REVISIÓN BIBLIOMÉTRICA
TEDESCHI, Victor Hugo Pancera [1], TSUNODA, Denise Fukumi [2]
TEDESCHI, Victor Hugo Pancera. TSUNODA, Denise Fukumi. Base de datos sobre biodiversidad: un análisis temporal de la producción científica. Revista Científica Multidisciplinar Núcleo do Conhecimento. Año 05, Ed. 09, vol. 06, pág. 68-81. Septiembre 2020. ISSN: 2448-0959, Enlace de acceso: https://www.nucleodoconhecimento.com.br/biologia-es/produccion-cientifica
RESUMEN
La presente investigación trata sobre bases de datos de biodiversidad a través de un levantamiento bibliográfico en el portal de revistas Scopus, utilizando términos en inglés y limitadores en las palabras claves, buscando restringir la búsqueda a la base de datos. Los documentos fueron analizados mediante bibliometría, en Biblioshiny (un paquete R). Se recuperaron un total de 352 documentos publicados en el período de 1984 a 2020. Mediante el análisis se observó un aumento de publicaciones a partir del año 2006. Los investigadores de Estados Unidos (54) presentaron la mayor cantidad de publicaciones, mientras que Brasil ( 11) está en sexta posición. Los resultados encontrados en esta investigación apuntan a una tendencia en los trabajos sobre el tema, proporcionando así una dirección para futuras investigaciones.
Palabras clave: Base de datos taxonómica, Informática de la biodiversidad, Conjunto de datos, Bibliometría.
1. INTRODUCCIÓN
La diversidad biológica en el planeta es muy alta y algunas estimaciones sitúan los valores en millones. Brasil, según estimaciones conservadoras, alberga el 13% de la biota del mundo. Esta estimación se debe a que Brasil tiene el sistema fluvial más grande del mundo, así como cinco biomas, lo que le valió al país el título de “país mega diverso” y contempla aproximadamente 165.000 especies conocidas, y cada día se descubren más especies.
Cada parte descubierta de una especie genera datos de forma continua y agregada sobre sus características (morfología, nomenclatura, filogenia, etc.), hábitos (alimentación, comportamiento, etc.), distribución geográfica (avistamientos, registros de colecta, etc.), genética (filogenética, secuenciación del ADN, etc.) entre otros.
Toda esta información necesita ser almacenada para facilitar su acceso y compartición a nivel mundial, justificando la necesidad del desarrollo y mantenimiento de bases de datos que realicen el correcto almacenamiento de esta información así como sistemas de recuperación específicos para el área. Con base en este pensamiento, el objetivo del presente trabajo es explorar, a través de un análisis bibliométrico, la producción sobre el tema depositada en la base de referencia Scopus que indexa títulos académicos arbitrados, títulos de acceso abierto, actas de congresos y publicaciones comerciales, entre otros.
2. FUNDAMENTACIÓN TEÓRICA
La base de datos se puede definir como una colección de datos lógicamente coherentes que tiene un significado, cuya interpretación se da de acuerdo con la aplicación, esta colección de datos representa de manera abstracta una parte del mundo real.
La información biológica se puede dividir en tres dimensiones, molecular, organismo y ecosistema (WILSON, 2005), según su aplicación esta información se ordena en tres tipos estructurales de bases, las cuales son bases taxonómicas (organismos), las cuales se enfocan en la presentación de los información morfológica de las especies, bases de la Informática para la Biodiversidad (ecosistema), que tiene un carácter transdisciplinario de información, con el fin de brindar información ecológica y distribución geográfica, y de la Bioinformática (molecular), que a su vez tiene como objetivo el almacenamiento y distribución de datos moleculares, genes y proteínas.
La información que alimenta estas bases proviene de los procesos de digitalización de las colecciones de los museos, informes de colección, listas de alistamiento, extraídas de documentos publicados, secuenciación de materiales, etc. Los resultados de este escaneo se pueden almacenar o compartir en una variedad de formatos, como documentos de texto, hojas de cálculo, páginas web, bases de datos relacionadas, mapas o GIS (Sistema de Información Geográfica), imágenes, etc. (FRAZIER; PARED; GRANT, 2008)
La digitalización de estos materiales es de vital importancia para la preservación y el intercambio de información sobre especies, pero este enfoque trae nuevos desafíos, como la confiabilidad de los datos digitalizados, a partir de este punto, Ruas (2017) destaca la importancia de los metadatos, que son información que describen la información contenida en la base de datos, en la curación del contenido generado por los procesos de digitalización, la metainformación garantiza la fidelidad y autenticidad de la información presentada, así como la contextualización y que la información fue capturada.
3. CURSO METODOLÓGICO
La elección de los términos a utilizar en esta investigación se realizó experimentando con diferentes conjuntos de palabras y operadores booleanos, basados en Scopus. El flujo de investigación (desde el nivel general al específico) y el número de documentos recuperados en cada experimento se muestra en la tabla 1.
Tabla 1 – Conjuntos de palabras y operadores booleanos utilizados en la base de datos Scopus y número de documentos recuperados
| Palabras y operadores | Documentos recuperados |
| ALL ( biodiversity AND database ) | 91.714 |
| ALL ( taxonomy AND database ) | 113.470 |
| ALL ( biodiversity OR taxonomy AND database OR dataset ) | 226.573 |
| ALL ( “biodiversity database” ) | 1.487 |
| ALL ( “biodiversity database” OR “taxonomy database” ) | 2.158 |
| ALL ( “biodiversity database” OR “taxonomy database” ) AND ( LIMIT-TO ( EXACTKEYWORD , “Biodiversity” ) OR LIMIT-TO ( EXACTKEYWORD , “Taxonomy” ) OR LIMIT-TO ( EXACTKEYWORD , “Databases, Genetic” ) OR LIMIT-TO ( EXACTKEYWORD , “Factual Database” ) OR LIMIT-TO ( EXACTKEYWORD , “Data Set” ) OR LIMIT-TO ( EXACTKEYWORD , “Protein Database” ) OR LIMIT-TO ( EXACTKEYWORD , “Databases, Protein” ) OR LIMIT-TO ( EXACTKEYWORD , “Biodiversity Informatics” ) OR LIMIT-TO ( EXACTKEYWORD , “Data Quality” ) ) AND ( EXCLUDE ( SUBJAREA , “IMMU” ) OR EXCLUDE ( SUBJAREA , “MEDI” ) OR EXCLUDE ( SUBJAREA , “NEUR” ) OR EXCLUDE ( SUBJAREA , “PHYS” ) OR EXCLUDE ( SUBJAREA , “PHAR” ) OR EXCLUDE ( SUBJAREA , “ARTS” ) OR EXCLUDE ( SUBJAREA , “VETE” ) OR EXCLUDE ( SUBJAREA , “HEAL” ) OR EXCLUDE ( SUBJAREA , “NURS” ) ) | 723 |
Fuente: Elaborado por los autores (2020).
A partir de los resultados encontrados, se leyeron los primeros 100 documentos, con el fin de observar si los resultados estaban alineados con la temática abordada en la presente investigación, realizando así ajustes en los términos con el fin de afinar los resultados. Como puede verse en la Tabla 1, en algunas combinaciones de términos el número de documentos recuperados osciló entre 700 y más de 200.000 documentos. Este paso fue necesario porque los investigadores de las ciencias biológicas utilizan términos como biodiversity y taxonomic en diferentes contextos.
La estrategia de búsqueda en la base de datos Scopus (Elsevier) fue la búsqueda de los términos en inglés “biodiversity database” y “taxonomic database”, en todos los campos se utilizó un limitador en las palabras clave, seleccionando aquellas que tienen relación con los datos, las palabras seleccionados son “Database“, “Data set“, “Data Base“, “database, factual“, “factual database“, “Database Systems“, “data quality” y “data management“, utilizando los resultados obtenidos hasta la fecha de la búsqueda del 28 de junio de 2020. Los parámetros de consulta con códigos de campo y operadores dieron como resultado:

El análisis métrico de frecuencia de palabras (Título, resumen, palabras clave de los autores, palabras clave extendidas), frecuencia de producción de documentos (países, fuentes, autores) y evolución en el tiempo (Producción por año, uso de palabras clave) se realizó mediante Biblioshiny (interfaz gráfica del paquete Bibliometrix, producido en lenguaje R) y el editor de hojas de cálculo de Microsoft Excel. Los datos se exportaron directamente de la base de datos Scopus en formato CSV, compatible con la biblioteca Biblioshiny para el software R v.3.6.3 y Microsoft Excel 2016.
4. PRESENTACIÓN Y DISCUSIÓN DE RESULTADOS
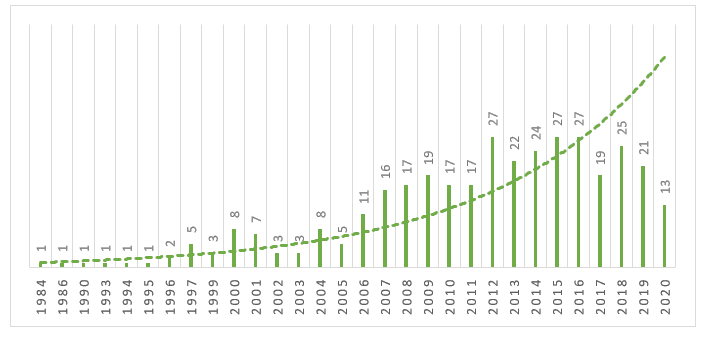
El análisis comprende los 352 documentos recuperados en la búsqueda de la base de datos Scopus el 28 de junio de 2020, de los cuales 272 son artículos publicados, 30 actas de congresos y un capítulo de libro. La primera publicación encontrada hace referencia al año 1984. Los 352 documentos recuperados fueron escritos por 1.978 autores. Se identificaron 2.068 palabras clave extendidas (palabras generadas automáticamente por la base de datos) y 1.033 palabras clave de los autores.
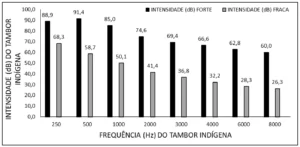
Como se muestra en el Gráfico 1, se observa que en el intervalo de tiempo entre 1984 y 1996 no hubo una producción significativa sobre el tema, luego de este período se observa un incremento en el número de producciones sobre el tema. Se observa que en el 2017 hubo una oscilación importante, donde hubo una caída en la producción, y una reanudación al año siguiente. Hasta el momento de esta investigación 2020 ya presenta 13 artículos publicados.
Gráfico 1 – Evolución de la producción científica en la base de datos Scopus de 1984 a 2020
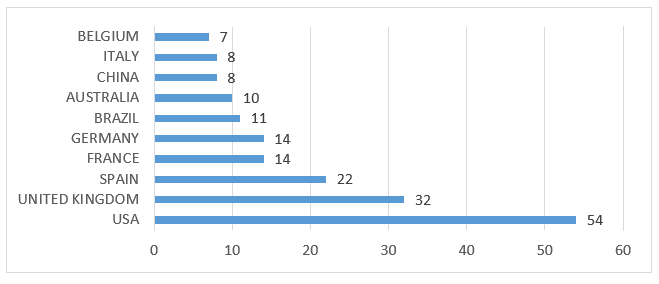
La distribución de documentos por países muestra a Estados Unidos de América (54) con el mayor número de publicaciones en esta área, seguido por Reino Unido (32), que muestra un predominio de documentos en idioma inglés. Este resultado puede haber sido influenciado por el uso de términos de búsqueda en el idioma inglés. Por otro lado, varias revistas en distintos idiomas utilizan el abstract como uno de los elementos obligatorios. Brasil (11) aparece en el sexto lugar en número de publicaciones, como se muestra en el Gráfico 2.
Gráfico 2 – Contribución de la producción científica en el mundo
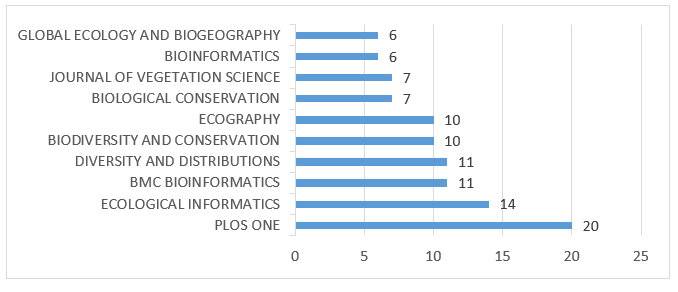
Entre los 352 documentos recuperados en la consulta, PLOS ONE presentó el mayor número de artículos publicados, con un total de 20, seguido de Ecological Informatics con 14. El Gráfico 3 presenta las 10 fuentes con mayor número de publicaciones.
Gráfico 3 – Fuentes con mayor número de producciones
Los 10 investigadores más productivos se muestran en la Tabla 2 y los 10 más citados en la Tabla 3. El autor más productivo (10) y el más citado (241) es el Dr. Jorge M. Lobo, Profesor Investigador del Departamento de Biogeography and Global Change do Museo Nacional de Ciencias Naturales, en Madrid, España. El artículo más referenciado del autor es “Use of niche models in invasive species risk assessments” en coautoría con los investigadores A. Jiménez-Valverde, A. T. Peterson, J. Soberón, J. M. Overton y P. Argon, que también es el tercer artículo más citado (384), presentado en la tabla 4. Este trabajo analiza el uso de datos de ubicación de especies para la elaboración de modelos predictivos del riesgo de asentamiento de especies invasoras, comunes en grandes conjuntos de datos de biodiversidad, como datos de georreferenciación e identificaciones erróneas de especies.
Tabla 2 – Autores más productivos
| Autores | Artículos |
| LOBO JM | 10 |
| HORTAL J | 9 |
| PAGE RDM | 7 |
| SOBERóN J | 6 |
| BOOTH TH | 5 |
| COSTELLO MJ | 5 |
| KREFT H | 5 |
| ARIñO AH | 4 |
| GURALNICK R | 4 |
Fuente: Elaborado por los autores (2020).
Tabla 3 – Autores más citados
| Autores | Cotizaciones |
| LOBO J M | 241 |
| PETERSON A T | 223 |
| HORTAL J | 217 |
| GUISAN A | 132 |
| COSTELLO M J | 117 |
| GRAHAM C H | 114 |
| SOBERÃ N J | 109 |
| FERRIER S | 108 |
| JIMÃ NEZ VALVERDE A | 108 |
Fuente: Elaborado por los autores (2020).
Los cinco artículos más referenciados se enumeran en la Tabla 4. El más citado es el artículo titulado “SequenceMatrix: concatenation software for the fast assembly of multi-gene datasets with character set and codon information”, producido por Vaidya, G., Lohman, D. J. y Meier, R. publicado en 2011. En este trabajo, los autores presentan el software SequenceMatrix utilizado en el análisis y asociación de múltiples genes de diferentes datasets, señalando la facilidad de uso como punto fuerte y presentando sus principales funcionalidades. El software habilita funciones de detección y corrección de errores contenidos en los datasets.
Andelman y Fagan (2000) evalúan si el uso de especies denominadas “bandera” o “paraguas” son eficientes en el uso como sustitutos en la conservación, ya que en lugar de enfocarse en la conservación de varias áreas, el foco está en la conservación de estas áreas pocas especies, lo que en consecuencia ayuda en la conversación de áreas enteras. Para probar su hipótesis, los autores utilizaron tres bases de datos con diferentes dimensiones de cobertura.
Jayasiri et al. (2015) trata en su artículo de la creación de una base de datos vía web, enfocada en la diversidad de hongos, con el fin de mejorar la precisión de los nombres científicos, enfocándose en la taxonomía. La base cuenta con 76 curadores especializados en los diferentes grupos, lo que garantiza la confiabilidad de los datos.
Lobo, Jiménez-Valverde y Hortal (2010) tratan los datos de ausencia de especies en determinadas regiones contenidos en las bases de datos, en la generación de modelos de distribución. Llevaron a cabo un estudio de caso de una especie de escarabajo que tiene una distribución conocida, con el fin de demostrar los posibles errores en el uso de estos datos de ausencia y su importancia en el modelado de mapas de distribución.
Tabla 4 – los cinco artículos más citados
| Artículos | Citas totales |
| VAIDYA, G.; LOHMAN, D. J.; MEIER, R. SequenceMatrix: Concatenation software for the fast assembly of multi-gene datasets with character set and codon information. Cladistics, v. 27, n. 2, p. 171–180, 2011. | 847 |
| ANDELMAN, S. J.; FAGAN, W. F. Umbrellas and flagships: Efficient conservation surrogates or expensive mistakes? Proceedings of the National Academy of Sciences of the United States of America, v. 97, n. 11, p. 5954–5959, 2000. | 447 |
| JIMÉNEZ-VALVERDE, A. et al. Use of niche models in invasive species risk assessments. Biological Invasions, v. 13, n. 12, p. 2785–2797, 2011. | 384 |
| JAYASIRI, S. C. et al. The Faces of Fungi database: fungal names linked with morphology, phylogeny and human impacts. Fungal Diversity, v. 74, n. 1, p. 3–18, 2015. | 355 |
| LOBO, J. M.; JIMÉNEZ-VALVERDE, A.; HORTAL, J. The uncertain nature of absences and their importance in species distribution modelling. Ecography, v. 33, n. 1, p. 103–114, 2010. | 325 |
Fuente: Elaborado por los autores (2020).
Los cinco artículos más citados en los documentos se muestran en la tabla 5. El artículo más citado en los documentos es “Interoperability of biodiversity databases: biodiversity information on every desktop”, elaborado por los autores Edwards, Lane y Nielsen y publicado en el año 2000, en el artículo y tratado sobre el GBIF, que fue creado para facilitar la digitalización de datos sobre biodiversidad, y hacerlos de libre acceso. En el artículo se presenta sobre GBIF y las perspectivas futuras de los datos sobre biodiversidad.
Hortal, Lobo y Jiménez-Valverde (2007) presentan un estudio de caso sobre las limitaciones encontradas en las bases de datos de biodiversidad, centrándose en una base de diversidad de semillas y plantas. En su trabajo Soberón y Peterson (2004), discuten el potencial de la Informática de la Biodiversidad, en su discusión comentan sobre la aplicación de métodos en la gestión de la biodiversidad, y no solo para estudios fundamentales e intercambio de información. Soberón et al. (2006), en su artículo, demuestran el uso de datos sobre biodiversidad presentes en las bases para estimar la riqueza y en diferentes resoluciones de distribución geográfica. Bisby (2000) se ocupa de la aparición de grandes sistemas de información biológica global en su investigación.
Tabla 5 – Los 5 documentos más citados en las referencias en el período
| Documentos citados en las referencias | Número de citas |
| EDWARDS, James L.; LANE, Meredith A.; NIELSEN, Ebbe S. Interoperability of biodiversity databases: biodiversity information on every desktop. Science, v. 289, n. 5488, p. 2312-2314, 2000. | 49 |
| HORTAL, Joaquín; LOBO, Jorge M.; JIMÉNEZ‐VALVERDE, ALBERTO. Limitations of biodiversity databases: case study on seed‐plant diversity in Tenerife, Canary Islands. Conservation Biology, v. 21, n. 3, p. 853-863, 2007. | 37 |
| SOBERÓN, Jorge; PETERSON, Townsend. Biodiversity informatics: managing and applying primary biodiversity data. Philosophical Transactions of the Royal Society of London. Series B: Biological Sciences, v. 359, n. 1444, p. 689-698, 2004. | 34 |
| SOBERÓN, Jorge et al. Assessing completeness of biodiversity databases at different spatial scales. Ecography, v. 30, n. 1, p. 152-160, 2007. | 25 |
| BISBY, Frank A. The quiet revolution: biodiversity informatics and the internet. Science, v. 289, n. 5488, p. 2309-2312, 2000. | 23 |
Fuente: Elaborado por los autores (2020).
Las palabras clave más utilizadas por la Database de autores (49), seguidas de biodiversity (32), taxonomy (26), biodiversity informatics (19) y data quality (19), estas frecuencias de palabras probablemente se vieron afectadas por la metodología de selección de documentos realizada en esta investigación. La Figura 1 muestra las 50 palabras clave con mayor ocurrencia de las 1033.
Figura 1 – Las 50 palabras clave más frecuentes del autor

En cuanto a las palabras clave extendidas, la palabra más utilizada es Biodiversity (236), seguida de database (125), Taxonomy (88), dataset (66) y classification (62). Y en los resúmenes las palabras más frecuentes data (1.221), species (856), biodiversity(488), database (315), databases (268). Las palabras más frecuentes en los títulos de los documentos son data (113), biodiversity (100), species (68), database (57), databases (44).
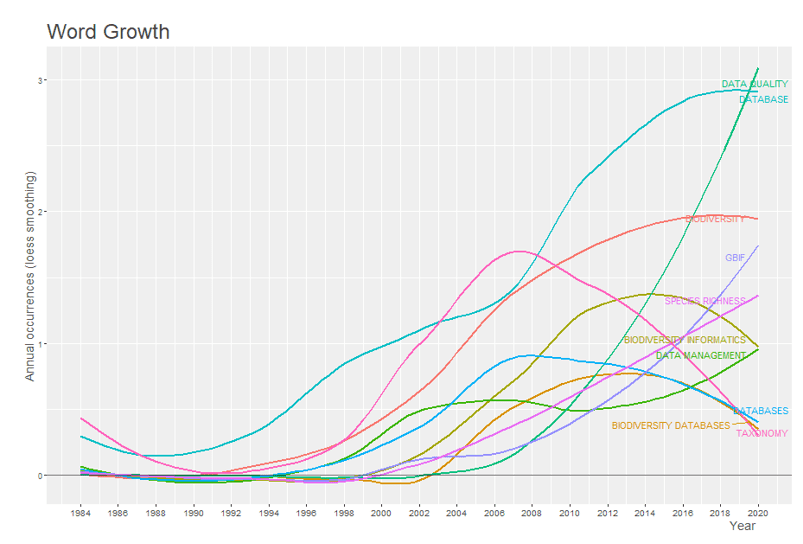
As 10 palavras-chave dos autores de maiores frequências estão representadas de acordo com o número de ocorrências acumuladas ao longo do tempo no gráfico 4. No gráfico é possível observar ainda o crescimento exponencial da palavra data quality, o que pode indicar um aumento no interesse por estudos visando avaliar as informações contidas nas bases de dados existentes, em conjunto a essa palavra e observado o crescimento da palavra GBIF, que corresponde ao Global Biodiversity Information Facility, que é uma rede internacional para o compartilhamento de dados sobre todos os tipos de vida en la tierra. Las palabras database, biodiversity database, bdatabases y biodiversity informatics han mostrado una disminución en su uso en los últimos años.
Gráfico 4 – Dinámica de las palabras clave del autor a lo largo del tiempo
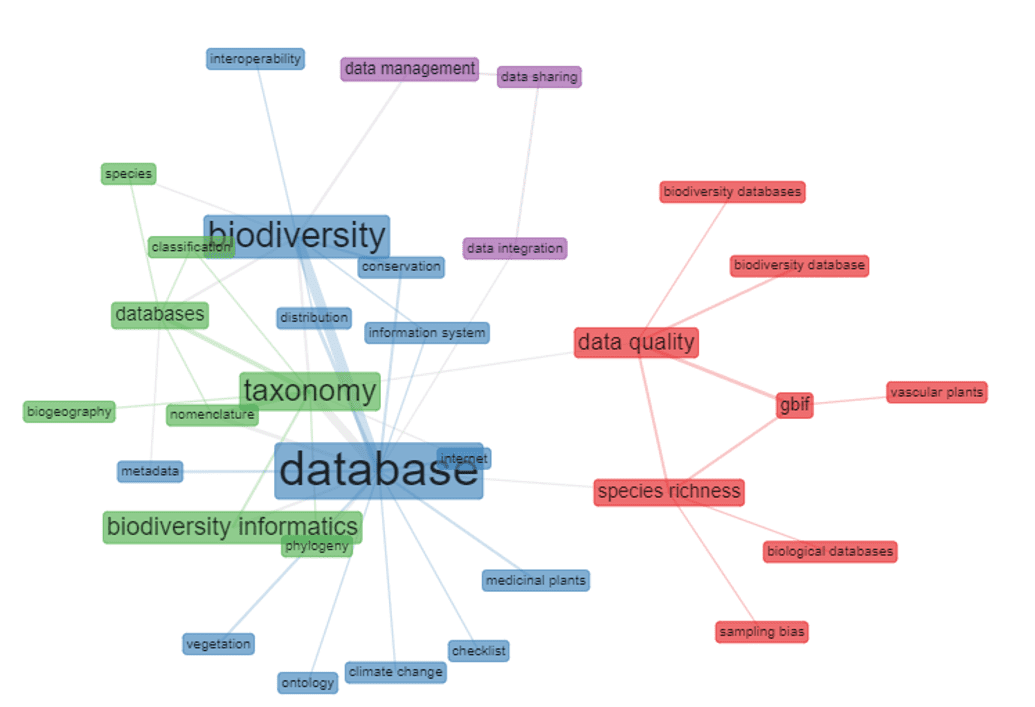
En el análisis de co-ocurrencia de las palabras clave, se pueden percibir algunas relaciones: a) database – biodiversity – metadata, internet, information system, distribution, conservation y checklist; b) taxonomy – biodiversity informatics y phylogeny – databases species, classification, nomenclature y biogeography; c) data quality – species richness – biodiversity databases, biodiversity database, GBIF y biological databases; d) data management, datashring y data integration. Vale la pena destacar las relaciones presentadas en el conjunto “c”, en el que se puede observar el enfoque en la calidad de los datos presentados en las bases, con foco en GBIF. La separación entre el conjunto “a” y “b”, se presenta de manera interesante, visibilizando la diferencia en el enfoque de la investigación, donde el conjunto “a” se centró en la distribución, conservación y diversidad de especies, mientras que el el conjunto “b” se ocupa más de la nomenclatura y clasificación de las especies. La Figura 2 presenta las relaciones antes mencionadas.
Figura 2 – La co-ocurrencia de las palabras clave utilizadas por los autores
5. CONSIDERACIONES PARCIALES
El presente estudio presentó la evolución de las producciones científicas relacionadas con las bases de datos de biodiversidad y taxonomía que se encuentran en la base de datos Scopus. La consulta arrojó 352 documentos, distribuidos en el período de 1984 a 2020. Hubo un aumento de publicaciones a partir de 2006.
De acuerdo con la información obtenida a través de los análisis, fue posible visualizar el crecimiento de las producciones y los países que más produjeron sobre el tema, y permitió señalar las publicaciones más citadas referenciadas.
La identificación de las palabras clave más utilizadas posiblemente se vio afectada por la metodología aplicada en esta investigación, ya que fueron utilizadas en los términos de búsqueda aplicados en la base de datos Scopus. Sin embargo, es posible observar un crecimiento en el interés por los documentos recuperados relacionado con la calidad de los datos encontrados en estas bases.
Este artículo presenta el acercamiento exploratorio inicial a las bases de datos relacionadas con la biodiversidad. Con base en los resultados, en el futuro se explorarán mejor los problemas relacionados con la calidad de los datos presentes en las bases de datos más utilizadas, como la base de datos GBIF. Otro punto a ser abordado en futuras investigaciones es la forma de representación de las especies brasileñas en estas bases de datos, y la posibilidad de recuperación de esa información por parte de los interesados.
La continuidad de la investigación está en línea con los intereses propuestos en la disertación del autor, en la que propone el desarrollo de una base de datos/portal de acceso abierto, que facilite la difusión de datos sobre la diversidad de la fauna brasileña (animales), valorando datos de calidad en constante actualización y confianza, para atender las necesidades de los profesionales e investigadores en las áreas biológicas.
REFERENCIAS
ANDELMAN, S. J.; FAGAN, W. F. Umbrellas and flagships: Efficient conservation surrogates or expensive mistakes? Proceedings of the National Academy of Sciences of the United States of America, v. 97, n. 11, p. 5954–5959, 2000.
BISBY, Frank A. The quiet revolution: biodiversity informatics and the internet. Science, v. 289, n. 5488, p. 2309-2312, 2000.
EDWARDS, James L.; LANE, Meredith A.; NIELSEN, Ebbe S. Interoperability of biodiversity databases: biodiversity information on every desktop. Science, v. 289, n. 5488, p. 2312-2314, 2000.
FRAZIER, C.K., WALL, J.; GRANT, S.. Initiating a Natural History CollectionDigitisation Project, version 1.0. Copenhagen: Global Biodiversity Information Facility.75 pp. 2008.
HORTAL, Joaquín; LOBO, Jorge M.; JIMÉNEZ‐VALVERDE, ALBERTO. Limitations of biodiversity databases: case study on seed‐plant diversity in Tenerife, Canary Islands. Conservation Biology, v. 21, n. 3, p. 853-863, 2007.
JAYASIRI, S. C. et al. The Faces of Fungi database: fungal names linked with morphology, phylogeny and human impacts. Fungal Diversity, v. 74, n. 1, p. 3–18, 2015.
JIMÉNEZ-VALVERDE, Alberto et al. Use of niche models in invasive species risk assessments. Biological invasions, v. 13, n. 12, p. 2785-2797, 2011.
LOBO, J. M.; JIMÉNEZ-VALVERDE, A.; HORTAL, J. The uncertain nature of absences and their importance in species distribution modelling. Ecography, v. 33, n. 1, p. 103–114, 2010.
RUA, J. DIGITALIZAÇÃO, PRESERVAÇÃO E ACESSO: contributos para o projeto Museu Digital da U.PORTO. Páginas a&b. S.3, nº especial (2017) 199-229 | DOI 10.21747/21836671/pag2017a13
SOBERÓN, Jorge et al. Assessing completeness of biodiversity databases at different spatial scales. Ecography, v. 30, n. 1, p. 152-160, 2007.
SOBERÓN, Jorge; PETERSON, Townsend. Biodiversity informatics: managing and applying primary biodiversity data. Philosophical Transactions of the Royal Society of London. Series B: Biological Sciences, v. 359, n. 1444, p. 689-698, 2004.
VAIDYA, G.; LOHMAN, D. J.; MEIER, R. SequenceMatrix: Concatenation software for the fast assembly of multi-gene datasets with character set and codon information. Cladistics, v. 27, n. 2, p. 171–180, 2011.
WILSON, Edward O. Systematics and the future of biology. Proceedings of the National Academy of Sciences, v. 102, n. suppl 1, p. 6520-6521, 2005.
[1] Graduado en Ciencias Biológicas, Pontifícia Universidade Católica do Paraná (PUC-PR), Paraná, Brasil. Graduado en Electrónica Industrial, Faculdade de Tecnologia de Curitiba (FATEC) Curitiba, Paraná, Brasil. Estudiante de maestría en Gestión de la Información, Universidade Federal do Paraná (UFPR), Curitiba, Paraná, Brasil.
[2] Doctor en Ingeniería Eléctrica e Informática, Universidade Tecnológica Federal do Paraná (UTFPR), Curitiba, Paraná, Brasil.
Enviado: Septiembre de 2020.
Aprobado: Septiembre de 2020.