ОРИГИНАЛ СТАТЬИ
CHAGAS, Edgar Thiago De Oliveira [1]
CHAGAS, Edgar Thiago De Oliveira. Глубокое обучение и его применение сегодня. Revista Científica Multidisciplinar Núcleo do Conhecimento. 04 год, Эд. 05, том 04, стр. 05-26 мая 2019. ISSN: 2448-0959
РЕЗЮМЕ
Искусственный интеллект больше не является сюжетом для художественных фильмов. Исследования в этой области увеличивается с каждым днем и дает новые знания в машинное обучение. Глубокие методы обучения, также известный как глубокое обучение, в настоящее время используется на многих фронтах, таких как распознавание лиц в социальных сетях, автоматизированных автомобилей и даже некоторые диагнозы в области медицины. Глубокое обучение позволяет вычислительным моделям, состоящим из бесчисленных обрабатывающих слоев, «изучать» представления данных с различными уровнями абстракции. Эти методы улучшили распознавание речи, визуальные объекты, обнаружение объектов, среди возможностей. Тем не менее, эта технология все еще плохо известна, и цель этого исследования заключается в уточнении, как глубокое обучение работает и продемонстрировать свои текущие приложения. Конечно, с распространением этих знаний, глубокого обучения может, в ближайшем будущем, представить другие приложения, что еще более важно для всего человечества.
Ключевые слова: глубокое обучение, машинное обучение, IA, машинное обучение, интеллект.
ВВЕДЕНИЕ
Глубокое обучение понимается как ветвь машинного обучения, основанная на группе алгоритмов, которые стремятся формировать абстракций высокого уровня данных с помощью глубокого графа с несколькими слоями обработки, Состоит из нескольких линейных и нелинейных изменений.
Глубокое обучение работает компьютерная система для выполнения таких задач, как распознавание речи, идентификация изображения и проекции. Вместо того, чтобы организовывать информацию, чтобы действовать через заранее оговоренным уравнениям, это обучение определяет основные шаблоны этой информации и учит компьютеры развиваться путем идентификации моделей в обработке слоев.
Этот вид обучения является всеобъемлющей отраслью методов машинного обучения, основанных на изучении представлений информации. В этом смысле глубинное обучение представляет собой набор алгоритмов машинного обучения, которые пытаются интегрировать несколько уровней, которые являются признанными статистическими моделями, соответствующими разным уровням определений. Более низкие уровни помогают определить многие понятия более высокого уровня.
Есть бесчисленное множество текущих исследований в этой области искусственного интеллекта. Совершенствование методов глубокого обучения внедрило улучшения в способности компьютеров понять, что запрашивается. Исследования в этой области направлена на поощрение более совершенных представлений и разработать модели для выявления этих представлений из информации не помечены в больших масштабах, некоторые в качестве основы в выводах неврологии и в интерпретации Обработка данных и коммуникативные паттерны в нервной системе. С 2006 года этот вид обучения возник как новый филиал исследований машинного обучения[2].
Недавно, новые методы были разработаны из глубокого обучения, которые повлияли несколько исследований по обработке сигнала и идентификации шаблона. Обратите внимание на ряд новых проблемных команд, которые могут быть решены с помощью этих методов, в том числе машинного обучения и искусственного интеллекта ключевых точек.
Существует большое внимание средств массовой информации, в соответствии[3] с Yang et al, о достижениях, достигнутых в этой области. Крупные технологические организации применили много инвестиций в исследования глубокого обучения и их новых приложений.
Глубокое обучение включает в себя обучение на различных уровнях представительства и неосязаемости, которые помогают в процессе понимания информации, образов, звуков и текстов.
Среди выставок, доступных на глубоком обучении, можно выделить два ярких момента. Первый показывает, что они являются моделями, сформированные бесчисленными слоями или ступенями нелинейной обработки данных и также контролируются практикой обучения или нет, о представлении атрибуций в более поздних и неосязаемых слоях.
Понятно, что глубокое обучение находится в суставах между ветвями исследований нейронной сети, AI, графическое моделирование, идентификации и оптимизации шаблонов и обработки сигналов. Внимание уделяется глубокому обучению в связи с улучшением мастерства обработки чипов, значительным увеличением размера информации, используемой для обучения, и последними достижениями в исследованиях в области машинного обучения и обработки сигналов.
Этот прогресс позволил практике глубокого обучения эффективно использовать сложные и нелинейные приложения, определить представления распределенных и иерархических ресурсов, и обеспечить эффективное использование Маркированные и немаркированные сведения.[4]
Глубокое обучение относится к комплексному классу методов и проектов машинного обучения, которые объединяют характеристику использования многих слоев нелинейных обработанных данных иерархического характера. В связи с использованием этих методов и проектов, большая часть исследований в этой области может быть классифицирована в трех основных наборов, в соответствии с Пан[5]г et al, которые являются глубокими сетями для неконтролируемого обучения; Контролируется и гибрид.
Глубокие сети для неконтролируемого обучения доступны для задержания высокой последовательности корреляции анализируемой или идентифицируемой информации для проверки или ассоциации стандартов, когда нет данных о стереотипах классов Доступно в базе данных. Изучение атрибуции или неконтролируемого представительства относится к глубоким сетям. Кроме того, вы можете искать назначение сгруппированных статистических дистрибутивов видимых данных и связанных с ним классов, когда они доступны, и могут быть покрыты как часть видимых данных.
Глубокие нейронные сети для контролируемого обучения должны обеспечивать дискриминацию в отношении классификации, обычно индивидуализации последующего распределения классов, связанных с видимой информацией, которая всегда Доступно для этого контролируемого обучения, также упоминается как глубокие дискриминационные сети.
Глубокие гибридные сети подсвечиваются дискриминацией, выявлемой с результатами генеративных или неконтролируемого глубоких сетей, которые могут быть достигнуты за счет совершенствования и/или упорядочение сетей, находящихся под глубоким наблюдением. Его атрибуции также могут быть достигнуты, когда дискриминационные руководящие принципы для контролируемого обучения используются для оценки стандартов в любой генеративной или неконтролируемой глубокой сети[6].
Глубокие и периодические сети являются моделями, которые представляют высокую производительность в вопросах идентификации сомнительных моделей в Ivain и реч[7]и. Несмотря на свою силу представительства, большие трудности в формировании глубоких нейронных сетей с общим использованием сохраняется и по сей день. В связи с рецидивирующими нейронными сетями, исследования Хинтона[8] et al инициировали формование слоями.
Настоящее исследование направлено на разъяснение прогресса глубокого обучения и его применения в соответствии с последними исследованиями. Для этого будет проведено качественное описательное исследование с использованием книг, диссертаций, статей и веб-сайтов, чтобы концептуально достижения в области искусственного интеллекта и особенно в глубоком обучении.
С прошлого десятилетия наблюдается растущий интерес к машинному обучению, учитывая, что существует постоянно увеличивающий взаимодействие между приложениями, будь то мобильные или компьютерные устройства, с физическими лицами, через программы для обнаружения спама, Распознавание фотографий в социальных сетях, смартфонов с распознаванием лица, среди прочих применений. По данным Gartner вс[9]е корпоративные программы будут иметь некоторые функции, связанные с машинного обучения до 2020 года. Эти элементы направлены на обоснование разработки этого исследования.
ИСТОРИЧЕСКОЕ РАЗВИТИЕ ГЛУБОКОГО ОБУЧЕНИЯ
Искусственный интеллект не является недавним открытием. Она исходит из десятилетия 1950, но, несмотря на эволюцию своей структуры, некоторые аспекты доверия не хватало. Одним из таких аспектов является объем данных, который возник в широком разнообразии и скорости, что позволяет создавать стандарты с высокой степенью точности. Тем не менее, соответствующий момент был о том, как большие модели машинного обучения были обработаны с большими объемами информации, потому что компьютеры не могут выполнять такие действия.
В этот момент был идентифицирован второй аспект, который упоминается параллельно программированию на графических Процессерах. Графические процессорные единицы, которые позволяют параллельно осуществлять математические операции, особенно с матрицами и векторами, которые присутствуют в моделях искусственных сетей, позволили нынешней эволюции, т.е. Суммирование больших объемов данных (большой объем данных); Параллельная обработка и модели машинного обучения представляют собой в результате искусственный интеллект.
Базовая единица искусственной нейронной сети — это математический нейрон, называемый также узлом, основанный на биологическом нейроне. Связи между этими математическими нейронами связаны с биологическими мозгами, и особенно в том, как эти ассоциации развиваются с течением времени, называемых «обучением».
В период между второй половиной десятилетия 80 и началом десятилетия 90, произошло несколько соответствующих достижений в структуре искусственных сетей. Тем не менее, количество времени и информации, необходимой для достижения хороших результатов, откладывал принятие, затрагивающих интерес к искусственному интеллекту.
В начале 2000 годов, мощность вычислений расширилась и рынок испытал "бум" вычислительных технологий, которые не были возможны раньше. Именно тогда, когда глубокое обучение возникло из-за большого вычислительного роста того времени, как необходимый механизм для разработки систем искусственного интеллекта, выиграв несколько конкурсов машинного обучения. Интерес к глубокому обучению продолжает расти до сегодняшнего дня, и несколько коммерческих решений возникают во все времена.
С течением времени, несколько исследований были созданы для того, чтобы имитировать функционирование мозга, особенно в процессе обучения для создания интеллектуальных систем, которые могли бы воссоздать такие задачи, как классификация и распознавание образов, среди Другие виды деятельности. Выводы этих исследований породили модель искусственного нейрона, размещенный позже в взаимосвязанной сети, называемой нейронной сетью.
В 1943, Уоррен Маккалок, нейрофизиолог и Уолтер Питтс, математик, создал простую нейронную сеть, используя электрические схемы и разработал компьютерную модель для нейронных сетей на основе математических концепций и алгоритмов, называемых пороговых Логика или пороговая логика, которая позволяла исследовать нейронную сеть, разделенную на две нити: фокусируясь на биологическом процессе мозга, а другой фокусируясь на применении этих нейронных сетей, направленных на искусственный интеллект.[10]
Дональд Х[11]ебб, в 1949, написал произведение, где он сообщил, что нейронные цепи усилены больше они используются, как сущность обучения. С развитием компьютеров в 1950 десятилетие, идея нейронной сети приобрел силу и Nathanial Рочестер[12] из IBM в лабораториях исследования пытались составить один, но не удалось.
Летний исследовательский проект Дартмута[13] по искусственному интеллекту, в 1956, увеличил нейронные сети, а также искусственный интеллект, поощряя исследования в этой области по отношению к нейронной обработке. В последующие годы Джон фон Нейман имитировал простые функции нейронов с вакуумными трубами или телеграфами, в то время как Фрэнк Розенблатт инициировал проект Перцептрон, анализируя функционирование глаза мухи. Результатом этого исследования стало оборудование, которое является старейшей нейронной сетью, используемой до настоящего времени. Однако Перцептрон очень ограничен, что доказали Марвин и Пейперт[14]
Рисунок 1: структура нейронной сети
Несколько лет спустя, в 1959 году, Бернард Уидроу и Марциан Хофф разработали две модели под названием «Адалин» и «Мадалин». Номенклатура вытекает из использования нескольких элементов: адаптивной линейной. Адалин был создан для идентификации бинарных шаблонов, чтобы сделать прогнозы о следующем битом, в то время как "Маделин" была первой нейронной сетью, прилотой к реальной проблеме, используя адаптивный фильтр. Система все еще используется, но только коммерческие.[15]
Достигнутый ранее прогресс привел к убеждению, что потенциал нейронных сетей ограничен электроникой. Он был задан вопрос о воздействии, что "умные машины" будет иметь на человека и общества в целом.
Дебаты о том, как искусственный интеллект повлияет на человека, вызвали критику по поводу исследований в нейронных сетях, что привело к сокращению финансирования и, следовательно, исследования в области, которая оставалась до 1981.
В следующем году, несколько событий ререакинтерес в этой области. Джон Хопфилд из Калифорнийского технологического института представил подход к созданию полезных устройств, демонстрируя свои назначени[16]я. В 1985 году американский институт физики начал ежегодное совещание под названием нейронные сети для вычислений. В 1986, средства массовой информации начали сообщать о нейронных сетях нескольких слоев, и три исследователя представили похожие идеи, называемые Backpropagation сетей, потому что они распространяют шаблоны идентификации сбоев по всей сети.
Гибридные сети имеют только два слоя, в то время как сети обратного распростра[17]нения представляют многие, так что эта сеть сохраняет информацию медленнее, потому что им нужно тысячи итераций, чтобы узнать, но и представить больше результатов Точная. Уже в 1987 году была первая Международная конференция по нейросетям института электротехнического и электронного инженера (IEEE).
В 1989 году ученые создали алгоритмы, которые использовали глубокие нейронные сети, но время «обучения» было очень долгим, что помешало его применению к реальности. В 1992, Juyang Weng Diulga метод Кресскиртрон для выполнения распознавания 3D объектов из бурных сцен.
В середине 2000 лет термин «глубокое обучение» или «глубокое обучение» начинают распространяться после статьи Джеффри Хинтона и Руслана Салахатдинова, к[18]оторые продемонстрировали, как многослойная нейронная сеть может быть предварительно обучалась, один слой в то время, .
В 2009, нейронные сети системы обработки семинар по глубокому обучению для распознавания голоса происходит, и это проверяется, что с обширной группой данных, нейронных сетей не нуждаются в предварительной подготовки и отказов падения ставки Значительно[19].
В 2012 г. в некоторых задачах исследования обеспечили алгоритмы идентификации искусственных узоров с производительностью человека. И алгоритм Google идентифицирует кошек.
В 2015, Facebook использует глубокое обучение, чтобы автоматически пометить и распознать пользователей в фотографиях. Алгоритмы выполняют задачи распознавания лиц с помощью глубоких сетей. В 2017 году было крупномасштабное внедрение глубокого обучения в различных бизнес-приложениях и мобильных устройствах, а также прогресс в исследованиях[20].
Обязательство глубокого обучения заключается в том, чтобы продемонстрировать, что довольно обширный набор данных, быстрых процессоров и довольно сложный алгоритм позволяет компьютерам выполнять такие задачи, как распознавание образов и голоса, среди прочих Возможности.
Исследование нейронных сетей приобрело известность благодаря перспективным атрибутам, представленным моделями нейронной сети, созданными благодаря недавним технологическим нововведениям, которые позволяют разрабатывать дерзкие нейронные структуры Параллельно с оборудованием, достигая удовлетворительных характеристик этих систем, с превосходной производительностью к обычным системам, включая. Эволюция нейронных сетей – это глубокое обучение.
DEEP LEARNING
Изначально она должна различать искусственный интеллект, машинное обучение и глубокое обучение.
Рисунок 2: искусственный интеллект, машинное обучение и глубокое обучение
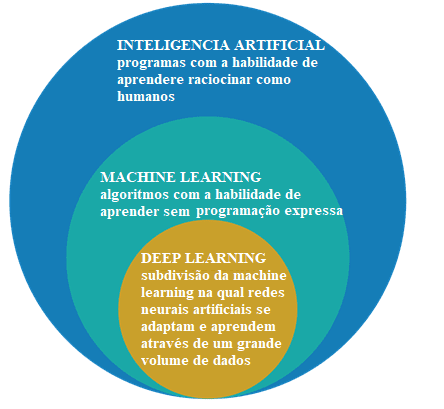
Область изучения искусственного интеллекта является исследованием и дизайном интеллектуальных источников, то есть системы, которая может принимать решения, основанные на характерной, считающийся умной. В искусственном интеллекте есть несколько методов, которые моделирует эту характеристику и среди них является сфера машинного обучения, где решения сделаны (интеллект) на основе примеров, а не определяется программирования.
Алгоритмы машинного обучения требуют информации для удаления функций и элементов, которые могут быть использованы для принятия будущих решений. Глубокое обучение является подгруппой методов машинного обучения, которые обычно используют глубокие нейронные сети и нуждаются в большом количестве информации для обучения[21].
По словам Сантаны [22]есть некоторые различия между методами машинного обучения и методы глубокого обучения, и основными из них являются необходимость и влияние объема данных, вычислительной мощности и гибкости в моделировании проблем.
Машинное обучение нуждается в данных для идентификации закономерностей, но есть два вопроса, относящихся к размерности и стагнации производительности путем внедрения большего количества данных за пределы себя. Подтверждено, что при этом происходит снижение значительной производительности. По отношению к размерности то же самое происходит, как есть много информации, чтобы обнаружить, через классические методы измерения проблемы.
Рисунок 3: сравнение глубокого обучения с другими алгоритмами относительно объема данных.
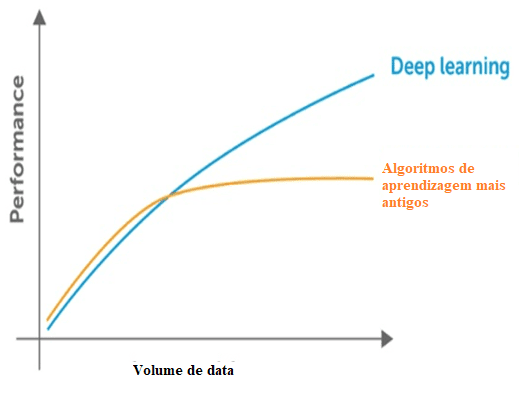
Классические методы также представляют точку насыщения по отношению к количеству данных, то есть максимальный предел для извлечения информации, которая не происходит с глубоким обучением, созданный для работы с большим объемом данных.
По отношению к вычислительной мощности для глубокого обучения, ее структуры являются сложными и требуют большого объема данных для ее подготовки, которая демонстрирует свою зависимость от больших вычислительных мощности для реализации этих практик. В то время как другие классические практики нужно много вычислительной мощности в качестве процессора, глубокие методы обучения превосходят.
Поиск, связанный с параллельными вычислениями и использованием графических процессоров с CUDA-вычислительными унифицированными устройством архитектуры или унифицированными вычислениями устройства инициировали глубокое обучение, как это было неосуществимо с использованием простого процессора.
В сравнении с обучением глубокой нейронной сети или глубоким обучением с использованием ЦП получается, что добиться удовлетворительных результатов даже при длительном обучении было бы невозможно.
Глубокое обучение, также известное как глубокое обучение, является частью машинного обучения, и оно применяет алгоритмы для обработки данных и воспроизведения обработки, осуществляемой человеческим мозгом.
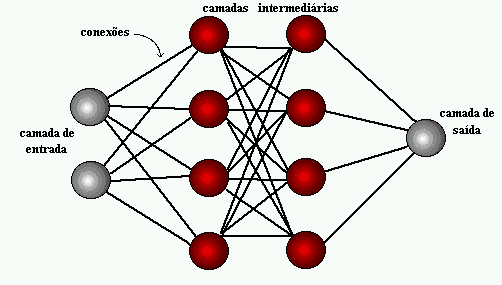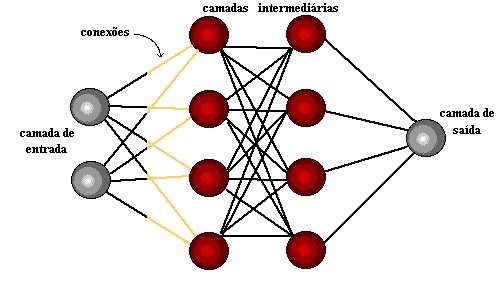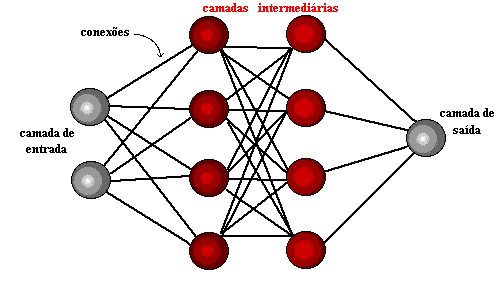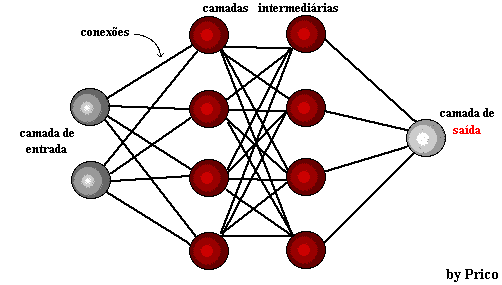
Глубокое обучение использует слои математических нейронов для обработки данных, идентификации речи и распознавания объектов. Данные передаются через каждый слой, при этом выход из предыдущего слоя предоставляет ввод следующему слою. Первый слой в сети называется входным слоем, а последний-выходной. Промежуточные слои называются скрытыми слоями, и каждый слой сети формируется простым и равномерным алгоритмом, который включает в себя вид функции активации.
Рисунок 4: простая нейронная сеть и глубокая нейронная сеть или глубокое обучение
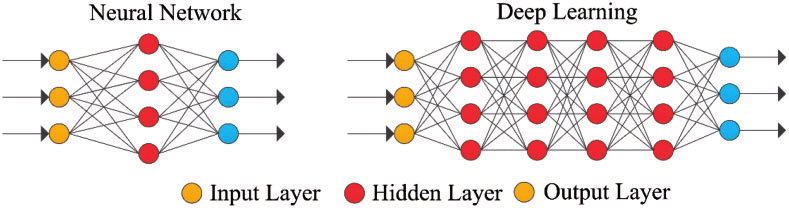
Самые крайние слои желтого цвета являются входными или выходными слоями, а промежуточные или скрытые слои находятся в красном. Глубокое обучение отвечает за последние достижения в области вычислительной техники, распознавания речи, обработки языка и слуховой идентификации, основанные на определении искусственных нейронных сетей или вычислительных систем, которые воспроизводят Путь человеческого мозга действует.
Еще одним аспектом глубокого обучения является извлечение ресурсов, которое использует алгоритм для автоматического создания соответствующих параметров информации для обучения, обучения и понимания, задача инженера искусственного интеллекта.
Глубокое обучение – это эволюция нейронных сетей. Интерес к глубокому обучению постепенно растет в средствах массовой информации и несколько исследований в области были распространены и его применение достигло автомобилей, в диагностике рака и аутизма, среди других приложений[23]
Первые алгоритмы глубокого обучения с несколькими слоями нелинейных заданий представляют свои истоки в Алексее Григорьевиче Ивахненко, который разработал метод групповой манипуляции данными и Валентин Григор ' евич Лапа, автор работы Кибернетика и методы прогнозирования в 1965 году.[24]
Оба использовали тонкие и глубокие модели с функциями полиномиальной активации, которые исследовались с использованием статистических методов. С помощью этих методов они отбирали в каждом слое лучшие ресурсы и передавались на следующий слой, без использования обратного распространения, чтобы "обучить" полную сеть, но использовали минимальные квадраты на каждом слое, где предыдущие были установлены от Самостоятельно в более поздних слоях, вручную.
Рисунок 5: строение первой глубокой сети, известной как Алексей Григоревич Ивахненко
В конце десятилетия 1970 зимы искусственного интеллекта произошло, резкое сокращение финансирования исследований по этому вопросу. Воздействие ограничило прогресс в глубоких нейронных сетях и искусственном интеллекте.
Первые конволюционных нейронные сети были использованы Кунихико Фукусима, с несколькими слоями группировки и извилин, в 1979. Он создал искусственную нейронную сеть под названием Неокогнитрон с иерархической и многослойной планировкой, которая позволила компьютеру идентифицировать визуальные паттерны. Сети были аналогичны современным версиям, при этом «тренировка» была сосредоточена на стратегии усиления периодической активации в бесчисленных слоях. Кроме того, конструкция Фукусима сделал возможным для наиболее релевантных ресурсов, которые будут адаптированы вручную за счет повышения значимости некоторых соединени[25]й.
Многие руководящие принципы Неокогнитрон все еще используются, так как "сверху вниз" и новые методы обучения способствовали реализации различных нейронных сетей. Когда несколько шаблонов представлены в то же время, модель выборочного ухода может отделить их и идентифицировать отдельные шаблоны, обращая внимание на каждый из них. Более современные Неокогнитрон можно определить шаблоны с отсутствием данных и завершить изображение, вставив недостающее информацию, которая называется вывод.
Обратное распространение используется для глубокого обучения провал обучение прогрессировала от 1970 года, когда Сепо Linnainmaa написал тезис, вставив код Фортрана для обратного распространения, без успеха до 1985. Румельхарт, Уильямс и Хинтон затем продемонстрировали обратное распространение в нейронной сети с представлениями распределения.
Это открытие позволило дебаты по AI достичь когнитивной психологии, которая инициировала вопросы о человеческом понимании и его связь с символической логики, а также соединений. В 1989, Янн Летун выполнил практическую демонстрацию обратного распространения, с сочетанием конволюционных нейронных сетей для идентификации письменных цифр.
В этот период вновь возникла нехватка средств на исследования в этой области, известная как вторая зима IA, которая произошла между 1985 и 1990, также затрагивающих исследования в нейронных сетях и глубокого обучения. Ожидания, представленные некоторыми исследователями, не достигли ожидаемого уровня, который глубоко раздражал инвесторов.
В 1995 году дана Кортес и Владимир Вадник создали поддержку векторной машины [26]или поддерживающей векторной машины, которая была системой картирования и идентификации подобной информации. Длинная Краткосрочная память-LSTM для периодических нейронных сетей была разработана в 1997 году, Зепп Хохрайтер и Юрген Шмидхубе[27]р.
Следующий шаг в эволюции глубокого обучения произошел в 1999, когда обработка данных и обработка графических процессоров (GPU) стали быстрее. Использование графических процессоров и ее быстрая обработка представляли собой увеличение скорости работы компьютеров. Нейронные сети конкурировали с векторными машинами. Нейронная сеть была медленнее, чем поддержка векторной машины, но они получили лучшие результаты и продолжали развиваться по мере добавления дополнительной учебной информации.
В 2000 году была выявлена проблема под названием исчезающий градиент. Задания, извлеченные в нижних слоях, не передавались в верхние слои однако, это произошло только в тех, с градиентом основе методов обучения. Источник проблемы был в некоторых функциях активации, которые уменьшили его ввод, влияющим на диапазон выходных данных, генерируя большие области ввода, сопоставленные в очень малом диапазоне, вызывая падающий градиент. Решения, реализы для решения проблемы, были слой за слоем перед тренировкой и развитие долгосрочной и кратковременной памяти[28].
В 2009 году фей-Фэй ли выпустила на с[29]вободу изображения с более чем 14 000 000 изображениями, сфокусирована на «обучении» нейронных сетей, указывая на то, как большие данные повлияют на работу машинного обучения.
Скорость работы графических процессоров, вплоть до 2011 года, продолжала увеличиваться, позволяя составу конволюционных нейронных сетей без необходимости предварительного тренировки слоя за слоем. Таким образом, стало печально, что глубинное обучение выгодно и с точки зрения эффективности и скорости.
В настоящее время обработка больших данных и прогрессирование искусственного интеллекта зависят от глубокого обучения, которые могут разрабатывать Интеллектуальные системы и способствовать созданию полностью автономного искусственного интеллекта, который создаст влияние на Все общество.
ГИБКИЕ НЕЙРОННЫЕ СЕТИ И ИХ ПРИЛОЖЕНИЯ
Несмотря на существование нескольких классических техник, структуры глубокого обучения и ее основной единицы, нейрон является общим и очень гибким. Сделав сравнение с нейронами человека, который обеспечивает синапсы мы можем определить некоторые корреляции между ними.
Рисунок 6: корреляция между нейрона человека и искусственной нейронной сетью
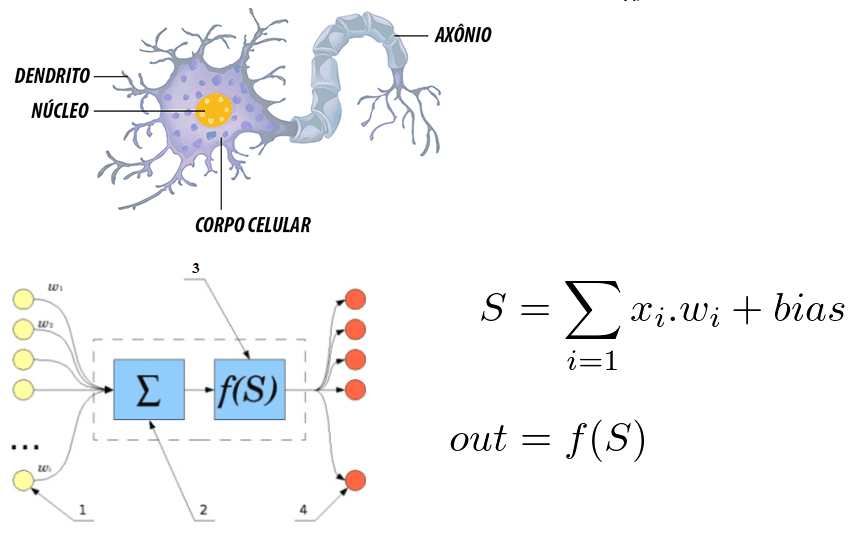
Отмечается, что нейрона формируется дендриты, которые являются точками входа, ядро, которое представляет в искусственных нейронных сетей обработки ядра и точка выхода, что представлено аксон. В обеих системах информация поступает, обрабатывается и изменяется.
Рассматривая его как математическое уравнение, нейрон отражает сумму входных данных, умноженную на вес, и это значение проходит через функцию активации. Эта сумма была выполнена Маккалок и Питтса в 1943[30]
В связи с пресловутый интерес к глубокому обучению в настоящее время, Сант[31]ана считает, что это связано с двумя факторами, которые являются объем имеющейся информации и ограничение старых методов, кроме текущей вычислительной мощности для подготовки сетей Комплекс. Гибкость соединения нескольких нейронов в более сложной сети является дифференциалом ГЛУБОКИХ учебных структур. Конволюционных нейронная сеть широко используется для распознавания лиц, обнаружения изображений и извлечения назначения.
Обычная нейронная сеть состоит из нескольких слоёв, называемых слоями. В зависимости от вопроса, который должен быть решен количество слоев может варьироваться, будучи в состоянии иметь до сотни слоев, являясь факторами, которые влияют на количество сложность проблемы, времени и вычислительной мощности
Есть несколько различных структур с бесчисленными целями, и их функционирование также зависит от структуры, и все они основаны на нейронных сетях.
Рисунок 7: примеры нейронных сетей
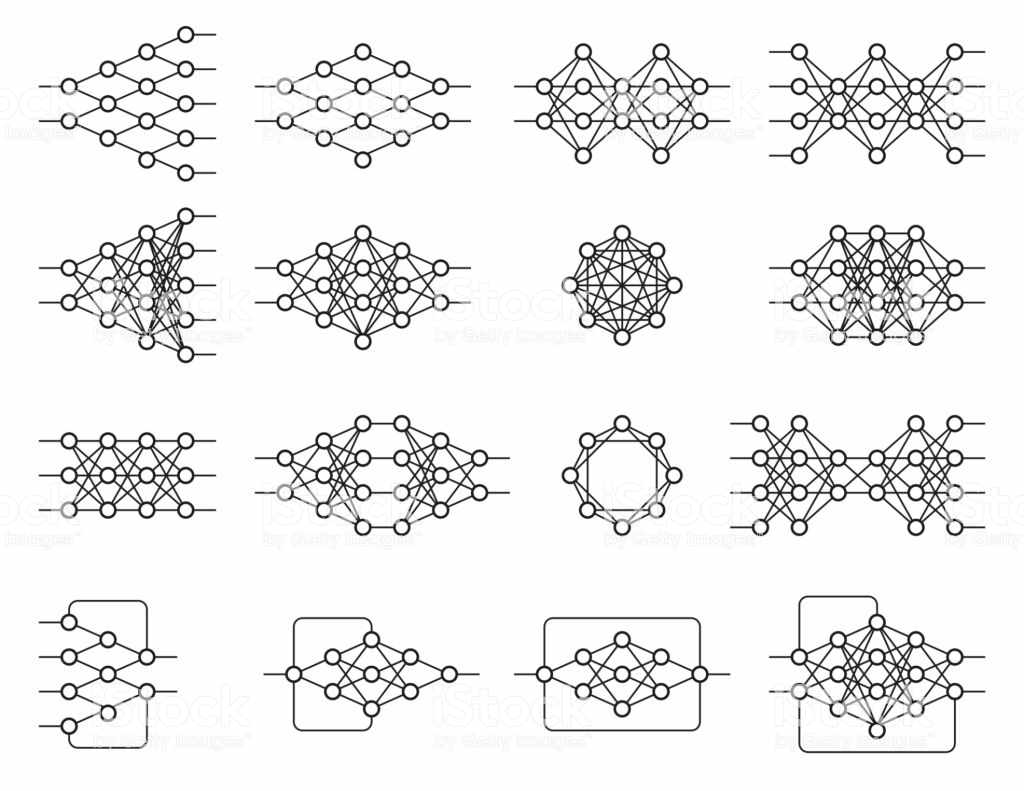
Эта архитектурная гибкость позволяет глубже научиться решать различные вопросы. Глубокое обучение является общей объективной техникой, но самые передовые области были: компьютерное зрение, распознавание речи, обработка естественного языка, системы рекомендаций.
Вычислительное зрение включает распознавание объектов, семантическую сегментирование, особенно автономные автомобили. Можно утверждать, что вычислительное зрение является частью искусственного интеллекта и определяется как набор знаний, который направлен на искусственное моделирование человеческого видения с целью имитации его функций, посредством разработки программного и аппаратного обеспечения Дополнительны[32]е.
Среди применений вычислительного видения – военное использование, рынок сбыта, безопасность, общественные услуги и производственный процесс. Автономные транспортные средства представляют собой будущее безопасного движения, но он все еще находится в стадии тестирования, так как он включает в себя несколько технологий, применяемых к функции. Вычислительное зрение в этих автомобилях, так как позволяет распознавание пути и препятствий, улучшая маршруты.
В контексте безопасности все чаще выделяются системы распознавания лиц, учитывая уровень безопасности в общественных и частных местах, также внедрил в мобильных устройствах. Аналогичным образом они могут служить ключом к доступу к финансовым операциям, в то время как в социальных сетях, он обнаруживает присутствие пользователя или его друзей в фотографиях.
В отношении рынка сбыта, исследования, разработанного Image разведки указал, что 3 000 000 000 изображения распределяются ежедневно социальных сетей и 80% содержат указания, которые относятся к конкретным компаниям, но без текстовых ссылок. Специализированные маркетинговые компании предлагают услуги мониторинга и управления в режиме реального времени. С технологией компьютерного зрения точность идентификации изображений достигает 99%.
В государственных услугах его использование покрывает безопасность сайта, отслеживая камеры, трафик транспортного средства через стереоскопические изображения, которые делают систему видения эффективной.
В производственном процессе компании из разных отраслей используют вычислительное зрение в качестве инструмента контроля качества. В любой отрасли, самое современное программное обеспечение, связанное с постоянно растущей вычислительной мощностью оборудования, увеличивает использование вычислительных возможностей.
Системы мониторинга позволяют признать заранее установленные стандарты и указывать на сбои, которые не могут быть идентифицированы при взгляде на работника на производственной линии. В этом же контексте, применительно к контролю складских запасов, используется проект автоматизации замещения. Инвентаризация и контроль продаж в режиме реального времени позволяют технологии контролировать деятельность данной компании, увеличивая тем самым свою прибыль. Есть и другие приложения в области медицины, образования и электронной коммерции.
Выводы
Настоящее исследование изыскивали уточнить что глубокое учить и указать вне свои применения в настоящем мире. Методы глубокого обучения продолжают прогрессировать, в частности, с использованием нескольких слоев. Тем не менее, есть еще ограничения в использовании глубоких нейронных сетей, учитывая, что они являются лишь одним из способов узнать несколько изменений, которые будут реализованы в входном векторе. Изменения, предоставляемые целым рядом параметров, которые обновляются в период обучения.
Нельзя отрицать, что искусственный интеллект является более близкой реальностью, но ей не хватает долгий путь. Принятие глубокого обучения в различных областях знаний позволяет обществу, в целом, извлекать пользу из чудес современных технологий.
Что касается искусственного интеллекта, то проверяется, что эта технология, способная к обучению, хотя очень важна линейная и нелинная природа человека, которая представляет собой большой дифференциал и имеет важное значение для некоторых областей знаний, Это пока не может быть реализовано в глубоком обучении.
В любом случае, использование глубоких методов обучения позволит машинам для оказания помощи обществу в различных мероприятиях, как показано, расширение когнитивных способностей человека и еще большее развитие в этих областях знаний.
БИБЛИОГРАФИЧЕСКИЕ ССЫЛКИ
ALIGER. Saiba o que é visão computacional e como ela pode ser usada. 2018. Disponível em: https://www.aliger.com.br/blog/saiba-o-que-e-visao-computacional/
BITTENCOURT, Guilherme. Breve história da Inteligência Artificial. 2001
CARVALHO, André Ponce de L. Redes Neurais Artificiais. Disponível em: http://conteudo.icmc.usp.br/pessoas/andre/research/neural/
CHUNG, J; GULCEHE, C; CHO, K; BENGIO, Y. Gated feedback recurrent neural networks. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, volume 37 of ICML, pages 2067–2075. 2015
CULTURA ANALITICA. Entenda o que é deep learning e como funciona. Disponível em: https://culturaanalitica.com.br/deep-learning-oquee-como-funciona/cultura-analitica-redes-neurais-simples-profundas/
DENG, Jia et al. Imagenet: Um banco de dados de imagens hierárquicas em grande escala. In: 2009 Conferência IEEE sobre visão computacional e reconhecimento de padrões . Ieee,. p. 248-255. 2009
DETTMERS, Tim. Aprendizagem profunda em poucas palavras: Historia e Treinamento. Disponível em: https://devblogs.nvidia.com/deep-learning-nutshell-history-training/
FUKUSHIMA, Kunihiko. Neocognitron: Um modelo de rede neural auto-organizada para um mecanismo de reconhecimento de padrões não afetado pela mudança de posição. Cibernética biológica , v. 36, n. 4, p. 193-202, 1980.
GARTNER. Gartner diz que a AI Technologies estará em quase todos os novos produtos de software até 2020. Disponível em: https://www.gartner.com/en/newsroom/press-releases/2017-07-18-gartner-says-ai-technologies-will-be-in-almost-every-new-software-product-by-2020
GOODFELLOW, I; BENGIOo, Y; COURVILLE, A. Deep Learning. MIT Press. Disponível em: http://www.deeplearningbook.org
GRAVES, A. Sequence transduction with recurrent neural networks. arXiv preprint arXiv:1211.3711, 2012.
HOCHREITER, Sepp. O problema do gradiente de fuga durante a aprendizagem de redes neurais recorrentes e soluções de problemas. Revista Internacional de Incerteza, Fuzziness and Knowledge-Based Systems , v. 6, n. 02, p. 107-116, 1998.
HEBB, Donald O. The organization of behavior; a neuropsycholocigal theory. A Wiley Book in Clinical Psychology., p. 62-78, 1949.
HINTON, Geoffrey E; SALAKHUTDINOV, Ruslan R. Reduzindo a dimensionalidade dos dados com redes neurais. ciência , v. 313, n. 5786, p. 504-507, 2006.
HOCHREITER, Sepp; SCHMIDHUBER, Jürgen. Longa memória de curto prazo. Computação Neural, v. 9, n. 8, p. 1735-1780, 1997.
INTRODUCTION to artificial neural networks, Proceedings Electronic Technology Directions to the Year 2000, Adelaide, SA, Australia, 1995, pp. 36-62. Disponível em: https://ieeexplore.ieee.org/document/403491
KOROLEV, Dmitrii. Set of different neural nets. Neuron network. Deep learning. Cognitive technology concept. Vector illustration Disponível em: https://stock.adobe.com/br/images/set-of-different-neural-nets-neuron-network-deep-learning-cognitive-technology-concept-vector-illustration/145011568
LIU, C.; CAO, Y; LUO Y; CHEN, G; VOKKARANE, V, MA, Y; CHEN, S; HOU, P. A new Deep Learning-based food recognition system for dietary assessment on an edge computing service infrastructure. IEEE Transactions on Services Computing, PP(99):1–13. 2017
LORENA, Ana Carolina; DE CARVALHO, André CPLF. Uma introdução às support vector machines. Revista de Informática Teórica e Aplicada, v. 14, n. 2, p. 43-67, 2007.
MARVIN, Minsky; SEYMOUR, Papert. Perceptrons. 1969. Disponível em: http://134.208.26.59/math/AI/AI.pdf
MCCULLOCH, Warren S; PITTS, Walter. Um cálculo lógico das idéias imanentes na atividade nervosa. O boletim de biofísica matemática, v. 5, n. 4, p. 115-133, 1943.
NIELSEN, Michael. How the backpropagation algorithm works. 2018. Disponível em: http://neuralnetworksanddeeplearning.com/chap2.html
NIPS. 2009. Disponível em: http://media.nips.cc/Conferences/2009/NIPS-2009-Workshop-Book.pdf
PANG, Y; SUN, M; JIANG, X; LI, X.. Convolution in convolution for network in network. IEEE Transactions on Neural Networks and Learning Systems, PP(99):1–11. 2017
SANTANA, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponível em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
UDACITY. Conheça 8 aplicações de Deep Learning no mercado. Disponível em: https://br.udacity.com/blog/post/aplicacoes-deep-learning-mercado
YANG, S; LUO, P; LOY, C.C; TANG, X. From facial parts responses to face detection: A Deep Learning approach. In Proceedings of 2015 IEEE International Conference on Computer Vision (ICCV), pages 3676–3684. 2015
- Liu, C., Cao, Y., Luo, Y., Chen, G., Vokkarane, V., Ma, Y., Chen, S., and Hou, P. (2017). A new Deep Learning-based food recognition system for dietary assessment on an edge computing service infrastructure. IEEE Transactions on Services Computing, PP(99):1–13.
- Yang, S., Luo; P., Loy, C.-C; Tang, X. From facial parts responses to face detection: A Deep Learning approach. In Proceedings of 2015 IEEE International Conference on Computer Vision (ICCV), p. 3676
- Chung, J; Gulcehre, C; Cho, K; Bengio, Y. Gated feedback recurrent neural networks. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, volume 37 of ICML, p. 2069
- PANG, Y; Sun, M., Jiang, X., and Li, X. (2017). Convolution in convolution for network in network. IEEE Transactions on Neural Networks and Learning Systems, PP(99):5. 2017 ↑
- Goodfellow, I., Bengio, Y., and Courville, A. Deep Learning. MIT Press. http://www.deeplearningbook.org.
- GRAVES, A. Sequence transduction with recurrent neural networks. arXiv preprint arXiv:1211.3711, 2012.
- GARTNER. Gartner diz que a AI Technologies estará em quase todos os novos produtos de software até 2020. Disponível em: https://www.gartner.com/en/newsroom/press-releases/2017-07-18-gartner-says-ai-technologies-will-be-in-almost-every-new-software-product-by-2020
- MCCULLOCH, Warren S; PITTS, Walter. Um cálculo lógico das idéias imanentes na atividade nervosa. O boletim de biofísica matemática , v. 5, n. 4, p. 115-133, 1943.
- HEBB, Donald O. The organization of behavior; a neuropsycholocigal theory. A Wiley Book in Clinical Psychology., p. 62-78, 1949.
- BITTENCOURT, Guilherme. Breve história da Inteligência Artificial. 2001.p. 24
- Idbiem p. 25
- MARVIN, Minsky; SEYMOUR, Papert. Perceptrons. 1969. Disponível em: http://134.208.26.59/math/AI/AI.pdf
- Introduction to artificial neural networks," Proceedings Electronic Technology Directions to the Year 2000, Adelaide, SA, Australia, 1995, pp. 36-62. Disponível em: https://ieeexplore.ieee.org/document/403491
- BITTENCOURT, Guilherme op cit. p. 32
- NIELSEN, Michael. How the backpropagation algorithm works. 2018. Disponível em: http://neuralnetworksanddeeplearning.com/chap2.html
- HINTON, Geoffrey E; SALAKHUTDINOV, Ruslan R. Reduzindo a dimensionalidade dos dados com redes neurais. ciência , v. 313, n. 5786, p. 504-507, 2006.
- NIPS. 2009. Disponível em: http://media.nips.cc/Conferences/2009/NIPS-2009-Workshop-Book.pdf
- Santana, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponivel em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
- SANTANA, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponível em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
- idem
- UDACITY. Conheça 8 aplicações de Deep Learning no mercado. Disponível em: https://br.udacity.com/blog/post/aplicacoes-deep-learning-mercado
- Dettmers, Tim. Aprendizagem profunda em poucas palavras: Historia e Treinamento. Disponível em: https://devblogs.nvidia.com/deep-learning-nutshell-history-training/
- FUKUSHIMA, Kunihiko. Neocognitron: Um modelo de rede neural auto-organizada para um mecanismo de reconhecimento de padrões não afetado pela mudança de posição. Cibernética biológica , v. 36, n. 4, p. 193-202, 1980.
- LORENA, Ana Carolina; DE CARVALHO, André CPLF. Uma introdução às support vector machines. Revista de Informática Teórica e Aplicada, v. 14, n. 2, p. 43-67, 2007.
- HOCHREITER, Sepp; SCHMIDHUBER, Jürgen. Longa memória de curto prazo. Computação Neural, v. 9, n. 8, p. 1735-1780, 1997.
- HOCHREITER, Sepp. O problema do gradiente de fuga durante a aprendizagem de redes neurais recorrentes e soluções de problemas. Revista Internacional de Incerteza, Fuzziness and Knowledge-Based Systems , v. 6, n. 02, p. 107-116, 1998.
- DENG, Jia et al. Imagenet: Um banco de dados de imagens hierárquicas em grande escala. In: 2009 Conferência IEEE sobre visão computacional e reconhecimento de padrões . Ieee, 2009. p. 248-255.
- MCCULLOCH, Warren S.; PITTS, Walter. Um cálculo lógico das idéias imanentes na atividade nervosa. O boletim de biofísica matemática , v. 5, n. 4, p. 115-133, 1943.
- SANTANA, Marlesson. Deep Learning: do Conceito às Aplicações. 2018. Disponivel em: https://medium.com/data-hackers/deep-learning-do-conceito-%C3%A0s-aplica%C3%A7%C3%B5es-e8e91a7c7eaf
- ALIGER. Saiba o que é visão computacional e como ela pode ser usada. 2018. Disponível em: https://www.aliger.com.br/blog/saiba-o-que-e-visao-computacional/
[1] Bachelor of Business Administration.
Представлено: Май, 2019
Утверждено: Май, 2019