REVISIONE BIBLIOMETRICA
TEDESCHI, Victor Hugo Pancera [1], TSUNODA, Denise Fukumi [2]
TEDESCHI, Victor Hugo Pancera. TSUNODA, Denise Fukumi. Database sulla biodiversità: un’analisi temporale della produzione scientifica. Revista Científica Multidisciplinar Núcleo do Conhecimento. Anno 05, ed. 09, vol. 06, pag. 68-81. Settembre 2020. ISSN: 2448-0959, Link di accesso: https://www.nucleodoconhecimento.com.br/biologia-it/produzione-scientifica
RIEPILOGO
La presente ricerca si occupa dei database della biodiversità attraverso un’indagine bibliografica sul portale delle riviste Scopus, utilizzando termini in inglese e limiter nelle parole chiave, cercando di restringere la ricerca al database. I documenti sono stati analizzati utilizzando la bibliometria, in Biblioshiny (un pacchetto R). Sono stati recuperati in totale 352 documenti pubblicati nel periodo dal 1984 al 2020. Attraverso l’analisi è stato osservato un aumento delle pubblicazioni rispetto all’anno 2006. I ricercatori degli Stati Uniti (54) hanno presentato il maggior numero di pubblicazioni, mentre il Brasile ( 11) è in sesta posizione. I risultati trovati in questa ricerca indicano una tendenza nei lavori sull’argomento, fornendo così una direzione per la ricerca futura.
Parole chiave: Database tassonomico, Informatica della biodiversità, Dataset, Bibliometria.
1. INTRODUZIONE
La diversità biologica sul pianeta è molto alta e alcune stime mettono valori a milioni. Il Brasile, secondo stime prudenti, ospita il 13% del biota mondiale. Questa stima è dovuta al fatto che il Brasile ha il più grande sistema fluviale del mondo e cinque biomi, guadagnandosi il titolo di “mega paese diversificato” e contemplando circa 165.000 specie conosciute e ogni giorno vengono scoperte più specie.
Ogni parte scoperta di una specie genera dati in modo continuo e aggregante sulle sue caratteristiche (morfologia, nomenclatura, filogenesi, ecc.), abitudini (alimentazione, comportamento, ecc.), distribuzione geografica (avvistamenti, registri di raccolta, ecc.), genetica (filogenetica, sequenziamento del DNA, ecc.) tra gli altri.
Tutte queste informazioni devono essere conservate al fine di facilitarne l’accesso e la condivisione in tutto il mondo, giustificando la necessità dello sviluppo e della manutenzione di banche dati che eseguano la corretta conservazione di tali informazioni nonché di sistemi di recupero specifici per l’area. Sulla base di questa riflessione, l’obiettivo del presente lavoro è esplorare, attraverso un’analisi bibliometrica, la produzione sull’argomento depositata nella base di riferimento di Scopus che indicizza titoli accademici peer-reviewed, titoli ad accesso libero, atti di convegni e pubblicazioni commerciali, tra altri.
2. FONDAZIONE TEORICA
Il database può essere definito come una raccolta di dati logicamente coerenti che ha un significato, la cui interpretazione viene data in base all’applicazione, questa raccolta di dati rappresenta astrattamente una parte del mondo reale.
Le informazioni biologiche possono essere suddivise in tre dimensioni, molecolare, organismo ed ecosistema (WILSON, 2005), in base alla sua applicazione queste informazioni sono organizzate in tre tipi strutturali di basi, che sono basi tassonomiche (organismi), che si concentrano sulla presentazione del informazioni morfologiche della specie, basi dell’Informatica per la Biodiversità (ecosistema), che ha un carattere transdisciplinare delle informazioni, al fine di fornire informazioni ecologiche e distribuzione geografica, e della Bioinformatica (molecolare), che a sua volta è finalizzata allo stoccaggio e alla distribuzione di dati molecolari, geni e proteine.
Le informazioni che alimentano queste basi provengono dai processi di digitalizzazione delle collezioni museali, dai verbali di raccolta, dalle liste di arruolamento, estratte da documenti pubblicati, dal sequenziamento dei materiali, ecc. I risultati di questa scansione possono essere archiviati o condivisi in una varietà di formati come documenti di testo, fogli di calcolo, pagine Web, database correlati, mappe o GIS (Sistema d’Informazione Geografica), immagini, ecc. (FRAZIER; WALL; GRANT, 2008)
La digitalizzazione di questi materiali è di vitale importanza per la conservazione e la condivisione delle informazioni sulle specie, ma questo approccio porta nuove sfide, come l’affidabilità dei dati digitalizzati, a partire da questo punto, Ruas (2017) sottolinea l’importanza dei metadati, che sono informazioni che Descrivono le informazioni contenute nel database, nella cura dei contenuti generati dai processi di digitalizzazione, le meta-informazioni garantiscono la fedeltà e l’autenticità delle informazioni presentate, nonché la contestualizzazione e che le informazioni sono state acquisite.
3. CORSO METODOLOGICO
La scelta dei termini da utilizzare in questa ricerca è stata effettuata sperimentando diversi insiemi di parole e operatori booleani, basati su Scopus. Il flusso di ricerca (dal livello generale a quello specifico) e il numero di documenti recuperati in ogni esperimento è mostrato nella tabella 1.
Tabella 1 – Insiemi di parole e operatori booleani utilizzati nel database di Scopus e numero di documenti recuperati
| Parole e operatori | Documenti recuperati |
| ALL ( biodiversity AND database ) | 91.714 |
| ALL ( taxonomy AND database ) | 113.470 |
| ALL ( biodiversity OR taxonomy AND database OR dataset ) | 226.573 |
| ALL ( “biodiversity database” ) | 1.487 |
| ALL ( “biodiversity database” OR “taxonomy database” ) | 2.158 |
| ALL ( “biodiversity database” OR “taxonomy database” ) AND ( LIMIT-TO ( EXACTKEYWORD , “Biodiversity” ) OR LIMIT-TO ( EXACTKEYWORD , “Taxonomy” ) OR LIMIT-TO ( EXACTKEYWORD , “Databases, Genetic” ) OR LIMIT-TO ( EXACTKEYWORD , “Factual Database” ) OR LIMIT-TO ( EXACTKEYWORD , “Data Set” ) OR LIMIT-TO ( EXACTKEYWORD , “Protein Database” ) OR LIMIT-TO ( EXACTKEYWORD , “Databases, Protein” ) OR LIMIT-TO ( EXACTKEYWORD , “Biodiversity Informatics” ) OR LIMIT-TO ( EXACTKEYWORD , “Data Quality” ) ) AND ( EXCLUDE ( SUBJAREA , “IMMU” ) OR EXCLUDE ( SUBJAREA , “MEDI” ) OR EXCLUDE ( SUBJAREA , “NEUR” ) OR EXCLUDE ( SUBJAREA , “PHYS” ) OR EXCLUDE ( SUBJAREA , “PHAR” ) OR EXCLUDE ( SUBJAREA , “ARTS” ) OR EXCLUDE ( SUBJAREA , “VETE” ) OR EXCLUDE ( SUBJAREA , “HEAL” ) OR EXCLUDE ( SUBJAREA , “NURS” ) ) | 723 |
Fonte: A cura degli autori (2020).
Dai risultati trovati sono stati letti i primi 100 documenti, al fine di osservare se i risultati fossero allineati al tema affrontato nella presente ricerca, apportando quindi adeguamenti ai termini al fine di affinare i risultati. Come si può vedere nella Tabella 1, in alcune combinazioni di termini il numero di documenti recuperati variava da 700 a oltre 200.000 documenti. Questo passaggio è stato necessario perché termini come biodiversity e taxonomic sono utilizzati in contesti diversi dai ricercatori delle scienze biologiche.
La strategia di ricerca nel database Scopus (Elsevier) è stata la ricerca dei termini inglesi “biodiversity database” e “taxonomic database”, in tutti i campi è stato utilizzato un limiter nelle parole chiave, selezionando quelle relative ai dati, le parole selezionati sono “Database”, “Data set“, “Data Base“, “database, factual“, “factual database“, “Database Systems“, “data quality” e “data management“, utilizzando i risultati fino ad ora ottenuti dalla ricerca del 28 giugno 2020. I parametri di ricerca con codici di campo e operatori, hanno prodotto:

Analisi metrica della frequenza delle parole (titolo, repilogo, parole chiave degli autori, parole chiave estese), frequenza di produzione dei documenti (paesi, fonti, autori) ed evoluzione nel tempo (produzione per anno, uso delle parole chiave) è stato eseguito utilizzando Biblioshiny (interfaccia grafica del pacchetto Bibliometrix, prodotto in linguaggio R) e l’editor di fogli di calcolo Microsoft Excel. I dati sono stati esportati direttamente dal database Scopus in formato CSV, compatibile con la libreria Biblioshiny per il software R v.3.6.3 e Microsoft Excel 2016.
4. PRESENTAZIONE E DISCUSSIONE DEI RISULTATI
L’analisi comprende i 352 documenti recuperati dalla ricerca nel database Scopus del 28 giugno 2020, di cui 272 articoli pubblicati, 30 atti di convegni e un capitolo di libro. La prima pubblicazione trovata si riferisce all’anno 1984. I 352 documenti recuperati sono stati scritti da 1.978 autori. Sono state individuate 2.068 parole chiave estese (parole generate automaticamente dal database) e 1.033 parole chiave degli autori.
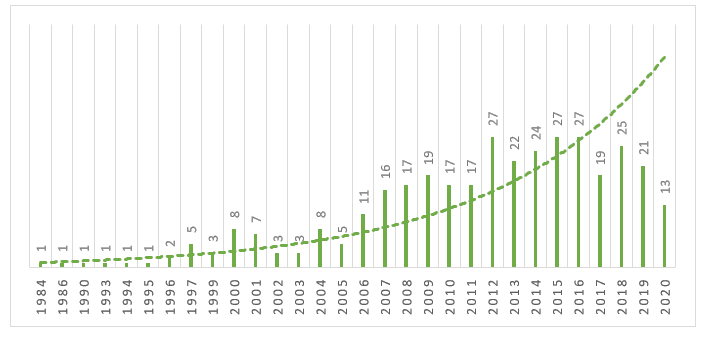
Come si evince dal Grafico 1, si osserva che nell’intervallo di tempo compreso tra il 1984 e il 1996 non vi era alcuna produzione significativa sull’argomento, trascorso tale periodo si osserva un aumento del numero di produzioni sull’argomento. Si osserva che nel 2017 si è verificata una significativa oscillazione, dove si è registrato un calo della produzione, e una ripresa nell’anno successivo. Fino al momento di questa ricerca 2020 presenta già 13 articoli pubblicati.
Grafico 1 – Evoluzione della produzione scientifica nel database Scopus dal 1984 al 2020
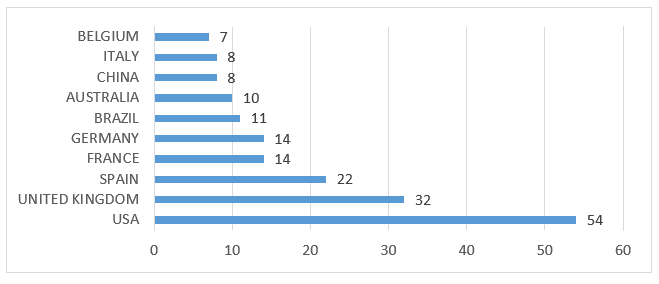
La distribuzione dei documenti per paese mostra gli Stati Uniti d’America (54) con il maggior numero di pubblicazioni in quest’area, seguiti dal Regno Unito (32), che mostra una predominanza di documenti in lingua inglese. Questo risultato potrebbe essere stato influenzato dall’uso di termini di ricerca in lingua inglese. D’altra parte, diverse riviste in diverse lingue utilizzano l’abstract come uno degli elementi obbligatori. Il Brasile (11) appare al sesto posto per numero di pubblicazioni, come mostrato nel Grafico 2.
Grafico 2 – Contributo della produzione scientifica nel mondo
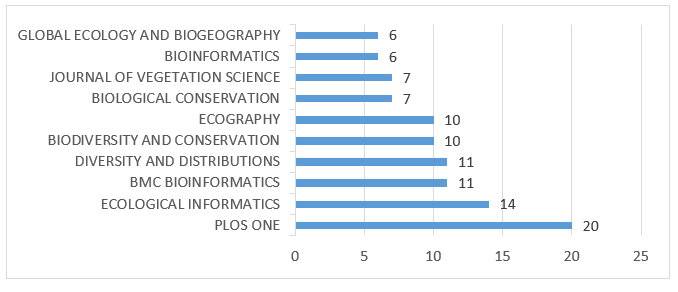
Tra i 352 documenti recuperati nella query, PLOS ONE ha presentato il maggior numero di articoli pubblicati, su un totale di 20, seguito da Ecological Informatics con 14. Il grafico 3 presenta le 10 fonti con il maggior numero di pubblicazioni.
Grafico 3 – Fonti con il maggior numero di produzioni
I 10 ricercatori più produttivi sono mostrati nella Tabella 2 e i 10 più citati nella Tabella 3. L’autore più produttivo (10) e il più citato (241) è il Dr. Jorge M. Lobo, Professore di Ricerca presso il Dipartimento di Biogeography and Global Change do Museo Nacional de Ciencias Naturales, a Madrid, Spagna. L’articolo più citato dell’autore è “Use of niche models in invasive species risk assessments“, scritto in collaborazione con i ricercatori A. Jiménez-Valverde, A. T. Peterson, J. Soberón, J. M. Overton e P. Argon, che è anche il terzo articolo più citato (384), presentato nella tabella 4. Questo lavoro analizza l’uso dei dati sulla localizzazione delle specie per l’elaborazione di modelli predittivi per il rischio di insediamenti di specie invasive comuni in ampi set di dati sulla biodiversità, come i dati di georeferenziazione e le identificazioni errate delle specie.
Tabella 2 – Autori più produttivi
| Autori | Articoli |
| LOBO JM | 10 |
| HORTAL J | 9 |
| PAGE RDM | 7 |
| SOBERóN J | 6 |
| BOOTH TH | 5 |
| COSTELLO MJ | 5 |
| KREFT H | 5 |
| ARIñO AH | 4 |
| GURALNICK R | 4 |
Fonte: A cura degli autori (2020).
Tabella 3 – Autori più citati
| Autori | Citazioni |
| LOBO J M | 241 |
| PETERSON A T | 223 |
| HORTAL J | 217 |
| GUISAN A | 132 |
| COSTELLO M J | 117 |
| GRAHAM C H | 114 |
| SOBERÃ N J | 109 |
| FERRIER S | 108 |
| JIMÃ NEZ VALVERDE A | 108 |
Fonte: A cura degli autori (2020).
I cinque articoli più citati sono elencati nella Tabella 4. Il più citato è l’articolo intitolato “SequenceMatrix: concatenation software for the fast assembly of multi-gene dataset with character set and codon information”, prodotto da Vaidya, G., Lohman, D. J. e Meier, R. pubblicato nel 2011. In questo lavoro, gli autori presentano il software SequenceMatrix utilizzato nell’analisi e associazione di più geni da diversi dataset, sottolineando la facilità d’uso come punto di forza e presentandone le principali funzionalità. Il software abilita funzionalità di rilevamento e correzione degli errori contenuti nei dataset.
Andelman e Fagan (2000) valutano se l’uso di specie chiamate “bandiera” o “ombrello” sia efficiente nell’uso come sostituti nella conservazione, perché invece di concentrarsi sulla conservazione di più aree, l’attenzione è rivolta alla conservazione di queste aree poca specie, che di conseguenza aiuta nella conversazione di intere aree. Per verificare la loro ipotesi, gli autori hanno utilizzato tre database con diverse dimensioni di copertura.
Jayasiri et al. (2015) si occupa nel loro articolo della creazione di un database via web, incentrato sulla diversità dei funghi, al fine di migliorare l’accuratezza dei nomi scientifici, concentrandosi sulla tassonomia. La base conta 76 curatori specializzati nei diversi gruppi, garantendo così l’affidabilità dei dati.
Lobo, Jiménez-Valverde e Hortal (2010) trattano i dati sull’assenza di specie in alcune regioni contenute nei database, nella generazione di modelli di distribuzione. Hanno condotto un caso di studio di una specie di coleottero che ha una distribuzione nota, al fine di dimostrare i possibili errori nell’uso di questi dati di “assenza” e la sua importanza nella modellazione delle mappe di distribuzione.
Tabella 4 – i cinque articoli più citati
| Articoli | Citazioni totali |
| VAIDYA, G.; LOHMAN, D. J.; MEIER, R. SequenceMatrix: Concatenation software for the fast assembly of multi-gene datasets with character set and codon information. Cladistics, v. 27, n. 2, p. 171–180, 2011. | 847 |
| ANDELMAN, S. J.; FAGAN, W. F. Umbrellas and flagships: Efficient conservation surrogates or expensive mistakes? Proceedings of the National Academy of Sciences of the United States of America, v. 97, n. 11, p. 5954–5959, 2000. | 447 |
| JIMÉNEZ-VALVERDE, A. et al. Use of niche models in invasive species risk assessments. Biological Invasions, v. 13, n. 12, p. 2785–2797, 2011. | 384 |
| JAYASIRI, S. C. et al. The Faces of Fungi database: fungal names linked with morphology, phylogeny and human impacts. Fungal Diversity, v. 74, n. 1, p. 3–18, 2015. | 355 |
| LOBO, J. M.; JIMÉNEZ-VALVERDE, A.; HORTAL, J. The uncertain nature of absences and their importance in species distribution modelling. Ecography, v. 33, n. 1, p. 103–114, 2010. | 325 |
Fonte: A cura degli autori (2020).
I cinque articoli più citati nei documenti sono riportati nella tabella 5. L’articolo più citato nei documenti è “Interoperability of biodiversità databases: biodiversità information on each desktop”, prodotto dagli autori Edwards, Lane e Nielsen e pubblicato nell’anno 2000, nell’articolo e nel trattato sul GBIF, che nasce per facilitare la digitalizzazione dei dati sulla biodiversità, e renderli liberamente accessibili. Nell’articolo viene presentato il GBIF e le prospettive future dei dati sulla biodiversità.
Hortal e Lobo e Jiménez-Valverde (2007) presentano un caso di studio sui limiti riscontrati nei database della biodiversità, concentrandosi su una base sulla diversità dei semi e delle piante. Nel loro lavoro Soberón e Peterson (2004), discutono del potenziale della Biodiversity Informatics, nella loro discussione commentano l’applicazione dei metodi nella gestione della biodiversità, e non solo per gli studi fondamentali e la condivisione delle informazioni. Soberón et al. (2006), nel loro articolo, dimostrano l’uso dei dati sulla biodiversità presenti nelle basi per stimare la ricchezza e in diverse risoluzioni di distribuzione geografica. Bisby (2000) si occupa dell’emergere di grandi sistemi informativi biologici globali nella sua ricerca.
Tabella 5 – I 5 documenti più citati nelle referenze del periodo
| Documenti citati nei riferimenti | Numero di citazioni |
| EDWARDS, James L.; LANE, Meredith A.; NIELSEN, Ebbe S. Interoperability of biodiversity databases: biodiversity information on every desktop. Science, v. 289, n. 5488, p. 2312-2314, 2000. | 49 |
| HORTAL, Joaquín; LOBO, Jorge M.; JIMÉNEZ‐VALVERDE, ALBERTO. Limitations of biodiversity databases: case study on seed‐plant diversity in Tenerife, Canary Islands. Conservation Biology, v. 21, n. 3, p. 853-863, 2007. | 37 |
| SOBERÓN, Jorge; PETERSON, Townsend. Biodiversity informatics: managing and applying primary biodiversity data. Philosophical Transactions of the Royal Society of London. Series B: Biological Sciences, v. 359, n. 1444, p. 689-698, 2004. | 34 |
| SOBERÓN, Jorge et al. Assessing completeness of biodiversity databases at different spatial scales. Ecography, v. 30, n. 1, p. 152-160, 2007. | 25 |
| BISBY, Frank A. The quiet revolution: biodiversity informatics and the internet. Science, v. 289, n. 5488, p. 2309-2312, 2000. | 23 |
Fonte: A cura degli autori (2020).
Le parole chiave più utilizzate dagli autori Database (49), seguite da biodiversity (32), taxonomy (26), biodiversity informatics (19) e data quality (19), queste frequenze di parole sono state probabilmente influenzate dalla metodologia di selezione dei documenti effettuata in questa ricerca. La figura 1 mostra le 50 parole chiave con l’occorrenza più alta del 1033.
Figura 1 – Le 50 parole chiave più frequenti dell’autore

Per quanto riguarda le parole chiave estese, la parola più utilizzata è Biodiversity (236), seguita da database (125), Taxonomy (88), dataset (66) e classification (62). E negli abstract le parole più frequenti data (1.221), species (856), biodiversity (488), database (315), databases (268). Le parole più frequenti nei titoli dei documenti sono data (113), biodiversity (100), species (68), database (57), databases (44).
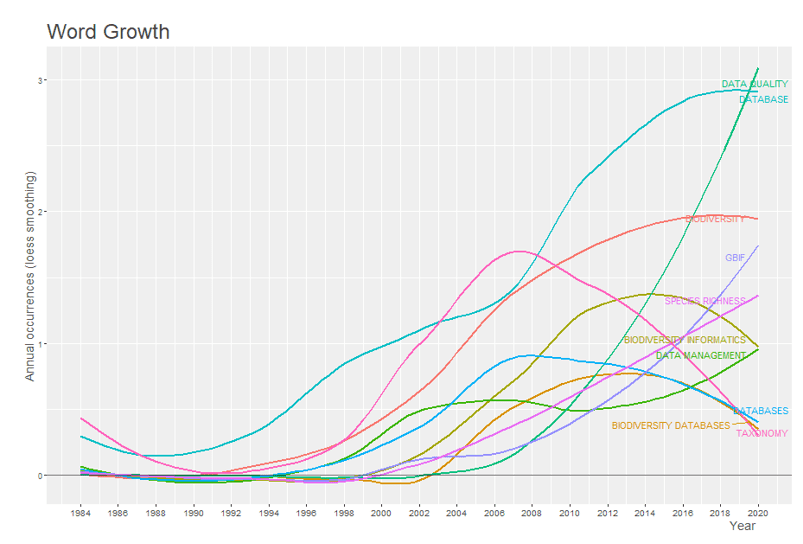
Le 10 parole chiave degli autori con le frequenze più alte sono rappresentate in base al numero di occorrenze accumulate nel tempo nel grafico 4. Nel grafico è inoltre possibile osservare la crescita esponenziale della data quality della parola, che può indicare un aumento di interesse da studi volti a valutare le informazioni contenute nelle banche dati esistenti, insieme a questa parola e osservando la crescita della parola GBIF, che corrisponde al Global Biodiversity Information Facility, che è una rete internazionale per la condivisione di dati su tutti i tipi di vita nel territorio. Le parole database, biodiversity database, databases e biodiversity informatics hanno mostrato un declino nell’uso negli ultimi anni.
Grafico 4 – Dinamica delle parole chiave dell’autore nel tempo
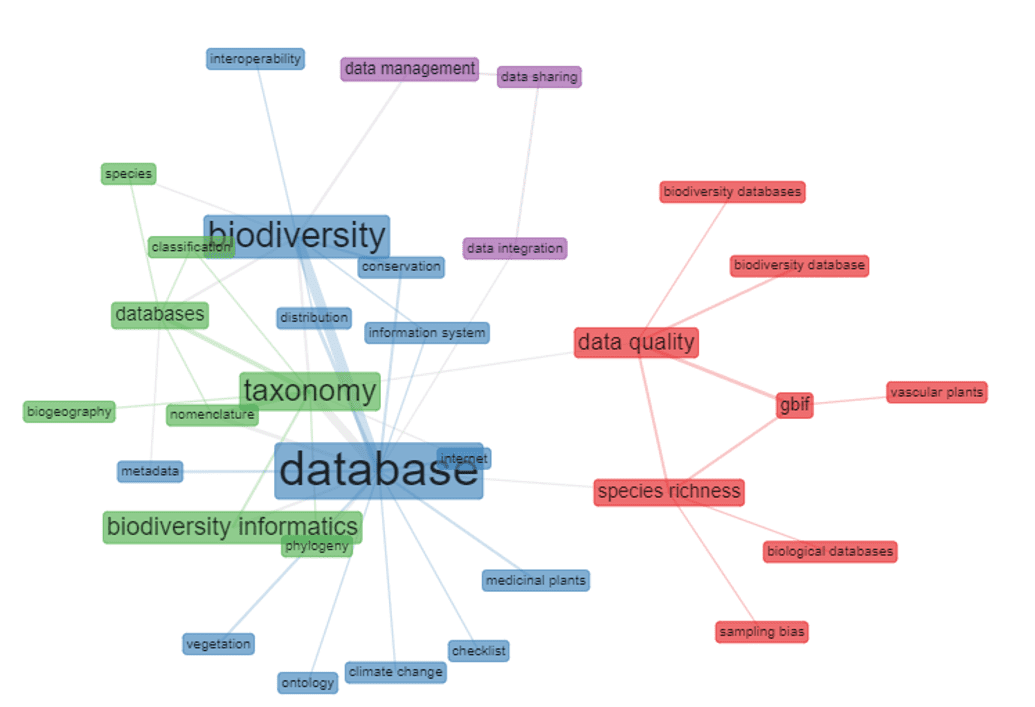
Nell’analisi di co-occorrenza delle parole chiave si possono percepire alcune relazioni: a) database – biodiversity – metadata, internet, information system, distribution, conservation e checklist; b) taxonomy – biodiversity informatics e phylogeny – databases– species, classification, nomenclature e biogeography; c) data quality – species richness – biodiversity databases, biodiversity database, GBIF e biological databases; d) data management, datashring e data integration. Vale la pena evidenziare le relazioni presentate nell’insieme “c”, in cui è possibile osservare il focus sulla qualità dei dati presentati nelle basi, con un focus sul GBIF. La separazione tra l’insieme “a” e “b”, si presenta in modo interessante, rendendo visibile la differenza nel focus della ricerca, dove l’insieme “a” era incentrato sulla distribuzione, conservazione e diversità delle specie, mentre il l’insieme “b” si occupa maggiormente della nomenclatura e della classificazione delle specie. La figura 2 presenta le suddette relazioni.
Figura 2 – La co-occorrenza delle parole chiave utilizzate dagli autori
5. CONSIDERAZIONI PARZIALI
Il presente studio ha presentato l’evoluzione delle produzioni scientifiche relative ai database di biodiversità e tassonomia presenti nel database Scopus. La query ha restituito 352 documenti, distribuiti nel periodo dal 1984 al 2020. C’è stato un aumento delle pubblicazioni dal 2006 in poi.
Secondo le informazioni ottenute attraverso le analisi, è stato possibile visualizzare la crescita delle produzioni e dei paesi che hanno prodotto di più sull’argomento, e ha permesso di evidenziare le pubblicazioni più citate a cui si fa riferimento.
L’identificazione delle parole chiave più utilizzate è stata forse influenzata dalla metodologia applicata in questa ricerca, in quanto sono state utilizzate nei termini di ricerca applicati nel database di Scopus. Tuttavia, è possibile osservare una crescita dell’interesse per i documenti recuperati in relazione alla qualità dei dati presenti in queste basi.
Questo articolo presenta l’approccio esplorativo iniziale ai database relativi alla biodiversità. Sulla base dei risultati, in futuro verranno approfondite le problematiche relative alla qualità dei dati presenti nei database più utilizzati, come il database GBIF. Un altro punto da affrontare nella ricerca futura è la forma di rappresentazione delle specie brasiliane in questi database e la possibilità di recuperare queste informazioni dalle parti interessate.
La continuità della ricerca è in linea con gli interessi proposti nella tesi dell’autore, in cui propone lo sviluppo di un database/portale ad accesso aperto, che faciliti la diffusione dei dati sulla diversità della fauna brasiliana (animali), valorizzando i dati di qualità in costante aggiornamento e fiducia, per soddisfare le esigenze di professionisti e ricercatori delle aree biologiche.
RIFERIMENTI
ANDELMAN, S. J.; FAGAN, W. F. Umbrellas and flagships: Efficient conservation surrogates or expensive mistakes? Proceedings of the National Academy of Sciences of the United States of America, v. 97, n. 11, p. 5954–5959, 2000.
BISBY, Frank A. The quiet revolution: biodiversity informatics and the internet. Science, v. 289, n. 5488, p. 2309-2312, 2000.
EDWARDS, James L.; LANE, Meredith A.; NIELSEN, Ebbe S. Interoperability of biodiversity databases: biodiversity information on every desktop. Science, v. 289, n. 5488, p. 2312-2314, 2000.
FRAZIER, C.K., WALL, J.; GRANT, S.. Initiating a Natural History CollectionDigitisation Project, version 1.0. Copenhagen: Global Biodiversity Information Facility.75 pp. 2008.
HORTAL, Joaquín; LOBO, Jorge M.; JIMÉNEZ‐VALVERDE, ALBERTO. Limitations of biodiversity databases: case study on seed‐plant diversity in Tenerife, Canary Islands. Conservation Biology, v. 21, n. 3, p. 853-863, 2007.
JAYASIRI, S. C. et al. The Faces of Fungi database: fungal names linked with morphology, phylogeny and human impacts. Fungal Diversity, v. 74, n. 1, p. 3–18, 2015.
JIMÉNEZ-VALVERDE, Alberto et al. Use of niche models in invasive species risk assessments. Biological invasions, v. 13, n. 12, p. 2785-2797, 2011.
LOBO, J. M.; JIMÉNEZ-VALVERDE, A.; HORTAL, J. The uncertain nature of absences and their importance in species distribution modelling. Ecography, v. 33, n. 1, p. 103–114, 2010.
RUA, J. DIGITALIZAÇÃO, PRESERVAÇÃO E ACESSO: contributos para o projeto Museu Digital da U.PORTO. Páginas a&b. S.3, nº especial (2017) 199-229 | DOI 10.21747/21836671/pag2017a13
SOBERÓN, Jorge et al. Assessing completeness of biodiversity databases at different spatial scales. Ecography, v. 30, n. 1, p. 152-160, 2007.
SOBERÓN, Jorge; PETERSON, Townsend. Biodiversity informatics: managing and applying primary biodiversity data. Philosophical Transactions of the Royal Society of London. Series B: Biological Sciences, v. 359, n. 1444, p. 689-698, 2004.
VAIDYA, G.; LOHMAN, D. J.; MEIER, R. SequenceMatrix: Concatenation software for the fast assembly of multi-gene datasets with character set and codon information. Cladistics, v. 27, n. 2, p. 171–180, 2011.
WILSON, Edward O. Systematics and the future of biology. Proceedings of the National Academy of Sciences, v. 102, n. suppl 1, p. 6520-6521, 2005.
[1] Laureato in Scienze Biologiche, Pontifícia Universidade Católica do Paraná (PUC-PR), Paraná, Brasile. Laureato in Elettronica Industriale, Faculdade de Tecnologia de Curitiba (FATEC) Curitiba, Paraná, Brasile. Studente del Master in Information Management, Universidade Federal do Paraná (UFPR), Curitiba, Paraná, Brasile.
[2] Dottorato di ricerca in Ingegneria Elettrica e Informatica, Universidade Tecnológica Federal do Paraná (UTFPR), Curitiba, Paraná, Brasile.
Inviato: Settembre 2020.
Approvato: Settembre 2020.