ОБЗОРНАЯ СТАТЬЯ
VICTORINO, Samuel Carlos [1]
VICTORINO, Samuel Carlos. Другой подход к разработке частотных таблиц с использованием теории нормального распределения GAUSS. Revista Científica Multidisciplinar Núcleo do Conhecimento. Год 06, эд. 03, Vol. 07, стр. 139-154. Март 2021 года. ISSN:2448-0959, Ссылка доступа: https://www.nucleodoconhecimento.com.br/агрономия-ru/частотных-таблиц
АБСТРАКТНЫЙ
Правильная организация данных имеет чрезвычайно важное значение для анализа в процессе статистического вывода, направленного на разработку достоверных выводов и общих рекомендаций по определенному изучаемому вопросу. Специализированная научная литература описывает несколько процедур организации данных в таблицах распределения частот. Однако не часто при использовании инструментов организации данных высовываются неточности. Эти неточности привели к искаженным анализам и нелепым выводам. В настоящем документе представлен критический анализ методов и процедур организации данных, описанных в литературе, в частности распределение данных в таблицах распределения частот и предлагается иной подход при разработке таблиц распределения частот классов. Для всех переменных с предопределенными категориями эти и их соответствующие эталонные значения служат в качестве тела таблицы. Для переменных, которые не имеют заранее определенных категорий, предлагается и оправдано использование обычной теории распределения Gauss в качестве критерия категоризации. Генерируемые категории служат в качестве тела таблицы. Делается вывод о том, что таблицы распределения частот можно выделить на два типа, то есть таблицы распределения частот предопределенных классов или категорий и таблицы частотного распределения классов или категорий, которые должны быть определены, что предполагает их принятие в качестве концепции.
Ключевые слова: Нормальное распределение, Простая таблица распределения частот, таблица распределения частот классов, которые должны быть определены.
1. ВСТУПЛЕНИЕ
Статистические данные, как наука, суммируются в наборе методов и процедур, которые позволяют сбору, организации и представлению данных для их анализа, с тем чтобы получить достоверные выводы и разработку общих рекомендаций по данному изучаемому населению.
Статистика находит применение в самых разных областях знаний, таких как экономика, психология, социология, сельское хозяйство и здравоохранение, помогая в процессе принятия решений на основе анализа данных. Чтобы статистика выполняла эту функцию, совершенно необходимо, чтобы методы и процедуры применялись правильно. Сбор данных включает в себя правильное применение методов выборки, которые завершаются отбором репрезентативных выборок и гарантируют достоверность данных и, в то же время, достоверность исследований; организация и представление данных нацелены на упрощение и сжатие данных в таблицы распределения частот, будь то таблицы с одной частотой или таблицы частот классов. Данные, обобщенные в таблицах, обычно и при необходимости визуализируются в виде графиков, диаграмм и других статистических инструментов. Его правильная организация чрезвычайно важна для анализа данных в процессе статистического вывода.
В специализированной научной литературе описан широкий спектр процедур для систематизации данных в таблицах частотного распределения. Было обнаружено, что часто допускаются неточности в использовании инструментов организации данных, что приводит к искаженным интерпретациям и несоответствующим выводам. В этой статье представлен критический анализ методов и процедур организации данных, описанных в литературе, в частности распределения данных в таблицах частот, и предлагается другой подход к разработке таблиц распределения частот.
2 . ТЕОРЕТИЧЕСКИЕ ОСНОВЫ ТАБЛИЦ РАСПРЕДЕЛЕНИЯ ЧАСТОТ
Статистика делится на две основные группы: описательная статистика и адская статистика.
Описательная статистика является частью, которая занимается описанием, классификацией, организацией и представлением данных переменной. Он позволяет обобщать данные и помогает описывать атрибуты данной группы данных или популяции с помощью расчета описательных мер, таких как среднее и стандартное отклонение. Табекулярные и графические описательные методы, используемые при поддержке графических возможностей современных компьютеров и различных программ, доступных для того, чтобы сделать этот тип резюме более осуществимым и понятным.
С другой стороны, выводная статистика отвечает за анализ данных с целью получения достоверных выводов и разработки общих рекомендаций в отношении изучаемого населения.
2.1 ТАБЛИЧНЫЕ И ГРАФИЧЕСКИЕ ПРИЕМЫ ОПИСАНИЯ
Необработанные данные переменной, полученные в процессе отбора проб, не позволяют визуализировать какую-либо характеристику выборки и тем более изучаемую популяцию. Поэтому таблицы и графики являются важными статистическими ресурсами в обработке данных.
Таблицы позволяют обобщать и уплотнять большой объем информации, предоставляя исследователю четкий анализ. Графики дополняют таблицы, которые имеют функцию передачи визуального представления о поведении данных. Существует широкий спектр диаграмм, в том числе линейные диаграммы, гистограммы, диаграммы с областями и круговые диаграммы как наиболее распространенные. Что касается таблиц частотного распределения, то принципиально отличаются следующие виды:
1 – Одночастотная таблица распределения
2 – Таблица распределения частот класса
Одна таблица распределения частот содержит два основных столбца. В первом столбце каждое собранное значение вставляется последовательно, раз и в порядке возрастания. Во втором столбце в строку, соответствующую каждому наблюдаемому значению, вставляется количество раз, когда эти значения повторяются в наборе данных, что соответствует соответствующей абсолютной частоте.
Таблица распределения частот классов также содержит два столбца, первый для интервалов классов переменной и второй для числа лиц, принадлежащих к каждому классу, то есть абсолютную частоту класса.
Таблицы распределения одной частоты имеют основной недостаток слишком долгого времени в связи с тем, что все отобранные значения должны быть перечислены и, прежде всего, не позволяют считыть характеристики данных. Эти типы таблиц совершенно неуместны, когда цель состоит в том, чтобы обобщить большие объемы данных. В этих случаях таблицы распределения частот классов являются более подходящими, поскольку они уплотняются большими объемами данных в несколько классов и связывают количественные атрибуты переменной с текущим значением характеристик переменной.
Основополагающим аспектом в разработке таблиц распределения частот классов является определение количества классов, в которых будут оформлены данные. Для этого в литературе описано несколько критериев определения количества классов, большинство из которых основаны исключительно на математике.
Milton и Tsokos (1991) указывают на использование следующих формул для определения количества классов:
1 – Количество классов 5 х lg n, где n является размер выборки
2 – Количество классов
![]()
Beiguelman (2002) указывает, что количество классов составляет от 8 до 20, в зависимости от данных. Для Dawson и Trapp (2003) 6 и 14 классов достаточно, чтобы предоставить достаточную информацию без лишних деталей. Triola и Triola (2006) рекомендуют, чтобы количество классов было от 5 до 20, в то время как Kuzma и Bohnenblust (2001) считают, что количество классов должно быть от 5 до 15. Reis (2005) утверждает, что количество классов должно быть между 4 и 14, а также предлагает использовать одно из следующих решений:
![]()
1 – Количество равных классов 5 для образцов с размером менее 25 и числом классов для образцов с размером равным или более 25.
2 – Используйте формулу Sturges: количество классов = 1 + 3,22 log n
Вышеупомянутое показывает разнообразие критериев, описанных в литературе для строительства таблиц распределения частот. Однако эти критерии имеют общий недостаток, что делает их непригодными в качестве основы для определения количества классов данных по определенным переменным, таким, как переменные в области биологии и медицинских наук, экономики, промышленности, в частности, которые имеют заранее определенные категории, то есть стандартизированные категории. Некоторые из этих переменных описаны ниже и указаны соответствующие эталонные значения заранее определенных категорий.В области биологии:
Пример1: Справочные значения общего холестерина в организме человека Таблица 1: Категории и эталонные значения общего холестерина в организме человека.
| Общий холестерин | Категория |
| < 200 mg/dl | Желательно или нормально |
| 200 – 239 mg/dl | граница |
| ≥ 240 mg/dl | высокий |
Источник: Third Report of the National Cholesterol Education Program (NCEP) Expert Panel on detection, evaluation, and treatment of high blood cholesterol in adults (Adult Treatment Panel III). Final report. Circulation, 2002, 106:3143–3421
Пример 2: Справочные значения индекса массы тела (ИМТ).
ИМТ помогает определить степень ожирения человека в соответствии с Всемирной организацией здравоохранения. Путем расчета и интерпретации ИМТ можно узнать, если человек выше или ниже параметров веса, рекомендованных для их физической структуры. Для расчета ИМТ вес, измеряемый в кг, делится на высоту в квадрате (ИМТ и кг/м2).
Таблица 2: Категории и эталонные значения индекса массы тела
| категория | ИМТ (кг/м2) |
| недовес | < 18,5 |
| Нормальный (здоровый вес) | 18,5 – 24,9 |
| До ожирения | 25,0 – 29,9 |
| Ожирение степень I | 30,0 – 34,9 |
| Ожирение степень II | 35,0 – 39,9 |
| Ожирение степень III | ≥ 40,0 |
Источник: World Health Organization. Obesity (1998): Preventing and managing the global epidemic: report of a WHO Consultation on Obesity, Geneva, 3–5 June 1997. Geneva (CH): World Health Organization; 1998. http://whqlibdoc.who.int/hq/1998/WHO_NUT_NCD_98.1_(p1-158).pdf.
Пример 3 – Классификация артериальной гипертензии. Таблица 3: Классификация артериальной гипертензии
| Классификация артериального давления | Систолическое кровяное давление (mmHg) | Диастолическое кровяное давление (mmHg) |
| нормальный | < 120 | < 80 |
| Предварительная гипертония | 120 – 139 | 80 – 89 |
| фаза 1 (степень I ) гипертония | 140 – 159 | 90 – 99 |
| фаза 2 (степень II) гипертония | ³ 160 | ³ 100 |
Источник: The seventh report of the Joint National Committee on prevention, detection, evaluation, and treatment of high blood pressure. JAMA 2003; 289: 2560-72. Цитируется PEDROSA и DRAGER (2010).
Пример 4: Мочевая кислота является результатом метаболизма пуринов, основных структурных элементов ДНК и РНК, большая часть из пищи. Чрезмерное потребление мяса или алкоголя может повысить уровень мочевой кислоты в крови.
Справочные значения, как правило, от 40 до 60 мг/л для мужчин, от 30 до 50 мг/л для женщин и от 25 до 40 мг/л для детей (CAQUET, 2011).
В области экономики:
Пример 5: Индекс развития человеческого потенциала (ИРЧП) представляет имя статистических данных, созданных Программой развития Организации Объединенных Наций (ПРООН) для противодействия чисто экономическим данным, используемым для измерения благосостояния стран и анализа развития с помощью включения других факторов.
Для этой переменной стандартизировано следующие категории, в соответствии с которыми страны делятся на основе их соответствующих ИРЧП:
Низкий ИРЧП: объединяет все страны с ИРЧП ниже 0.500.
Средний ИРЧП: страны с ИРЧП от 0,500 до 0,799.
Высокая ИРЧП: страны с ИРЧП от 0,800 до 0,899.
Очень высокая ИРЧП: страны, чьи ИРЧП равны или выше 0,900.
Источник: PENA, Rodolfo F. Alves. “Como é feito o cálculo do IDH?”; Brasil Escola. Доступно по: https://brasilescola.uol.com.br/geografia/desenvolvimento-humano.htm. Получено 25 марта 2020 года.
Приведенные выше примеры показывают, что критерии, основанные на математике, подходят не для всех ситуаций. При определении классов для построения частотной таблицы правила, известные в литературе и представленные здесь, являются лишь ориентировочными. Определение классов, а также их количество, в первую очередь должно основываться на знании изучаемого явления и его целей. Не существует формул, подходящих ко всем ситуациям. Даже когда количество классов, полученных в результате вычисления, равно количеству предопределенных классов, диапазоны классов не соответствуют предопределенным значениям. И именно в этом проблема. Диапазоны классов – это количественные атрибуты, которые должны означать условие или состояние переменной. Например, человек с уровнем холестерина 260 мг / дл нездоров, потому что у него уровень холестерина выше нормы. Точно так же страна с Индексом человеческого развития ниже 0,5 является слаборазвитой, поскольку она, несомненно, имеет низкий ИЧР. Таким образом, группировка данных переменных с предопределенными категориями без учета тех же категорий приводит к невозможности связать диапазон классов с соответствующим значением значений диапазона классов. Такое отсутствие связи между количественным (значения интервала классов) и качественным (категории переменных) обедняет интерпретацию данных и может даже исказить интерпретацию данных и привести к ошибочным выводам.
Поэтому для переменных с предопределенными категориями наиболее подходящим критерием для строительства распределения частот является использование этих категорий и их соответствующих значений в качестве органа таблицы. Этот критерий связывает значения категорий с соответствующими качественными атрибутами, позволяющими четко работать с интерпретацией данных.
Когда переменные не имеют предопределенных категорий и исчерпали поиск подсказок или индикаторов, которые помогают создавать категории, не будучи математическим критерием, предлагается здесь использовать теорию нормального распределения Gauss для переменной категоризации. Это направлено на создание категорий, которые делают возможным увязыть количественное с качественным и сделать интерпретацию данных более заметной.
Нормальная теория распределения Gauss, широко упоминаемая в литературе (RICE и SCOTT, 2005), утверждает, что для набора нормальных (симметричных, унимодальных) данных примерно 68% данных находятся до единицы стандартного отклонения среднего, приблизительно 95% данных расположены до двух единиц среднего стандартного отклонения и 99% данных расположены до трех единиц среднего стандартного отклонения.
Таблица 4: Характер как нормальное перераспределение
| ± 1S | 68% данных |
| ± 2S | 95% данных |
| ± 3S | 99% данных |
Источник: адаптированы из Rice и Scott (2005)
Таким образом, он устанавливается в качестве критерия для определения категорий из Теории нормального распределения, использование диапазона вариаций 68%, следующим образом: Таблица 5: Основа для переменной категоризации
| Категория или название класса | Категория или значение класса |
| Выше среднего | Выше (No 1S) |
| В пределах среднего | Между (± 1S) |
| Ниже среднего | Ниже ( 1S ) |
Источник: Автор.
Это предложение категоризации переменных основано на расчете меры центральной тенденции, среднего и меры изменчивости, стандартного отклонения. Значения, на которые находится стандартное отклонение среднего значения, считаются близкими к среднему, поэтому предлагается обозначение категории «в пределах среднего» или «вокруг среднего». Значения, на которые находятся за пределами этого диапазона, считаются удаленными от средних и соответственно обозначений «выше среднего» и «ниже среднего». Таким образом, мы получаем категории, которые придают значение значениям переменной, что делает интерпретацию данных более четкой.
Однако предлагаемую методику необходимо применять всегда с учетом конкретных условий каждого случая. Всегда получается 3 класса, и если данные фактически извлечены из нормальной совокупности, второй класс будет иметь относительную частоту около 68%, а два других – около 16% каждый, что в некоторых случаях может быть нежелательно. С другой стороны, если в данных есть несколько / много нетипичных наблюдений или если лежащее в основе распределение искажено, мультимодальное, рассматриваемый метод не даст желаемых результатов. В любом случае, это критерий, который при правильном его применении может помочь улучшить интерпретацию данных и, таким образом, понимание определенного явления.
2.2 ДЕМОНСТРАЦИЯ ПОСТРОЕНИЯ ТАБЛИЦ РАСПРЕДЕЛЕНИЯ ЧАСТОТ
2.2.1 СБОР ДАННЫХ
В процессе отбора проб, проведенных в период зачисления на вступительные экзамены на факультет наук Университета Agostinho Neto de Luanda – Ангола, в 2008 и 2009 учебных годах были получены данные, среди прочих переменных, от возраста (выраженного в годах), от веса (выраженного в килограммах) и высоты (выраженной в метрах и сантиметрах) кандидатов. Размер выборки составил 4298 предметов в 2008 году и 1749 предметов в 2009 году, что составляет глобальную выборку из 6047 человек.
2.2.2 ПРОСТОЕ РАСПРЕДЕЛЕНИЕ ЧАСТОТЫ
Ниже показана простая таблица распределения, построенная на основе данных о возрасте.
Таблица 6: Простое частотное распределение возрастов отобранных лиц.
| Лиц | ||
| Актов | 2008 | 2009 |
| 16 | 45 | 6 |
| 17 | 142 | 24 |
| 18 | 365 | 131 |
| 19 | 458 | 217 |
| 20 | 672 | 223 |
| 21 | 605 | 256 |
| 22 | 507 | 240 |
| 23 | 431 | 207 |
| 24 | 320 | 129 |
| 25 | 198 | 92 |
| 26 | 152 | 74 |
| 27 | 91 | 31 |
| 28 | 64 | 31 |
| 29 | 55 | 15 |
| 30 | 51 | 19 |
| 31 | 31 | 11 |
| 32 | 18 | 11 |
| 33 | 8 | 4 |
| 34 | 20 | 6 |
| 35 | 11 | 3 |
| 36 | 12 | 2 |
| 37 | 8 | 1 |
| 38 | 6 | 2 |
| … | … | … |
Источник: автор
В таблице 6 простого распределения частоты показано ее неадекватность для целей обобщения больших объемов данных. Таблица слишком длинная по вертикали и, прежде всего, не позволяет считыть характеристики данных.
2.2.3 ТАБЛИЦА ЧАСТОТНОГО РАСПРЕДЕЛЕНИЯ КЛАССОВ, ПОДЛЕЖАЩИХ ОПРЕДЕЛЕНИЮ
Возраст – это переменная, которая для целей демографического анализа имеет заранее определенные категории. Однако для других целей такое определение категорий может не подходить, как в случае анализа возраста кандидатов на вступительные экзамены в университет. В данном конкретном случае цель состоит в том, чтобы оценить изменчивость возраста кандидата, определить кандидата с самым высоким и самым низким возрастом соответственно, а также проанализировать изменчивость данных. Важно знать, через какие промежутки времени распределяется возраст большинства кандидатов, чтобы сделать выводы о характеристиках студентов, получивших среднее образование и, следовательно, потенциальных кандидатов на получение высшего образования.
В демонстрационных целях из глобальной выборки случайным образом была взята подвыборка из 182 кандидатов, чтобы показать, как переменная должна быть отнесена к категории перед построением частотного распределения.
Таблица 7. Возраст 182 кандидата, зачисленных на экзамены факультета естественных наук Университета Agostinho Neto в 2009 учебном году.
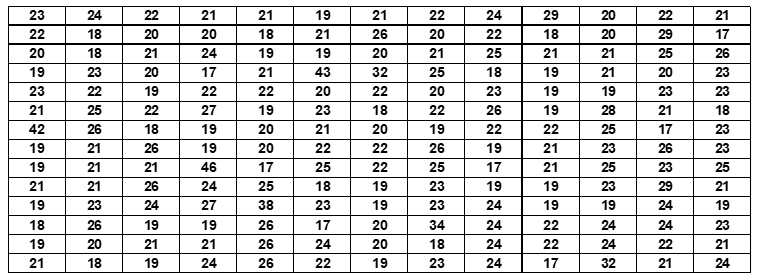
Для этих 182 данных среднее время составляет 22 года, а стандартное отклонение – 4 года. Использование обычной теории распределения Gauss для определения категорий, описанных в разделе 2.1, приводит к следующей категоризации переменной и ее соответствующего распределения частот:
Таблица 8: Категориатио возраста кандидатов
| Категория или название степень | Категория или значение степень |
| Выше среднего | > 26 (22 + 4) |
| В пределах среднего | 18 – 26 (22 ± 4) |
| Ниже среднего | < 18 (22 – 4) |
Сорс: Автор
Таблица 9: Распределение частот в возрасте 182 лет кандидатов на экзамены.
| Возраст (в годах) | Количество кандидатов | |
| Выше среднего (> 26) | 13 | 7% |
| В пределах среднего (18 – 26) | 162 | 89% |
| Ниже среднего (< 18) | 7 | 4% |
Источник: Автор
После применения теории Gauss и построена таблица распределения частот, ее интерпретация теперь проста и ясна. Распределение частот показывает, что большинство из 182 кандидатов, представляющих 89% из них, в возрасте от 18 до 26 лет и считаются кандидатами с возрастом в пределах среднего. Доля кандидатов выше и ниже среднего сравнительно остаточна, составляет 7% и 4% соответственно. Эта информация имеет большое значение для руководства университета, который может наилучшим образом использовать ее для того, что он считает удобным.
2.2.4 РАСПРЕДЕЛЕНИЕ ЧАСТОТ С ИСПОЛЬЗОВАНИЕМ ПРЕДУСТАНОВЛЕННЫХ КАТЕГОРИЙ
Справочные значения и соответствующие категории, стандартизированные и сертифицированные мировым научным сообществом через Всемирную организацию здравоохранения (как уже описано в разделе 2.1), используются в качестве тела таблицы, что приводит к следующему частотному распределению индекса массы тела кандидатов на экзамен в 2008 и 2009 учебных годах:
Таблица 10: Распределение ИМТ отобранных лиц.
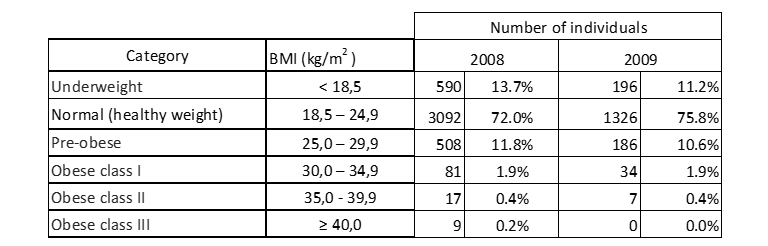
В таблице 10 указывается, что большинство кандидатов как в 2008, так и в 2009 году имеют нормальный вес. К счастью, число людей с ожирением III класса, и, следовательно, с большим риском для здоровья, является очень низким в 2008 году и не существует в следующем году.
2.2.5 ИСПОЛЬЗОВАНИЕ ПРЕДНАЗНАЧЕННЫХ КАТЕГОРИЙ В ОТНОШЕНИИ МАТЕМАТИЧЕСКИХ КРИТЕРИЕВ ПРИ ПОСТРОЕНИИ ТАБЛИЦ РАСПРЕДЕЛЕНИЯ КЛАССОВ ЧАСТОТЫ
Ниже показана неадекватность математических критериев для строительства таблиц распределения частот классов по переменным с заранее определенными категориями.
Рассмотрим данные индекса массы тела за 2008 учебный год, в общей сложности 4297 человек. Если посмотреть на критерии, описанные в пункте 2.1, то критерии, устанавливающие 6 в качестве минимального числа категорий (DAWSON и TRAPP, 2003), совпадают с числом предопределенных категорий ИМТ. После того, как количество категорий определено, необходимо определить максимальное значение и минимальное значение для расчета общей амплитуды, которая, в свою очередь, будет использоваться для расчета интервала класса.
Таблица 11: Краткая статистика выборочных данных
| Размер выборки | 4297 |
| Максимальное значение | 49 |
| Минимальное значение | 8 |
| Амплитуда (максимальная – минимальная) | 41 |
| Количество классов или категорий | 6 |
| Диапазон классов (Амплитуда, разделенная на количество категорий) | 6.8 |
Источник: Автор
После того, как диапазон классов определен, пределы каждой из 6 категорий могут быть окончательно рассчитаны. Нижним пределом 1-й категории является минимальное значение, а верхний предел этой категории получается путем добавления диапазона классов. То же самое делается и для других категорий, и получен следующий результат:
Таблица 12: Категории ИМТ и их рассчитанные значения.
| категория | Значения ИМТ | |
| 1 | 8,0 | 16,2 |
| 2 | 16,3 | 24,5 |
| 3 | 24,6 | 32,8 |
| 4 | 32,8 | 41,0 |
| 5 | 41,0 | 49,2 |
Источник: Автор
В таблице ниже показано сравнение между рассчитанными значениями и предопределенными значениями.
Таблица 13: Сравнение заранее определенных значений с рассчитанными значениями.
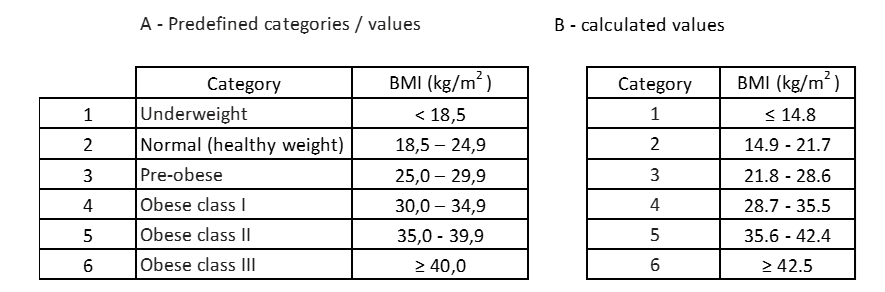
Первый вывод заключается в том, что вычисленные категории не имеют собственного обозначения, то есть не имеют атрибутов, определяющих состояние у человека. Второй вывод: несмотря на одинаковое количество категорий, значения каждой категории не совпадают. По рассчитанным категориям люди с ИМТ от 14,9 до 21,7 будут ошибочно приняты за нормальный вес, хотя на самом деле некоторые из них находятся в состоянии «низкого веса».
3. ОКОНЧАТЕЛЬНЫЕ СООБРАЖЕНИЯ
Таблицы распределения частот являются очень полезными инструментами в обработке данных. Однако их строительство должно соответствовать определенным научно обоснованным критериям. Важно обеспечить, чтобы, независимо от принятого критерия, интерпретационое чтение данных привело к логическим и понятным выводам о поведении переменной. В этой связи решающее значение имеет связь между количественными и качественными атрибутами. Таким образом, предложенный критерий, основанный на использовании теории нормального распределения Gauss для классификации переменных, вполне осуществим.
Несмотря на все, что было выражено, достаточно оснований для того, чтобы ввести дифференциацию таблиц распределения частот классов на два типа, то есть таблицы частот заранее определенных классов или категорий и таблицы частот классов или категорий, которые должны быть определены, предлагая таким образом его принятие в качестве концепции.
РЕКОМЕНДАЦИИ
BEIGUELMAN, Bernardo. Curso prático de bioestatística. 5ª Edição Revisada. FUNPEC Editora, 1994.
CAQUET, René. 250 Exames de Laboratório – Prescrição e Interpretação, 10ª Edição. Rio de Janeiro: Livraria e Editora Revinter, 2011. ISBN 978-85-372-0338-5
DAWSON, Beth & TRAPP, Robert Greig. Bioestatística básica e clínica. 3ª edição. McGraw-Hill Interamericana do Brasil, 2003. ISBN 85-86804-32-0
GRUNDY, Scott M. Third Report of the National Cholesterol Education Program (NCEP) Expert Panel on detection, evaluation, and treatment of high blood cholesterol in adults (Adult Treatment Panel III). Final report. Circulation, 2002, 106:3143–3421 https://ci.nii.ac.jp/naid/10030733296/
KEYS, A., FIDANZA, F., KARVONEN, M. J., KIMURA, N., & TAYLOR, H. L. (1972). Indices of relative weight and obesity. Journal of chronic diseases 25 (6-7), 329-343.
KUZMA, Jan W. & BOHNENBLUST Stephen E. Basic Statistics for the Health Sciences. (Fourth ed.). New York: McGraw-Hill Higher Education 2001. ISBN 0-7674-1752-6
MILTON, Janet Susan. & TSOKOS, Janice Oseth. (1991). Estadistica para biologia y ciencias de la salud. Madrid: Interamericana McGraw-Hill – Madrid.
PEDROSA, Rodrigo Pinto and DRAGER, Luciano Ferreira. “Diagnóstico e classificação da hipertensão arterial sistêmica.” MedicinaNET [https://scholar.google.com/scholar] (2017).
PENA, Rodolfo F. Alves. “Como é feito o cálculo do IDH?”; Brasil Escola. Available on: https://brasilescola.uol.com.br/geografia/desenvolvimento-humano.htm. Retrieved on March 25, 2020.
REIS, Elisabeth. Estatística descritiva. Edições Sílabo, 2005. Lisboa. ISBN 972-618362-6
RICE, Kathryn and SCOTT Paul. Carl Friedrich Gauss. Australian Mathematics Teacher 61.4 (2005): 2-5.
The seventh report of the Joint National Committee on prevention, detection, evaluation, and treatment of high blood pressure. JAMA 2003; 289: 2560-72. Cited in Pedrosa and Drager (2010).
TRIOLA, Marc M. & TRIOLA, Mario F. Bioestatistics for the biological and health sciences. Boston: Pearson Education, 2006. ISBN 0-321-19436-5
WORLD HEALTH ORGANIZATION. “Obesity: preventing and managing the global epidemic.” (2000). Стипендиат Google
[1] Кандидат сельскохозяйственных наук (Dr Sc Ag), агроном.
Представлено: Февраль 2021.
Утверждено: Mарт 2021 года.