BIBLIOMETRISCHE ÜBERPRÜFUNG
TEDESCHI, Victor Hugo Pancera [1], TSUNODA, Denise Fukumi [2]
TEDESCHI, Victor Hugo Pancera. TSUNODA, Denise Fukumi. Datenbank zur Biodiversität: Eine zeitliche Analyse der wissenschaftlichen Produktion. Revista Científica Multidisciplinar Núcleo do Conhecimento. Jahr 05, Ed. 09, Bd. 06, p. 68-81. September 2020. ISSN: 2448-0959, Zugangslink: https://www.nucleodoconhecimento.com.br/biologie-de/wissenschaftlichen-produktion
ZUSAMMENFASSUNG
Die vorliegende Forschungsarbeit befasst sich mit Biodiversitätsdatenbanken durch eine bibliografische Umfrage auf dem Zeitschriftenportal Scopus, wobei englische Begriffe und Limiter in den Schlüsselwörtern verwendet werden, um die Suche auf die Datenbank einzuschränken. Die Dokumente wurden mithilfe von Bibliometrie in Biblioshiny (einem R-Paket) analysiert. Insgesamt wurden 352 veröffentlichte Dokumente aus dem Zeitraum von 1984 bis 2020 abgerufen. Durch die Analyse wurde eine Zunahme der Veröffentlichungen ab dem Jahr 2006 beobachtet. Die Forscher aus den Vereinigten Staaten (54) präsentierten die meisten Publikationen, während Brasilien ( 11) liegt auf dem sechsten Platz. Die in dieser Untersuchung gefundenen Ergebnisse weisen auf einen Trend in Arbeiten zu diesem Thema hin und geben somit eine Richtung für zukünftige Forschung vor.
Schlüsselwörter: Taxonomische Datenbank, Biodiversitätsinformatik, Datensatz, Bibliometrie.
1. EINLEITUNG
Die biologische Vielfalt auf dem Planeten ist sehr hoch und einige Schätzungen gehen von Werten in Millionenhöhe aus. Brasilien beheimatet konservativen Schätzungen zufolge 13 % der weltweiten Biota. Diese Schätzung ist darauf zurückzuführen, dass Brasilien das größte Flusssystem der Welt sowie fünf Biome hat, was dem Land den Titel „mega vielfältiges Land“ einbrachte und ungefähr 165.000 bekannte Arten in Betracht zieht, und jeden Tag werden mehr Arten entdeckt.
Jeder entdeckte Teil einer Art generiert kontinuierlich und aggregiert Daten über seine Merkmale (Morphologie, Nomenklatur, Phylogenie usw.), Gewohnheiten (Ernährung, Verhalten usw.), seine geografische Verbreitung (Sichtungen, Sammlung Aufzeichnungen usw.), Genetik (Phylogenetik, DNA-Sequenzierung usw.) unter anderem.
Alle diese Informationen müssen gespeichert werden, um ihren Zugriff und ihre weltweite Weitergabe zu erleichtern, was die Notwendigkeit der Entwicklung und Pflege von Datenbanken rechtfertigt, die die korrekte Speicherung dieser Informationen sowie spezifische Wiederherstellung Systeme für das Gebiet durchführen. Ausgehend von diesem Gedanken ist es das Ziel der vorliegenden Arbeit, durch eine bibliometrische Analyse die Produktion zu diesem Thema zu untersuchen, die in der Scopus-Referenzdatenbank hinterlegt ist, die unter anderem begutachtete akademische Titel, Open-Access-Titel, Konferenzberichte und kommerzielle Veröffentlichungen indexiert andere.
2. THEORETISCHE GRUNDLAGE
Datenbank kann als Sammlung logisch zusammenhängender Daten definiert werden, die eine Bedeutung haben, deren Interpretation je nach Anwendung gegeben ist, diese Datensammlung repräsentiert abstrakt einen Teil der realen Welt.
Biologische Informationen können in die drei Dimensionen Molekular, Organismus und Ökosystem (WILSON, 2005) eingeteilt werden, entsprechend ihrer Anwendung werden diese Informationen in drei Strukturtypen von Basen geordnet, die taxonomischen Basen (Organismen) sind, die sich auf die Darstellung der morphologischen Informationen der Art, Grundlagen der Informatik für die Biodiversität (Ökosystem), die einen transdisziplinären Informationscharakter hat, um ökologische Informationen und geografische Verbreitung bereitzustellen, und der Bioinformatik (Molekular), die wiederum auf die Speicherung und Verbreitung abzielt von molekularen Daten, Genen und Proteinen.
Die Informationen, die diese Datenbanken speisen, stammen aus den Digitalisierungsprozessen von Museumssammlungen, Sammlungsberichten, Einberufungslisten, Auszügen aus veröffentlichten Dokumenten, der Sequenzierung von Materialien usw. Die Ergebnisse dieses Scans können in einer Vielzahl von Formaten wie Text Dokumenten, Tabellenkalkulationen, Webseiten, verwandten Datenbanken, Karten oder GIS (Geografisches Informations System), Bildern usw. gespeichert oder geteilt werden. (FRAZIER; WAND; GRANT, 2008)
Die Digitalisierung dieser Materialien ist von entscheidender Bedeutung für die Erhaltung und Weitergabe von Arteninformationen, aber dieser Ansatz bringt neue Herausforderungen mit sich, wie z. B. die Zuverlässigkeit digitalisierter Daten. Ausgehend von diesem Punkt hebt Ruas (2017) die Bedeutung von Metadaten hervor Informationen, die die in der Datenbank enthaltenen Informationen beschreiben, bei der Kuratierung der durch die Digitalisierung Prozesse generierten Inhalte, garantieren die Metainformationen die Treue und Authentizität der präsentierten Informationen sowie die Kontextualisierung und dass die Informationen erfasst wurden.
3. METHODISCHER KURS
Die Auswahl der in dieser Untersuchung zu verwendenden Begriffe erfolgte durch Experimentieren mit verschiedenen Sätzen boolescher Wörter und Operatoren auf der Grundlage von Scopus. Der Forschungsfluss (von allgemeinen zu spezifischen Ebenen) und die Anzahl der in jedem Experiment abgerufenen Dokumente sind in Tabelle 1 dargestellt.
Tabelle 1 – Wortgruppen und boolesche Operatoren, die in der Scopus-Datenbank verwendet werden, und die Anzahl der abgerufenen Dokumente
| Wörter und Operatoren | Wiederhergestellte Dokumente |
| ALL ( biodiversity AND database ) | 91.714 |
| ALL ( taxonomy AND database ) | 113.470 |
| ALL ( biodiversity OR taxonomy AND database OR dataset ) | 226.573 |
| ALL ( “biodiversity database” ) | 1.487 |
| ALL ( “biodiversity database” OR “taxonomy database” ) | 2.158 |
| ALL ( “biodiversity database” OR “taxonomy database” ) AND ( LIMIT-TO ( EXACTKEYWORD , “Biodiversity” ) OR LIMIT-TO ( EXACTKEYWORD , “Taxonomy” ) OR LIMIT-TO ( EXACTKEYWORD , “Databases, Genetic” ) OR LIMIT-TO ( EXACTKEYWORD , “Factual Database” ) OR LIMIT-TO ( EXACTKEYWORD , “Data Set” ) OR LIMIT-TO ( EXACTKEYWORD , “Protein Database” ) OR LIMIT-TO ( EXACTKEYWORD , “Databases, Protein” ) OR LIMIT-TO ( EXACTKEYWORD , “Biodiversity Informatics” ) OR LIMIT-TO ( EXACTKEYWORD , “Data Quality” ) ) AND ( EXCLUDE ( SUBJAREA , “IMMU” ) OR EXCLUDE ( SUBJAREA , “MEDI” ) OR EXCLUDE ( SUBJAREA , “NEUR” ) OR EXCLUDE ( SUBJAREA , “PHYS” ) OR EXCLUDE ( SUBJAREA , “PHAR” ) OR EXCLUDE ( SUBJAREA , “ARTS” ) OR EXCLUDE ( SUBJAREA , “VETE” ) OR EXCLUDE ( SUBJAREA , “HEAL” ) OR EXCLUDE ( SUBJAREA , “NURS” ) ) | 723 |
Quelle: Erstellt von den Autoren (2020).
Aus den gefundenen Ergebnissen wurden die ersten 100 Dokumente gelesen, um zu beobachten, ob die Ergebnisse mit dem in der vorliegenden Forschung behandelten Thema übereinstimmen, und somit Anpassungen an den Begriffen vorgenommen, um die Ergebnisse zu verfeinern. Wie in Tabelle 1 zu sehen ist, reichte die Anzahl der abgerufenen Dokumente bei einigen Begriffs Kombinationen von 700 bis über 200.000 Dokumenten. Dieser Schritt war notwendig, da Begriffe wie biodiversity und taxonomic von Forschern in den Biowissenschaften in unterschiedlichen Zusammenhängen verwendet werden.
Die Suchstrategie in der Scopus-Datenbank (Elsevier) war die Suche nach den englischen Begriffen „biodiversity database“ und „taxonomic database“, in allen Feldern wurde ein Limiter in den Schlüsselwörtern verwendet, der diejenigen auswählt, die mit den Daten in Verbindung stehen, die Wörter ausgewählt werden „Database“, „Data set“, „Data Base“, „database, factual“, „factual database“, „Database Systems“, „data quality“ und „data management“, wobei die bis dato erzielten Ergebnisse verwendet werden aus der Suche am 28. Juni 2020. Die Abfrageparameter mit Feldcodes und Operatoren ergaben:

Die metrische Analyse der Worthäufigkeit (Titel, Zusammenfassung, Schlüsselwörter der Autoren, erweiterte Schlüsselwörter), der Dokumenterstellung Häufigkeit (Länder, Quellen, Autoren) und der Entwicklung im Laufe der Zeit (Produktion nach Jahr, Verwendung von Schlüsselwörtern) wurde mit Biblioshiny (grafische Oberfläche des Bibliometrix-Paket, erstellt in R-Sprache) und dem Microsoft Excel-Tabellenkalkulations Editor. Die Daten wurden direkt aus der Scopus-Datenbank im CSV-Format exportiert, das mit der Biblioshiny -Bibliothek für Software R v.3.6.3 und Microsoft Excel 2016 kompatibel ist.
4. PRÄSENTATION UND DISKUSSION DER ERGEBNISSE
Die Analyse umfasst die 352 in der Scopus-Datenbank Suche am 28. Juni 2020 gefundenen Dokumente, davon 272 veröffentlichte Artikel, 30 Tagungsbände und ein Buchkapitel. Die erste gefundene Veröffentlichung bezieht sich auf das Jahr 1984. Die 352 gefundenen Dokumente wurden von 1.978 Autoren verfasst. 2.068 erweiterte Schlüsselwörter (Wörter, die automatisch von der Datenbank generiert werden) und 1.033 Autoren-Schlüsselwörter wurden identifiziert.
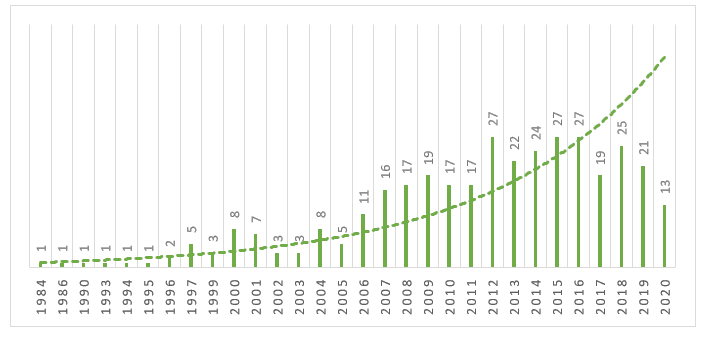
Wie in Grafik 1 gezeigt, ist zu beobachten, dass im Zeitraum zwischen 1984 und 1996 keine nennenswerte Produktion zu diesem Thema stattfand, nach diesem Zeitraum ist eine Zunahme der Anzahl von Produktionen zu diesem Thema zu beobachten. Es wird beobachtet, dass es 2017 eine erhebliche Oszillation gab, bei der es zu einem Produktionsrückgang und einer Wiederaufnahme im nächsten Jahr kam. Bis zum Zeitpunkt dieser Recherche präsentiert 2020 bereits 13 veröffentlichte Artikel.
Grafik 1 – Entwicklung der wissenschaftlichen Produktion in der Scopus-Datenbank von 1984 bis 2020
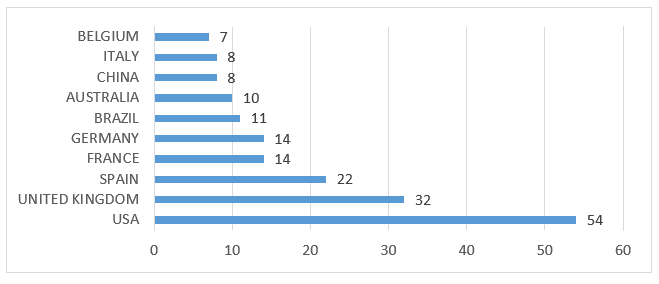
Die Verteilung der Dokumente nach Ländern zeigt die Vereinigten Staaten von Amerika (54) mit der höchsten Anzahl an Veröffentlichungen in diesem Bereich, gefolgt vom Vereinigten Königreich (32), das eine Dominanz von Dokumenten in englischer Sprache aufweist. Dieses Ergebnis kann durch die Verwendung von Suchbegriffen in englischer Sprache beeinflusst worden sein. Andererseits verwenden mehrere Zeitschriften in verschiedenen Sprachen den Abstract als eines der obligatorischen Elemente. Brasilien (11) belegt den sechsten Platz in der Anzahl der Veröffentlichungen, wie in Grafik 2 gezeigt.
Diagramm 2 – Beitrag der wissenschaftlichen Produktion in der Welt
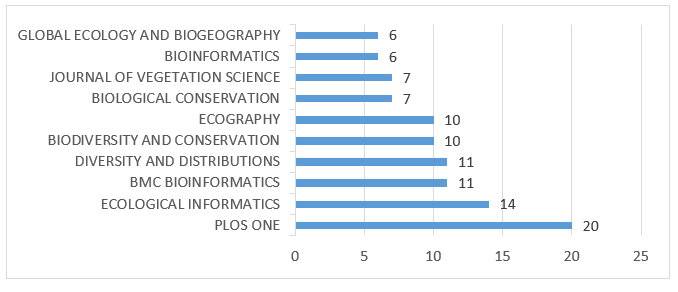
Unter den 352 in der Abfrage gefundenen Dokumenten wies PLOS ONE mit insgesamt 20 Artikeln die meisten veröffentlichten Artikel auf, gefolgt von Ecological Informatics mit 14. Grafik 3 zeigt die 10 Quellen mit der höchsten Anzahl an Veröffentlichungen.
Grafik 3 – Quellen mit der höchsten Anzahl an Produktionen
Die 10 produktivsten Forscher sind in Tabelle 2 und die 10 am häufigsten zitierten in Tabelle 3 aufgeführt. Der produktivste Autor (10) und der am häufigsten zitierte (241) ist Dr. Jorge M. Lobo, Forschungsprofessor am Department of Biogeography and Global Change des Museo Nacional de Ciencias Naturales in Madrid, Spanien. Der am häufigsten zitierte Artikel des Autors ist „Use of niche models in invasive species risk assessments“, der gemeinsam mit den Forschern A. Jiménez-Valverde, A. T. Peterson, J. Soberón, J. M. Overton und P. Argon verfasst wurde, was auch der am dritthäufigsten zitierte Artikel ist (384), dargestellt in Tabelle 4. Diese Arbeit analysiert die Verwendung von Standortdaten von Arten für die Ausarbeitung von Vorhersagemodellen für das Risiko der Ansiedlung invasiver Arten, die in großen Biodiversitäts Datensätzen wie Georeferenzierungsdaten und Fehlidentifikationen von Arten üblich ist.
Tabelle 2 – Die produktivsten Autoren
| Autoren | Artikel |
| LOBO JM | 10 |
| HORTAL J | 9 |
| PAGE RDM | 7 |
| SOBERóN J | 6 |
| BOOTH TH | 5 |
| COSTELLO MJ | 5 |
| KREFT H | 5 |
| ARIñO AH | 4 |
| GURALNICK R | 4 |
Quelle: Erstellt von den Autoren (2020).
Tabelle 3 – Am häufigsten zitierte Autoren
| Autoren | Zitate |
| LOBO J M | 241 |
| PETERSON A T | 223 |
| HORTAL J | 217 |
| GUISAN A | 132 |
| COSTELLO M J | 117 |
| GRAHAM C H | 114 |
| SOBERÃ N J | 109 |
| FERRIER S | 108 |
| JIMÃ NEZ VALVERDE A | 108 |
Quelle: Erstellt von den Autoren (2020).
Die fünf Artikel, auf die am häufigsten verwiesen wird, sind in Tabelle 4 aufgeführt. Der am häufigsten zitierte Artikel ist der Artikel mit dem Titel „SequenceMatrix: concatenation software for the fast assembly of multi-gene datasets with character set and codon information“, produziert von Vaidya, G., Lohman, D. J. und Meier, R., veröffentlicht im Jahr 2011. In dieser Arbeit stellen die Autoren die SequenceMatrix-Software vor, die bei der Analyse und Assoziation mehrerer Gene aus verschiedenen datasets verwendet wird, wobei die Benutzerfreundlichkeit als Stärke hervorgehoben und ihre Haupt Funktionalitäten vorgestellt werden. Die Software ermöglicht Funktionen zur Erkennung und Korrektur von in den datasets enthaltenen Fehlern.
Andelman und Fagan (2000) bewerten, ob die Verwendung von Arten, die als „flag“ oder „umbrella“ bezeichnet werden, als Ersatz für den Naturschutz effizient sind, da der Fokus nicht auf der Erhaltung mehrerer Gebiete liegt, sondern auf der Erhaltung dieser Gebiete wenig Arten, was folglich bei der Konversation ganzer Gebiete hilft. Um ihre Hypothese zu testen, verwendeten die Autoren drei Datenbanken mit unterschiedlichen Abdeckungen Dimensionen.
Jayasiri et al. (2015) beschäftigt sich in ihrem Artikel mit der Erstellung einer Datenbank über das Internet, fokussiert auf die Diversität von Pilzen, um die Genauigkeit wissenschaftlicher Namen zu verbessern, mit Fokus auf Taxonomie. Die Basis verfügt über 76 Kuratoren, die auf die verschiedenen Gruppen spezialisiert sind und so die Datensicherheit gewährleisten.
Lobo, Jiménez-Valverde und Hortal (2010) beschäftigen sich bei der Erstellung von Verbreitungsmodellen mit den in den Datenbanken enthaltenen Daten zum Fehlen von Arten in bestimmten Regionen. Sie führten eine Fallstudie einer Käferart mit bekannter Verbreitung durch, um die möglichen Fehler bei der Verwendung dieser Abwesenheitsdaten und ihre Bedeutung bei der Modellierung von Verbreitungskarten aufzuzeigen.
Tabelle 4 – die fünf am häufigsten zitierten Artikel
| Artikel | Zitate insgesamt |
| VAIDYA, G.; LOHMAN, D. J.; MEIER, R. SequenceMatrix: Concatenation software for the fast assembly of multi-gene datasets with character set and codon information. Cladistics, v. 27, n. 2, p. 171–180, 2011. | 847 |
| ANDELMAN, S. J.; FAGAN, W. F. Umbrellas and flagships: Efficient conservation surrogates or expensive mistakes? Proceedings of the National Academy of Sciences of the United States of America, v. 97, n. 11, p. 5954–5959, 2000. | 447 |
| JIMÉNEZ-VALVERDE, A. et al. Use of niche models in invasive species risk assessments. Biological Invasions, v. 13, n. 12, p. 2785–2797, 2011. | 384 |
| JAYASIRI, S. C. et al. The Faces of Fungi database: fungal names linked with morphology, phylogeny and human impacts. Fungal Diversity, v. 74, n. 1, p. 3–18, 2015. | 355 |
| LOBO, J. M.; JIMÉNEZ-VALVERDE, A.; HORTAL, J. The uncertain nature of absences and their importance in species distribution modelling. Ecography, v. 33, n. 1, p. 103–114, 2010. | 325 |
Quelle: Erstellt von den Autoren (2020).
Die fünf am häufigsten zitierten Artikel in den Dokumenten sind in Tabelle 5 aufgeführt. Der am häufigsten zitierte Artikel in den Dokumenten ist „Interoperability of biodiversity databases: biodiversity information on every desktop“, erstellt von den Autoren Edwards, Lane und Nielsen und veröffentlicht im Jahr 2000, im Artikel und Vertrag über den GBIF, der geschaffen wurde, um die Digitalisierung von Daten zur Biodiversität zu erleichtern und frei zugänglich zu machen. In dem Artikel wird über GBIF und die Zukunftsperspektiven von Daten zur Biodiversität berichtet.
Hortal und Lobo und Jiménez-Valverde (2007) stellen eine Fallstudie zu den Einschränkungen vor, die in Biodiversitätsdatenbanken festgestellt werden, wobei der Schwerpunkt auf der Grundlage der Samen- und Pflanzenvielfalt liegt. In ihrer Arbeit Soberón und Peterson (2004) diskutieren sie das Potenzial der Biodiversitätsinformatik, in ihrer Diskussion kommentieren sie die Anwendung von Methoden im Biodiversitätsmanagement, und zwar nicht nur für grundlegende Studien und den Informationsaustausch. Soberón et al. (2006) demonstrieren in ihrem Artikel die Verwendung von Daten zur Biodiversität, die in den Basen vorhanden sind, um den Reichtum und die geografische Verteilung in unterschiedlichen Auflösungen abzuschätzen. Bisby (2000) beschäftigt sich in seiner Forschung mit der Entstehung großer globaler biologischer Informationssysteme.
Tabelle 5 – die 5 am häufigsten zitierten Dokumente in den Referenzen im Zeitraum
| In den Referenzen zitierte Dokumente | Anzahl der Zitate |
| EDWARDS, James L.; LANE, Meredith A.; NIELSEN, Ebbe S. Interoperability of biodiversity databases: biodiversity information on every desktop. Science, v. 289, n. 5488, p. 2312-2314, 2000. | 49 |
| HORTAL, Joaquín; LOBO, Jorge M.; JIMÉNEZ‐VALVERDE, ALBERTO. Limitations of biodiversity databases: case study on seed‐plant diversity in Tenerife, Canary Islands. Conservation Biology, v. 21, n. 3, p. 853-863, 2007. | 37 |
| SOBERÓN, Jorge; PETERSON, Townsend. Biodiversity informatics: managing and applying primary biodiversity data. Philosophical Transactions of the Royal Society of London. Series B: Biological Sciences, v. 359, n. 1444, p. 689-698, 2004. | 34 |
| SOBERÓN, Jorge et al. Assessing completeness of biodiversity databases at different spatial scales. Ecography, v. 30, n. 1, p. 152-160, 2007. | 25 |
| BISBY, Frank A. The quiet revolution: biodiversity informatics and the internet. Science, v. 289, n. 5488, p. 2309-2312, 2000. | 23 |
Quelle: Erstellt von den Autoren (2020).
Die von der Autoren Database am häufigsten verwendeten Schlüsselwörter (49), gefolgt von biodiversity (32), taxonomy (26), biodiversity informatics (19) und data quality (19), diese Worthäufigkeiten wurden wahrscheinlich von der in durchgeführten Dokumentauswahlmethode beeinflusst diese Forschung. Abbildung 1 zeigt die 50 Keywords mit dem höchsten Vorkommen der 1033.
Abbildung 1 – Die 50 häufigsten Keywords des Autors

Bei den erweiterten Schlüsselwörtern ist das am häufigsten verwendete Wort Biodiversity (236), gefolgt von database (125), Taxonomy (88), dataset (66) und classification (62). Und in den Abstracts die häufigsten Wörter data (1.221), species (856), biodiversity (488), database (315), databases (268). Die häufigsten Wörter in den Titeln der Dokumente sind data (113), biodiversity (100), species (68), database (57), databases (44).
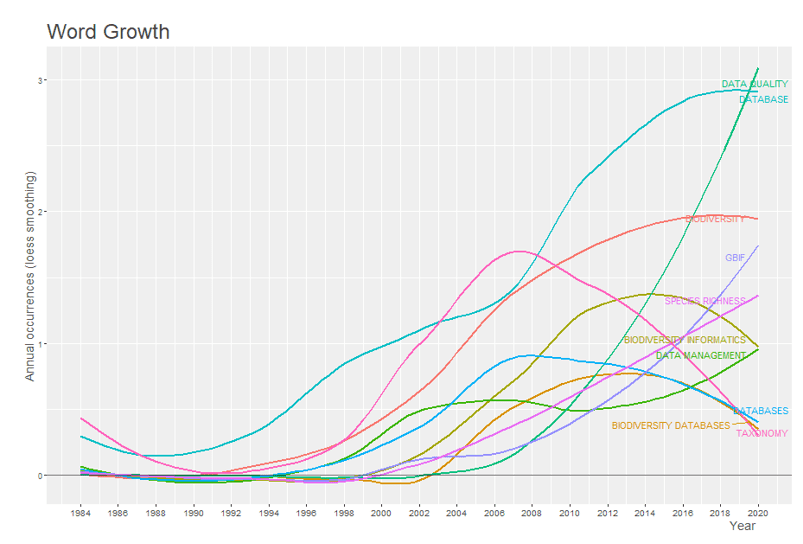
In Grafik 4 sind die 10 Keywords der Autoren mit den höchsten Häufigkeiten nach der Anzahl der über die Zeit kumulierten Vorkommen dargestellt. In der Grafik ist auch das exponentielle Wachstum der Wort data quality zu beobachten, was auf eine Zunahme des Interesses hindeuten kann durch Studien, die darauf abzielen, die in bestehenden Datenbanken enthaltenen Informationen zusammen mit diesem Wort auszuwerten und das Wachstum des Wortes GBIF zu beobachten, das der Global Biodiversity Information Facility entspricht, einem internationalen Netzwerk zum Austausch von Daten über alle Arten von Leben im Land. Die Wörter database, biodiversity database, databases und biodiversity informatics haben in den letzten Jahren einen Rückgang der Verwendung gezeigt.
Grafik 4 – Dynamik der Keywords des Autors im Laufe der Zeit
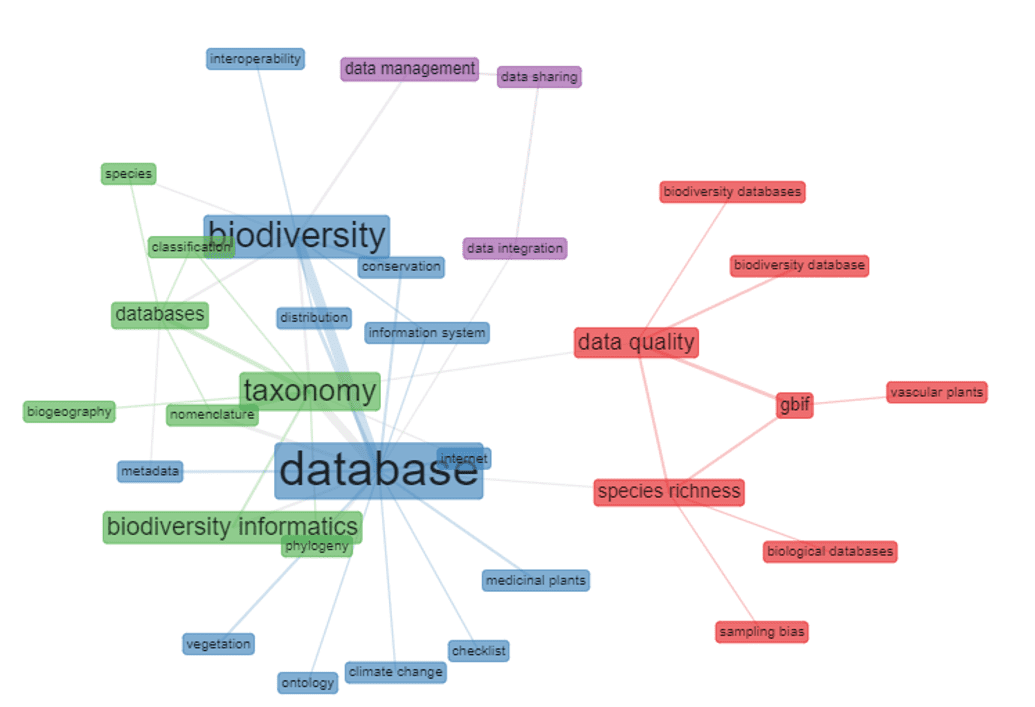
In der Co-Occurrence-Analyse der Schlüsselwörter lassen sich einige Beziehungen erkennen: a) database – biodiversity – metadata, internet, information system, distribution, conservation und checklist; b) taxonomy – biodiversity informatics und phylogeny – databases– species, classification, nomenclature e biogeography; c) data quality – species richness – biodiversity databases, biodiversity database, GBIF und biological databases; d) data management, datashring und data integration. Hervorzuheben sind die in Satz „c“ dargestellten Beziehungen, in denen der Schwerpunkt auf der Qualität der in den Grundlagen präsentierten Daten mit Schwerpunkt auf GBIF zu beobachten ist. Die Trennung zwischen dem Set „a“ und „b“ stellt sich auf interessante Weise dar und macht den Unterschied im Fokus der Forschung sichtbar, wo sich das Set „a“ auf die Verbreitung, Erhaltung und Vielfalt von Arten konzentrierte, während das Satz „b“ befasst sich mehr mit der Nomenklatur und Klassifikation von Arten. Abbildung 2 zeigt die oben genannten Beziehungen.
Abbildung 2 – Das gemeinsame Vorkommen der von den Autoren verwendeten Schlüsselwörter
5. TEILÜBERLEGUNGEN
Die vorliegende Studie präsentierte die Entwicklung wissenschaftlicher Produktionen im Zusammenhang mit den Biodiversitäts- und Taxonomie-Datenbanken, die in der Scopus-Datenbank zu finden sind. Die Abfrage ergab 352 Dokumente, verteilt im Zeitraum von 1984 bis 2020. Ab 2006 gab es eine Zunahme der Veröffentlichungen.
Anhand der durch die Analysen gewonnenen Informationen war es möglich, das Wachstum der Produktionen und die Länder, die zu diesem Thema am meisten produzierten, zu visualisieren und die am häufigsten zitierten Veröffentlichungen hervorzuheben.
Die Identifizierung der am häufigsten verwendeten Schlüsselwörter wurde möglicherweise durch die bei dieser Untersuchung angewandte Methodik beeinflusst, da sie in den in der Scopus-Datenbank verwendeten Suchbegriffen verwendet wurden. Es ist jedoch ein wachsendes Interesse an den wiederhergestellten Dokumenten im Zusammenhang mit der Qualität der in diesen Datenbanken gefundenen Daten zu beobachten.
Dieser Artikel stellt den ersten explorativen Ansatz für Datenbanken mit Bezug zur Biodiversität vor. Basierend auf den Ergebnissen werden Probleme im Zusammenhang mit der Qualität der Daten in den am häufigsten verwendeten Datenbanken, wie der GBIF-Datenbank, in Zukunft besser untersucht. Ein weiterer Punkt, der in zukünftigen Forschungen angegangen werden soll, ist die Form der Darstellung brasilianischer Arten in diesen Datenbanken und die Möglichkeit, diese Informationen von interessierten Parteien abzurufen.
Die Kontinuität der Forschung steht im Einklang mit den Interessen, die in der Dissertation des Autors vorgeschlagen werden, in der er die Entwicklung einer Open-Access-Datenbank/eines Portals vorschlägt, das die Verbreitung von Daten über die Vielfalt der brasilianischen Fauna (Tiere) erleichtert und Qualitätsdaten bewertet in ständiger Aktualisierung und Vertrauen, um den Bedürfnissen von Fachleuten und Forschern in den biologischen Bereichen gerecht zu werden.
VERWEISE
ANDELMAN, S. J.; FAGAN, W. F. Umbrellas and flagships: Efficient conservation surrogates or expensive mistakes? Proceedings of the National Academy of Sciences of the United States of America, v. 97, n. 11, p. 5954–5959, 2000.
BISBY, Frank A. The quiet revolution: biodiversity informatics and the internet. Science, v. 289, n. 5488, p. 2309-2312, 2000.
EDWARDS, James L.; LANE, Meredith A.; NIELSEN, Ebbe S. Interoperability of biodiversity databases: biodiversity information on every desktop. Science, v. 289, n. 5488, p. 2312-2314, 2000.
FRAZIER, C.K., WALL, J.; GRANT, S.. Initiating a Natural History CollectionDigitisation Project, version 1.0. Copenhagen: Global Biodiversity Information Facility.75 pp. 2008.
HORTAL, Joaquín; LOBO, Jorge M.; JIMÉNEZ‐VALVERDE, ALBERTO. Limitations of biodiversity databases: case study on seed‐plant diversity in Tenerife, Canary Islands. Conservation Biology, v. 21, n. 3, p. 853-863, 2007.
JAYASIRI, S. C. et al. The Faces of Fungi database: fungal names linked with morphology, phylogeny and human impacts. Fungal Diversity, v. 74, n. 1, p. 3–18, 2015.
JIMÉNEZ-VALVERDE, Alberto et al. Use of niche models in invasive species risk assessments. Biological invasions, v. 13, n. 12, p. 2785-2797, 2011.
LOBO, J. M.; JIMÉNEZ-VALVERDE, A.; HORTAL, J. The uncertain nature of absences and their importance in species distribution modelling. Ecography, v. 33, n. 1, p. 103–114, 2010.
RUA, J. DIGITALIZAÇÃO, PRESERVAÇÃO E ACESSO: contributos para o projeto Museu Digital da U.PORTO. Páginas a&b. S.3, nº especial (2017) 199-229 | DOI 10.21747/21836671/pag2017a13
SOBERÓN, Jorge et al. Assessing completeness of biodiversity databases at different spatial scales. Ecography, v. 30, n. 1, p. 152-160, 2007.
SOBERÓN, Jorge; PETERSON, Townsend. Biodiversity informatics: managing and applying primary biodiversity data. Philosophical Transactions of the Royal Society of London. Series B: Biological Sciences, v. 359, n. 1444, p. 689-698, 2004.
VAIDYA, G.; LOHMAN, D. J.; MEIER, R. SequenceMatrix: Concatenation software for the fast assembly of multi-gene datasets with character set and codon information. Cladistics, v. 27, n. 2, p. 171–180, 2011.
WILSON, Edward O. Systematics and the future of biology. Proceedings of the National Academy of Sciences, v. 102, n. suppl 1, p. 6520-6521, 2005.
[1] Abschluss in Biowissenschaften, Pontifícia Universidade Católica do Paraná (PUC-PR), Paraná, Brasilien. Abschluss in Industrieelektronik, Faculdade de Tecnologia de Curitiba (FATEC) Curitiba, Paraná, Brasilien. Master Student in Information Management, Universidade Federal do Paraná (UFPR), Curitiba, Paraná, Brasilien.
[2] Promotion in Elektrotechnik und Informationstechnik, Universidade Tecnológica Federal do Paraná (UTFPR), Curitiba, Paraná, Brasilien.
Gesendet: September 2020.
Genehmigt: September 2020.