se sugiere la designación de la categoría “dentro de la media” o “alrededor de la media”. Los valores que están fuera de este rango se consideran distantes de la media y se sugieren las designaciones “por encima de la media” y “por debajo de la media”, respectivamente. De esta manera obtenemos categorías que dan sentido a los valores de la variable haciendo la interpretación de datos más clara.
Sin embargo, la metodología propuesta debe aplicarse siempre, cuidando las condiciones específicas de cada caso. Siempre se obtienen 3 clases, y si los datos se extraen de hecho de una población normal, la segunda clase tendrá una frecuencia relativa alrededor del 68% y las otras dos alrededor del 16% cada una, lo que puede, en algunos casos, no ser deseable. Por otro lado, si hay algunas/muchas observaciones atípicas en los datos o si la distribución subyacente es sesgada, multimodal, el método en cuestión no producirá los resultados deseados. De todos modos, es un criterio que, bien considerado su aplicación, puede ayudar a mejorar la interpretación de los datos y, por lo tanto, la comprensión de un determinado fenómeno.
2.2 DEMOSTRACIÓN DE LA CONSTRUCCIÓN DE TABLAS DE DISTRIBUCIÓN DE FRECUENCIAS
2.2.1 RECOPILACIÓN DE DATOS
En un proceso de muestreo llevado a cabo durante el período de inscripción para los exámenes de acceso a la Facultad de Ciencias de la Universidad Agostinho Neto en Luanda – Angola, en los años académicos 2008 y 2009, se obtuvieron datos, entre otras variables, de edad (expresadas en años), de peso (expresados en kilogramos) y la altura (expresada en metros y centímetros) de los candidatos. El tamaño de la muestra fue de 4298 sujetos en 2008 y 1749 sujetos en 2009, lo que constituye una muestra global de 6047 individuos.
2.2.2 DISTRIBUCIÓN DE FRECUENCIA SIMPLE
Es la que se muestra debajo de una sencilla tabla de distribución construida utilizando los datos de la edad.
Tabla 6: Distribución de frecuencia simple de las edades de los individuos muestreados.
| individuos | ||
| Actos | 2008 | 2009 |
| 16 | 45 | 6 |
| 17 | 142 | 24 |
| 18 | 365 | 131 |
| 19 | 458 | 217 |
| 20 | 672 | 223 |
| 21 | 605 | 256 |
| 22 | 507 | 240 |
| 23 | 431 | 207 |
| 24 | 320 | 129 |
| 25 | 198 | 92 |
| 26 | 152 | 74 |
| 27 | 91 | 31 |
| 28 | 64 | 31 |
| 29 | 55 | 15 |
| 30 | 51 | 19 |
| 31 | 31 | 11 |
| 32 | 18 | 11 |
| 33 | 8 | 4 |
| 34 | 20 | 6 |
| 35 | 11 | 3 |
| 36 | 12 | 2 |
| 37 | 8 | 1 |
| 38 | 6 | 2 |
| … | … | … |
Fuente: autor.
El Cuadro 6, de distribución simple de frecuencias, muestra su insuficiencia con el fin de resumir grandes cantidades de datos. La tabla es demasiado larga en la vertical y, sobre todo, no permite la lectura de las características de los datos.
2.2.3 TABLA DE DISTRIBUCIÓN DE FRECUENCIAS DE LAS CLASES A DEFINIR
La edad es una variable que, a efectos del análisis demográfico, tiene categorías predefinidos. Sin embargo, para otros fines, esta definición de categorías puede no ser adecuada, como es el caso del análisis de la edad de los candidatos para el examen de acceso a la Universidad. En este caso concreto, el objetivo es evaluar la variabilidad de edad del candidato, determinar el candidato con la edad más alta y la más baja, respectivamente, así como analizar la variabilidad de los datos. Es importante saber a qué intervalos se distribuye la edad de la mayoría de los candidatos para sacar conclusiones sobre el perfil de los estudiantes que terminan la escuela secundaria y por lo tanto son candidatos potenciales para la educación superior.
A efectos de demostración, una submuestra de 182 candidatos se retiró aleatoriamente de la muestra global para mostrar cómo se debe categorizar la variable antes de la construcción de la distribución de frecuencias.
Tabla 7: Edad de 182 candidatos inscritos para los exámenes en la Facultad de Ciencias de la Universidad Agostinho Neto, en el año académico 2009.
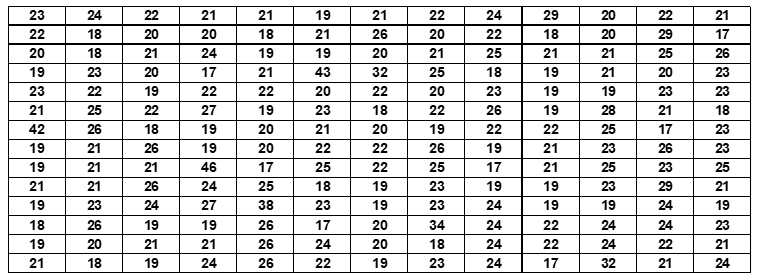
Para estos 182 datos la media es de 22 años y la desviación estándar es de 4 años. El uso de la teoría de distribución normal de Gauss para la definición de categorías descrita en la sección 2.1 da como resultado la siguiente categorización de la variable y su respectiva distribución de frecuencias:
Tabla 8: Categorización de la edad de los candidatos
| Nombre de categoría o grado | Categoría o valor de grado |
| Por encima de la media | > 26 (22 + 4) |
| Dentro de la media | 18 – 26 (22 ± 4) |
| Por debajo de la media | < 18 (22 – 4) |
Hechicería: Autor
Tabla 9: Distribución de frecuencias de la edad de 182 candidatos al examen de acceso.
| Edad (en años) | Número de candidatos | |
| Por encima de la media (> 26) | 13 | 7% |
| Dentro de la media (18 – 26) | 162 | 89% |
| Por debajo de la media (< 18) | 7 | 4% |
Fuente: Autor
Una vez aplicada la teoría Gauss y construida la tabla de distribución de frecuencias, su interpretación es ahora fácil y clara de hacer. La distribución de frecuencias muestra que la mayoría de los 182 candidatos, que representan el 89% de ellos, tienen entre 18 y 26 años y son considerados candidatos con una edad dentro de la media. El porcentaje de candidatos por encima y por debajo de la media es comparativamente residual, siendo del 7% y del 4%, respectivamente. Esta información es de gran importancia para la gestión de la Universidad que puede hacer el mejor uso de la misma para lo que considera conveniente.
2.2.4 DISTRIBUCIÓN DE FRECUENCIAS UTILIZANDO CATEGORÍAS PREDEFINIDAS
Los valores de referencia y las categorías respectivas, estandarizados y certificados por la comunidad científica mundial a través de la Organización Mundial de la Salud (como ya se describe en la sección 2.1) se utilizan como cuerpo de la tabla, lo que resulta en la siguiente distribución de frecuencia del Índice de Masa Corporal de los candidatos al examen de acceso en los años académicos de 2008 y 2009:
Tabla 10: Distribución del IMC de los individuos muestreados.
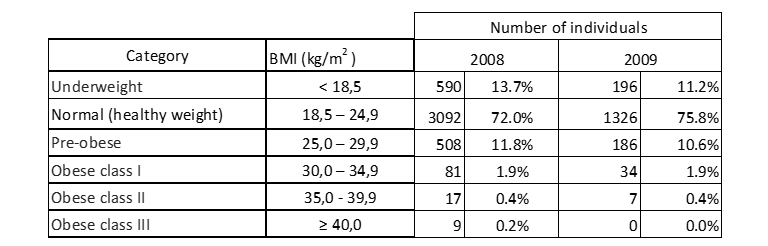
El Cuadro 10 indica que la mayoría de los candidatos tanto en 2008 como en 2009, tienen un peso normal. Afortunadamente, el número de personas con obesidad de grado III, y por lo tanto con un gran riesgo para la salud, es muy bajo en 2008 e inexistente en el año siguiente.
2.2.5 USO DE CATEGORÍAS PREDEFINIDOS FRENTE A CRITERIOS MATEMÁTICOS EN LA CONSTRUCCIÓN DE TABLAS DE DISTRIBUCIÓN DE FRECUENCIAS DE CLASE
Se muestra debajo de la insuficiencia de los criterios matemáticos para la construcción de tablas de distribución de frecuencias de clases para variables con categorías predefinidas.
Consideremos los datos del Índice de Masa Corporal para el año académico 2008, un total de 4297 individuos. Examinando los criterios descritos en el punto 2.1, aquellos que establecen 6 como número mínimo de categorías (DAWSON y TRAPP, 2003) coinciden con el número de categorías predefinidas para el IMC. Una vez definido el número de categorías, se debe identificar el valor máximo y el valor mínimo para calcular la amplitud total, que a su vez se utilizará para calcular el intervalo de clase.
Tabla 11: Estadísticas resumidas de los datos muestreados
| Tamaño de la muestra | 4297 |
| Valor máximo | 49 |
| Valor mínimo | 8 |
| Amplitud (máxima – mínima) | 41 |
| Número de clases o categorías | 6 |
| Rango de clases (amplitud dividida por el número de categorías) | 6.8 |
Fuente: Autor
Una vez determinado el intervalo de clases, los límites de cada una de las 6 categorías se pueden calcular finalmente. El límite inferior de la 1ª categoría es el valor mínimo y el límite superior de esta categoría se obtiene agregando el rango de clases. Lo mismo se hace para las otras categorías y se obtiene el siguiente resultado:
Tabla 12: Categorías del IMC y sus valores calculados.
| categoría | Valores del IMC | |
| 1 | 8,0 | 16,2 |
| 2 | 16,3 | 24,5 |
| 3 | 24,6 | 32,8 |
| 4 | 32,8 | 41,0 |
| 5 | 41,0 | 49,2 |
Fuente: Autor
La tabla siguiente muestra una comparación entre los valores calculados y los valores predefinidos.
Tabla 13: Comparación de los valores predefinidos con los valores calculados.
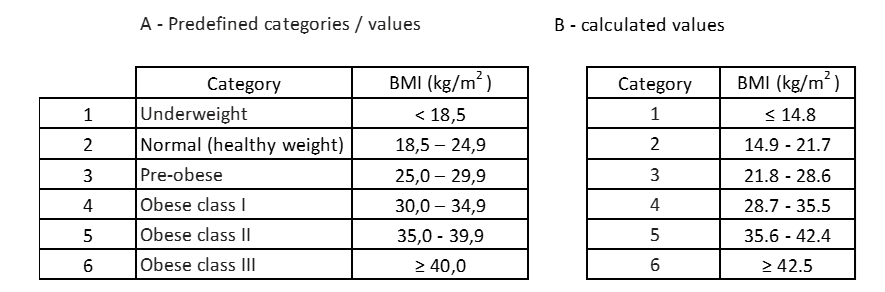
La primera constatación es que las categorías calculadas no tienen su propia designación, es decir, no tienen atributos que califiquen la condición en el individuo. La segunda constatación, a pesar del mismo número de categorías, los valores de categoría cada uno no son iguales. Según las categorías calculadas, los individuos con un IMC entre 14,9 y 21,7 se confundirían con tener un peso normal, cuando en realidad algunos de ellos se encuentran en la condición de “infraponderar”.
3. CONSIDERACIONES FINALES
Las tablas de distribución de frecuencias son herramientas muy útiles en el procesamiento de datos. Sin embargo, su construcción debe cumplir ciertos criterios científicamente válidos. Es esencial garantizar que, independientemente del criterio adoptado, la lectura interpretativa de los datos conduzca a aspectos lógicos y de conclusión comprensibles sobre el comportamiento de la variable. A este respecto, el vínculo entre los atributos cuantitativos y cualitativos es crucial. Por lo tanto, el criterio sugerido, basado en el uso de la Teoría de Distribución Normal de Gauss para la categorización de variables, es bastante factible.
Por todo lo que se ha expresado, hay motivos suficientes para introducir la diferenciación de las tablas de distribución de frecuencias de clase en dos tipos, es decir, tablas de frecuencias de clases o categorías predefinidos y tablas de frecuencias de clases o categorías por definir, lo que sugiere su adopción como concepto.
REFERENCIAS
BEIGUELMAN, Bernardo. Curso prático de bioestatística. 5ª Edição Revisada. FUNPEC Editora, 1994.
CAQUET, René. 250 Exames de Laboratório – Prescrição e Interpretação, 10ª Edição. Rio de Janeiro: Livraria e Editora Revinter, 2011. ISBN 978-85-372-0338-5
DAWSON, Beth & TRAPP, Robert Greig. Bioestatística básica e clínica. 3ª edição. McGraw-Hill Interamericana do Brasil, 2003. ISBN 85-86804-32-0
GRUNDY, Scott M. Third Report of the National Cholesterol Education Program (NCEP) Expert Panel on detection, evaluation, and treatment of high blood cholesterol in adults (Adult Treatment Panel III). Final report. Circulation, 2002, 106:3143–3421 https://ci.nii.ac.jp/naid/10030733296/
KEYS, A., FIDANZA, F., KARVONEN, M. J., KIMURA, N., & TAYLOR, H. L. (1972). Indices of relative weight and obesity. Journal of chronic diseases 25 (6-7), 329-343.
KUZMA, Jan W. & BOHNENBLUST Stephen E. Basic Statistics for the Health Sciences. (Fourth ed.). New York: McGraw-Hill Higher Education 2001. ISBN 0-7674-1752-6
MILTON, Janet Susan. & TSOKOS, Janice Oseth. (1991). Estadistica para biologia y ciencias de la salud. Madrid: Interamericana McGraw-Hill – Madrid.
PEDROSA, Rodrigo Pinto and DRAGER, Luciano Ferreira. “Diagnóstico e classificação da hipertensão arterial sistêmica.” MedicinaNET [https://scholar.google.com/scholar] (2017).
PENA, Rodolfo F. Alves. “Como é feito o cálculo do IDH?”; Brasil Escola. Available on: https://brasilescola.uol.com.br/geografia/desenvolvimento-humano.htm. Retrieved on March 25, 2020.
REIS, Elisabeth. Estatística descritiva. Edições Sílabo, 2005. Lisboa. ISBN 972-618362-6
RICE, Kathryn and SCOTT Paul. Carl Friedrich Gauss. Australian Mathematics Teacher 61.4 (2005): 2-5.
The seventh report of the Joint National Committee on prevention, detection, evaluation, and treatment of high blood pressure. JAMA 2003; 289: 2560-72. Cited in Pedrosa and Drager (2010).
TRIOLA, Marc M. & TRIOLA, Mario F. Bioestatistics for the biological and health sciences. Boston: Pearson Education, 2006. ISBN 0-321-19436-5
WORLD HEALTH ORGANIZATION. “Obesity: preventing and managing the global epidemic.” (2000). Becario de Google
[1] Doctor en Ciencias Agrícolas (Dr. Sc Agr), Agrónomo.
Enviado: Febrero de 2021.
Aprobado: Marzo de 2021.