REVISÃO BIBLIOMÉTRICA
TEDESCHI, Victor Hugo Pancera [1], TSUNODA, Denise Fukumi [2]
TEDESCHI, Victor Hugo Pancera. TSUNODA, Denise Fukumi. Banco de dados sobre biodiversidade: Uma análise temporal da produção científica. Revista Científica Multidisciplinar Núcleo do Conhecimento. Ano 05, Ed. 09, Vol. 06, pp. 68-81. Setembro de 2020. ISSN: 2448-0959, Link de acesso: https://www.nucleodoconhecimento.com.br/biologia/producao-cientifica
RESUMO
A presente pesquisa trata sobre bancos de dados de biodiversidade por meio de levantamento bibliográfico no portal de periódicos Scopus, utilizando termos em inglês e limitadores nas palavras-chave, buscando estringir a busca a base de dados. Os documentos foram analisados por meio de bibliometria, no Biblioshiny (um pacote do R). Foram recuperados 352 documentos publicados no período de 1984 a 2020. Por meio das análises observou-se um crescimento das publicações a partir do ano de 2006. Os pesquisadores do Estados Unidos (54) apresentaram o maior número de publicações, enquanto que o Brasil (11) está na sexta posição. Os resultados encontrados nesta pesquisa apontam a tendência em trabalhos sobre o tema, provendo assim um direcionamento para futuras pesquisas.
Palavras-chave: Banco taxonômico, Informática da biodiversidade, Conjunto de dados, Bibliometria.
1. INTRODUÇÃO
A diversidade biológica no planeta é muito alta e algumas estimativas apresentam os valores na casa dos milhões. O Brasil, segundo estimativas conservadoras, abriga 13% da biota mundial. Essa estimativa se dá devido ao Brasil abrigar o maior sistema fluvial do mundo assim como cinco biomas, rendendo ao país o título de “país mega diverso” e contemplando, aproximadamente, 165 mil espécies conhecidas, e a cada dia mais espécies vêm sendo descobertas.
Cada parte descoberta de espécie gera dados de maneira contínua e agregadora sobre suas características (morfologia, nomenclatura, filogenia etc.), hábitos (alimentação, comportamento etc.), distribuição geográfica (avistamentos, registros de coletas etc.), genética (filogenética, sequenciamento de DNA etc.) entre outros.
Toda esta informação necessita ser armazenada de maneira a facilitar o seu acesso e compartilhamento mundial, justificando a necessidade do desenvolvimento e manutenção de bancos de dados que realizem o correto armazenamento destas informações bem como sistemas de recuperação específicos para a área. A partir deste pensamento o objetivo do presente trabalho é explorar, por meio de uma análise bibliométrica, a produção sobre o assunto depositada na base referencial Scopus que indexa títulos acadêmicos revisados por pares, títulos de acesso livre, anais de conferências e publicações comerciais dentre outras.
2. FUNDAMENTAÇÃO TEÓRICA
Banco de dados pode ser definido como uma coleção de dados logicamente coerente que possui um significado, o qual a sua interpretação é dada conforme a aplicação, esta coleção de dados representa abstratamente uma parte do mundo real.
As informações biológicas podem ser divididas em três dimensões, a molecular, organismo e ecossistema (WILSON, 2005), conforme a sua aplicação estas informações são dispostas em três tipos estruturais de bases, que são bases taxonômicas (organismos), as quais tem como foco a apresentação das informações morfológicas das espécies, bases da Informática para Biodiversidade (ecossistema), que possui um caráter transdisciplinar de informações, com o intuito de disponibilizar informações ecológicas e distribuição geográfica, e da Bioinformática (molecular), que por sua vez é voltado para o armazenamento e distribuição de dados moleculares, genes e proteínas.
A informação que alimenta estas bases provém dos processos de digitalização de coleções de museu, relatórios de coleta, lista de alistamentos, extraída de documentos publicados, sequenciamentos de materiais, etc. Os resultados desta digitalização podem ser armazenados ou compartilhados em uma variedade de formatos, como documento de texto, planilhas, páginas da web, base de dados relacionado, mapas ou GIS (Sistema de Informação Geográfica), imagens etc. (FRAZIER; WALL; GRANT, 2008)
A digitalização destes materiais é de vital importância para a preservação e compartilhamento da informação das espécies, mas esta abordagem traz novos desafios, como a confiabilidade dos dados digitalizados, partindo deste ponto, Ruas (2017) destaca a importância da metainformação, que são informações que descrevem estes as informações contida nas base, na curadoria do conteúdo gerado pelos processos de digitalização, a metainformação garante a fidelidade e autenticidade da informação apresentada, assim como a contextualização e que a informação foi capturada.
3. PERCURSO METODOLÓGICO
A escolha dos termos a serem utilizados na presente pesquisa foi realizada por meio de experimentação de diversos conjuntos de palavras e operadores booleanos, na base da Scopus. O fluxo das pesquisas (dos níveis gerais para o específico) e o número de documentos recuperados em cada experimento está apresentado na tabela 1.
Tabela 1 – Conjuntos de palavras e operadores booleanos utilizados na base Scopus e o número de documentos recuperados
| Palavras e operadores | Documentos recuperados |
| ALL ( biodiversity AND database ) | 91.714 |
| ALL ( taxonomy AND database ) | 113.470 |
| ALL ( biodiversity OR taxonomy AND database OR dataset ) | 226.573 |
| ALL ( “biodiversity database” ) | 1.487 |
| ALL ( “biodiversity database” OR “taxonomy database” ) | 2.158 |
| ALL ( “biodiversity database” OR “taxonomy database” ) AND ( LIMIT-TO ( EXACTKEYWORD , “Biodiversity” ) OR LIMIT-TO ( EXACTKEYWORD , “Taxonomy” ) OR LIMIT-TO ( EXACTKEYWORD , “Databases, Genetic” ) OR LIMIT-TO ( EXACTKEYWORD , “Factual Database” ) OR LIMIT-TO ( EXACTKEYWORD , “Data Set” ) OR LIMIT-TO ( EXACTKEYWORD , “Protein Database” ) OR LIMIT-TO ( EXACTKEYWORD , “Databases, Protein” ) OR LIMIT-TO ( EXACTKEYWORD , “Biodiversity Informatics” ) OR LIMIT-TO ( EXACTKEYWORD , “Data Quality” ) ) AND ( EXCLUDE ( SUBJAREA , “IMMU” ) OR EXCLUDE ( SUBJAREA , “MEDI” ) OR EXCLUDE ( SUBJAREA , “NEUR” ) OR EXCLUDE ( SUBJAREA , “PHYS” ) OR EXCLUDE ( SUBJAREA , “PHAR” ) OR EXCLUDE ( SUBJAREA , “ARTS” ) OR EXCLUDE ( SUBJAREA , “VETE” ) OR EXCLUDE ( SUBJAREA , “HEAL” ) OR EXCLUDE ( SUBJAREA , “NURS” ) ) | 723 |
Fonte: Elaborado pelos autores (2020).
Dos resultados encontrados, foram lidos os 100 primeiros documentos, com o intuito de observar se os resultados estavam alinhados à temática abordada na presente pesquisa, assim realizando ajustes nos termos afim de refinar os resultados. Como pode ser observado na Tabela 1, em algumas combinações de termos o número de documentos recuperados variava entre setecentos até mais de 200 mil documentos. Esta etapa foi necessária devido a termos tais como biodiversity e taxonomic serem utilizados em diversos contextos pelos pesquisadores das ciências biológicas.
A estratégia de pesquisa na base Scopus (Elsevier) foi a busca pelos termos em inglês “biodiversity database” e “taxonomic database”, em todos os campos, se utilizou limitador nas palavras-chave selecionando as que possuem relação com a dados, as palavras selecionadas são “Database”, “Data set”, “Data Base”, “database, factual”, “factual database”, “Database Systems”, “data quality” e “data management”, sendo utilizado os resultados obtidos até a data da pesquisa em 28 de junho de 2020. Os parâmetros de consulta com os códigos de campo e operadores, resultou em:

A análise métrica da frequência de palavras (Título, resumo, palavras-chave dos autores, palavras-chave estendidas), da frequência da produção de documentos (países, fontes, autores) e evolução ao longo do tempo (Produção por ano, uso de palavras-chave) foi realizada com a utilização do Biblioshiny (interface gráfica do pacote Bibliometrix, produzido em linguagem R) e do editor de planilhas Microsoft Excel. Foi realizada a exportação dos dados diretamente da base Scopus no formato CSV, compatível com a biblioteca do Biblioshiny para o software R v.3.6.3 e Microsoft Excel 2016.
4. APRESENTAÇÃO E DISCUSSÃO DOS RESULTADOS
A análise compreende os 352 documentos recuperados na busca na base Scopus em 28 de junho de 2020, destes 272 são artigos publicados, 30 anais de conferências e um capítulo de livro. A primeira publicação encontrada referente ao ano 1984. Os 352 documentos recuperados foram escritos por 1.978 autores. Foram identificadas 2.068 palavras-chave estendidas (palavras geradas automaticamente pela base) e 1.033 palavras-chave dos autores.
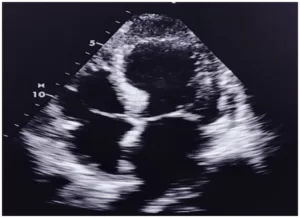
Conforme apresentado no Gráfico 1 observa-se que no intervalo de tempo entre 1984 a 1996, não ocorreu uma produção significativa sobre o tema, após este período é observado um crescimento no número de produções sobre o tema. E observado que em 2017 ocorreu uma oscilação significativa, onde ocorreu uma queda nas produções, e uma retomada no próximo ano. Até o momento desta pesquisa 2020 já apresenta 13 artigos publicados.
Gráfico 1 – Evolução da produção científica na base Scopus de 1984 a 2020
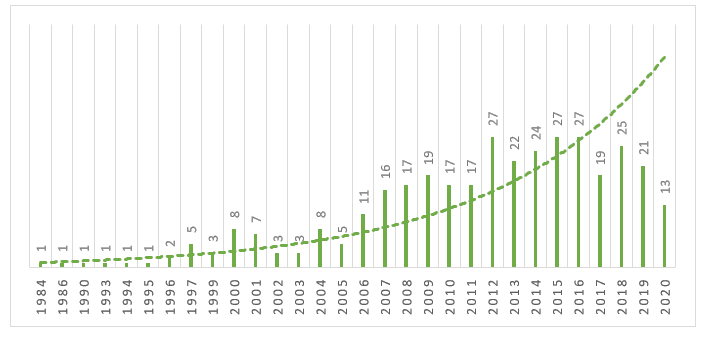
A distribuição dos documentos por países mostra os Estados Unidos da América (54) maior número de publicações nesta área, seguido pelo Reino Unido (32), isso mostra uma predominância de documentos na língua inglesa. Tal resultado pode ter sofrido influência devido a utilização de termos de busca na língua inglesa. Por outro lado, diversos periódicos em diversos idiomas utilizam o abstract como um dos elementos obrigatórios. O Brasil (11) aparece em sexto lugar em número de publicações, conforme demonstra o Gráfico 2.
Gráfico 2 – Contribuição de produção científica no mundo
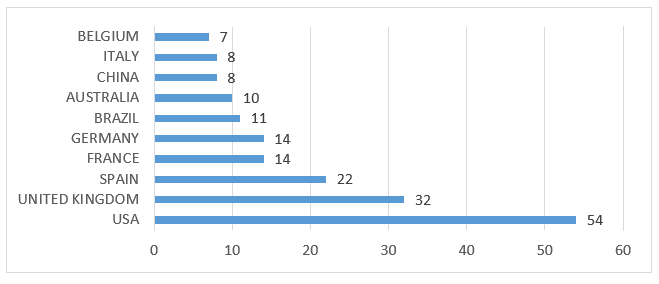
Dentre os 352 documentos recuperados na consulta, a PLOS ONE foi a que apresentou o maior número de artigos publicados, no total de 20, seguido pela Ecological Informatics com 14. Gráfico 3 apresenta as 10 fontes com maior número de publicações.
Gráfico 3 – Fontes com maiores números de produções
Os 10 pesquisadores mais produtivos estão apresentados na tabela 2 e os 10 mais citados na tabela 3. O autor mais produtivo (10) e o mais citado (241) é o doutor Jorge M. Lobo, professor pesquisador do departamento de Biogeography and Global Change do Museo Nacional de Ciencias Naturales, em Madrid, Espanha. O artigo do autor mais referenciado é “Use of niche models in invasive species risk assessments” realizado em coautoria com os pesquisadores A. Jiménez-Valverde, A. T. Peterson, J. Soberón, J. M. Overton e P. Argón, o qual também é o terceiro artigo mais citado (384), apresentado na tabela 4. Este trabalho analisa o uso de dados de localização de espécies para a elaboração de modelos preditivos para o riscos de assentamento de espécies invasoras, em seu trabalho é apresentado também o problema relativo a erros relativamente comuns em grandes séries de dados sobre biodiversidade, como dados de georreferenciamento e identificações errôneas de espécies.
Tabela 2 – Autores mais produtivos
| Autores | Artigos |
| LOBO JM | 10 |
| HORTAL J | 9 |
| PAGE RDM | 7 |
| SOBERóN J | 6 |
| BOOTH TH | 5 |
| COSTELLO MJ | 5 |
| KREFT H | 5 |
| ARIñO AH | 4 |
| GURALNICK R | 4 |
Fonte: Elaborado pelos autores (2020).
Tabela 3 – Autores mais citados
| Autores | Citações |
| LOBO J M | 241 |
| PETERSON A T | 223 |
| HORTAL J | 217 |
| GUISAN A | 132 |
| COSTELLO M J | 117 |
| GRAHAM C H | 114 |
| SOBERÃ N J | 109 |
| FERRIER S | 108 |
| JIMÃ NEZ VALVERDE A | 108 |
Fonte: Elaborado pelos autores (2020).
Os cinco artigos mais referenciados estão listados na tabela 4. O mais citado é o artigo de título “SequenceMatrix: concatenation software for the fast assembly of multi-gene datasets with character set and codon information”, produzido por Vaidya, G., Lohman, D. J. e Meier, R. publicado no ano de 2011. Neste trabalho os autores apresentam o software SequenceMatrix utilizado na análise e associação de múltiplos genes de diferentes datasets, apontando a facilidade de uso como um ponto forte e apresentando as principais funcionalidades do mesmo. O software viabiliza funcionalidades de detecção e correção de erros contidos nos datasets.
Andelman e Fagan (2000) avaliam se o uso de espécies denominadas como “bandeira” ou “guarda-chuva”, são eficientes no uso como substitutos na conservação, pois ao invés de focar na conservação de diversas áreas, o foco fica na conservação destas poucas espécies, que por consequência auxilia na conversação de áreas inteiras. Para testar sua hipótese os autores utilizaram de três bases de dados de diferentes dimensões de abrangência.
Jayasiri et al. (2015) trata em seu artigo da criação de uma base de dados via web, voltada à diversidade de fungos, com o intuito de melhorar a precisão dos nomes científicos, focando na taxonomia. A base conta com 76 curadores especializados nos diversos grupos, garantindo assim confiabilidade nos dados.
Lobo, Jiménez-Valverde e Hortal (2010) tratam dos dados de ausência de espécies em determinadas regiões contidos nas bases de dados, na geração de modelos de distribuição. Realizaram um estudo de caso de uma espécie de besouro que possui a sua distribuição conhecida, com o intuito de demonstrar os possíveis erros da utilização destes dados de ausência e sua importância na modelagem de mapas de distribuição.
Tabela 4 – os cinco artigos mais citados
| Artigos | Total Citações |
| VAIDYA, G.; LOHMAN, D. J.; MEIER, R. SequenceMatrix: Concatenation software for the fast assembly of multi-gene datasets with character set and codon information. Cladistics, v. 27, n. 2, p. 171–180, 2011. | 847 |
| ANDELMAN, S. J.; FAGAN, W. F. Umbrellas and flagships: Efficient conservation surrogates or expensive mistakes? Proceedings of the National Academy of Sciences of the United States of America, v. 97, n. 11, p. 5954–5959, 2000. | 447 |
| JIMÉNEZ-VALVERDE, A. et al. Use of niche models in invasive species risk assessments. Biological Invasions, v. 13, n. 12, p. 2785–2797, 2011. | 384 |
| JAYASIRI, S. C. et al. The Faces of Fungi database: fungal names linked with morphology, phylogeny and human impacts. Fungal Diversity, v. 74, n. 1, p. 3–18, 2015. | 355 |
| LOBO, J. M.; JIMÉNEZ-VALVERDE, A.; HORTAL, J. The uncertain nature of absences and their importance in species distribution modelling. Ecography, v. 33, n. 1, p. 103–114, 2010. | 325 |
Fonte: Elaborado pelos autores (2020).
Os cinco artigos mais citados nos documentos são apresentados na tabela 5. O artigo mais citado nos documentos é “Interoperability of biodiversity databases: biodiversity information on every desktop”, produzido pelos autores Edwards, Lane, e Nielsen e publicado no ano 2000, no artigo e tratado sobre o GBIF, o qual foi criado para facilitar a digitalização dos dados sobre a biodiversidade, e torná-la de libra acesso. No artigo é apresentado sobre o GBIF e as perspectivas futuras dos dados sobre biodiversidade.
Hortal, Lobo e Jiménez‐Valverde (2007) apresentam um estudo de caso sobre as limitações encontradas em bases de dados sobre biodiversidade, com foco em uma base sobre diversidade de sementes e plantas. Em seu trabalho Soberón e Peterson (2004), discutem sobre os potenciais da Informática da Biodiversidade, em sua discussão comentam sobre a aplicação dos métodos na gestão da biodiversidade, e não apenas para estudos fundamentais e compartilhamento de informações. Soberón et al. (2006), em seu artigo demonstram a utilização de dados sobre a biodiversidade presente nas bases para estimar a riqueza e em diferentes resoluções de distribuição geográfica. Bisby (2000) trata em sua pesquisa do surgimento dos grandes sistemas globais de informação biológica.
Tabela 5 – os 5 documentos mais citados nas referências no período
| Documentos citados nas referências | Número de Citações |
| EDWARDS, James L.; LANE, Meredith A.; NIELSEN, Ebbe S. Interoperability of biodiversity databases: biodiversity information on every desktop. Science, v. 289, n. 5488, p. 2312-2314, 2000. | 49 |
| HORTAL, Joaquín; LOBO, Jorge M.; JIMÉNEZ‐VALVERDE, ALBERTO. Limitations of biodiversity databases: case study on seed‐plant diversity in Tenerife, Canary Islands. Conservation Biology, v. 21, n. 3, p. 853-863, 2007. | 37 |
| SOBERÓN, Jorge; PETERSON, Townsend. Biodiversity informatics: managing and applying primary biodiversity data. Philosophical Transactions of the Royal Society of London. Series B: Biological Sciences, v. 359, n. 1444, p. 689-698, 2004. | 34 |
| SOBERÓN, Jorge et al. Assessing completeness of biodiversity databases at different spatial scales. Ecography, v. 30, n. 1, p. 152-160, 2007. | 25 |
| BISBY, Frank A. The quiet revolution: biodiversity informatics and the internet. Science, v. 289, n. 5488, p. 2309-2312, 2000. | 23 |
Fonte: Elaborado pelos autores (2020).
A palavras-chaves mais utilizadas pelos autores Database (49), seguido por biodiversity (32), taxonomy (26), biodiversity informatics (19) e data quality (19), estas frequências das palavras provavelmente foi afetada pela metodologia de seleção dos documentos realizada nesta pesquisa. Na figura 1 apresenta as 50 palavras-chave com maior ocorrência das 1033.
Figura 1 – As 50 palavras-chaves do autor com maior ocorrência

Com relação às palavras-chave estendidas, a palavra mais utilizada é Biodiversity (236), seguido por database (125), Taxonomy (88), dataset (66) e classification (62). E nos resumos as palavras mais frequentes data (1.221), species (856), biodiversity (488), database (315), databases (268). As palavras mais frequentes nos títulos dos documentos são data (113), biodiversity (100), species (68), database (57), databases (44).
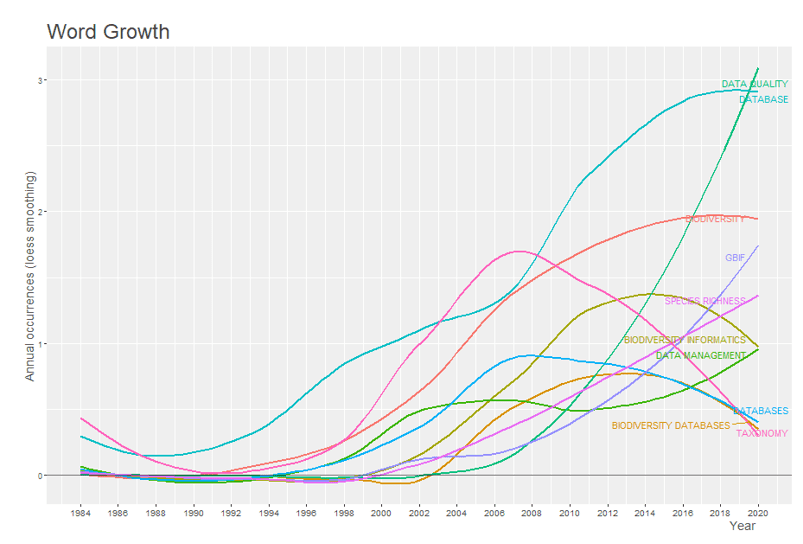
As 10 palavras-chave dos autores de maiores frequências estão representadas de acordo com o número de ocorrências acumuladas ao longo do tempo no gráfico 4. No gráfico é possível observar ainda o crescimento exponencial da palavra data quality, o que pode indicar um aumento no interesse por estudos visando avaliar as informações contidas nas bases de dados existentes, em conjunto a essa palavra e observado o crescimento da palavra GBIF, que corresponde ao Global Biodiversity Information Facility, que é uma rede internacional para o compartilhamento de dados sobre todos os tipos de vida na terra. As palavras database, biodiversity database, databases e biodiversity informatics apresentam queda na utilização nos últimos anos.
Gráfico 4 – Dinâmica das palavras-chaves do autor ao longo do tempo
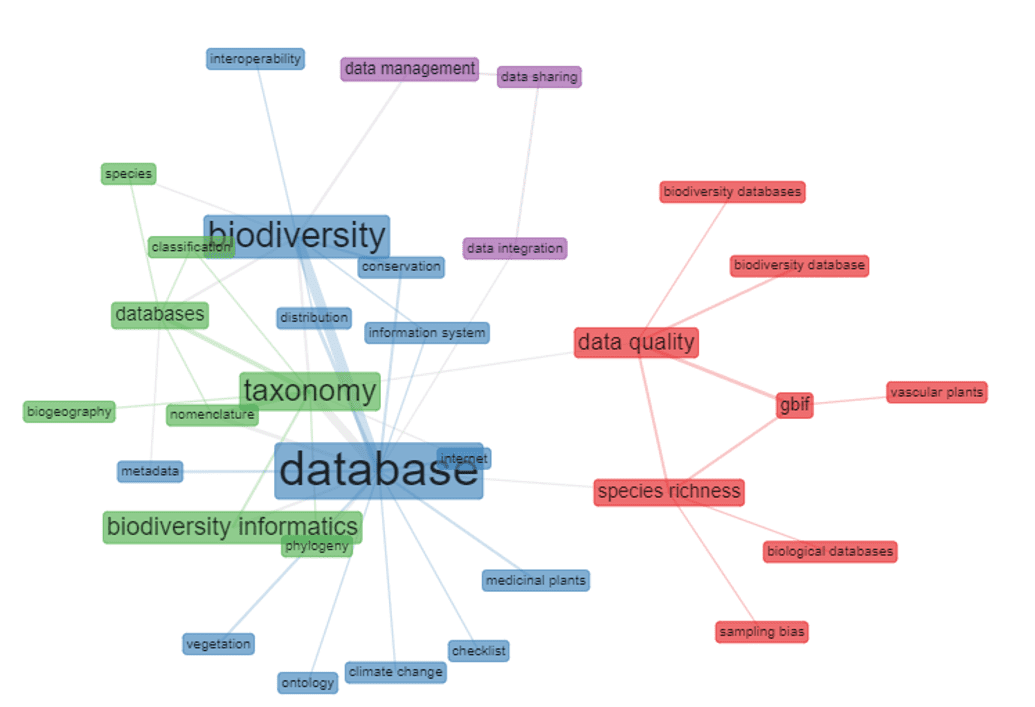
Na análise co-ocorrência das palavras-chave, percebem-se algumas relações: a) database – biodiversity – metadata, internet, information system, distribution, conservation e checklist; b) taxonomy – biodiversity informatics e phylogeny – databases– species, classification, nomenclature e biogeography; c) data quality – species richness – biodiversity databases, biodiversity database, GBIF e biological databases; d) data management, datashring e data integration. É válido destacar as relações apresentadas no conjunto “c”, no qual é possível observar o foco em relação à qualidade dos dados apresentados nas bases, com foco na GBIF. A separação entre o conjunto “a” e “b”, apresenta-se de forma interessante, tornando visível a diferença no foco das pesquisas, onde o conjunto “a” focado na distribuição, conservação e diversidade de espécies, enquanto que o conjunto “b” trata mais da nomenclatura e classificação das espécies. A figura 2 apresenta as relações citadas.
Figura 2 – A co-ocorrência das palavras-chave utilizadas pelos autores
5. CONSIDERAÇÕES PARCIAIS
O presente estudo apresentou a evolução das produções científicas relacionadas às bases de dados em biodiversidade e taxonomia, encontradas na base Scopus. A consulta retornou 352 documentos, distribuídos no período de 1984 a 2020. Observou-se o crescimento das publicações a partir do ano de 2006.
Conforme as informações obtidas através das análises, permitiram visualizar o crescimento das produções e os países que mais produziram sobre o tema, e permitiu apontar as publicações que mais foram citadas referenciadas.
A identificação das palavras-chave mais utilizadas possivelmente foi afetada pela metodologia aplicada nesta pesquisa, uma vez que foram utilizadas nos termos de busca aplicados na base Scopus. Conduto é possível observar um crescimento no interesse nos documentos recuperados relativos à qualidade dos dados encontrados nestas bases.
O presente artigo apresenta a abordagem inicial exploratória sobre bancos de dados relacionados à biodiversidade. Com base nos resultados, no futuro serão melhor exploradas as questões referentes à qualidade dos dados presentes nas bases mais utilizadas, como por exemplo a base GBIF. Outro ponto a ser abordado em futuras pesquisas é a forma de representação das espécies brasileiras nestas bases, e a possibilidade de recuperação destas informações pelos interessados.
A continuidade da pesquisa coaduna com os interesses propostos na dissertação do autor, na qual propõe o desenvolvimento de uma base/portal de livre acesso, que facilite a divulgação de dados sobre diversidade da fauna (animais) brasileira, prezando por dados de qualidade em constante atualização e confiança, para atendimento às necessidades dos profissionais e pesquisadores das áreas biológicas.
REFERÊNCIAS
ANDELMAN, S. J.; FAGAN, W. F. Umbrellas and flagships: Efficient conservation surrogates or expensive mistakes? Proceedings of the National Academy of Sciences of the United States of America, v. 97, n. 11, p. 5954–5959, 2000.
BISBY, Frank A. The quiet revolution: biodiversity informatics and the internet. Science, v. 289, n. 5488, p. 2309-2312, 2000.
EDWARDS, James L.; LANE, Meredith A.; NIELSEN, Ebbe S. Interoperability of biodiversity databases: biodiversity information on every desktop. Science, v. 289, n. 5488, p. 2312-2314, 2000.
FRAZIER, C.K., WALL, J.; GRANT, S.. Initiating a Natural History CollectionDigitisation Project, version 1.0. Copenhagen: Global Biodiversity Information Facility.75 pp. 2008.
HORTAL, Joaquín; LOBO, Jorge M.; JIMÉNEZ‐VALVERDE, ALBERTO. Limitations of biodiversity databases: case study on seed‐plant diversity in Tenerife, Canary Islands. Conservation Biology, v. 21, n. 3, p. 853-863, 2007.
JAYASIRI, S. C. et al. The Faces of Fungi database: fungal names linked with morphology, phylogeny and human impacts. Fungal Diversity, v. 74, n. 1, p. 3–18, 2015.
JIMÉNEZ-VALVERDE, Alberto et al. Use of niche models in invasive species risk assessments. Biological invasions, v. 13, n. 12, p. 2785-2797, 2011.
LOBO, J. M.; JIMÉNEZ-VALVERDE, A.; HORTAL, J. The uncertain nature of absences and their importance in species distribution modelling. Ecography, v. 33, n. 1, p. 103–114, 2010.
RUA, J. DIGITALIZAÇÃO, PRESERVAÇÃO E ACESSO: contributos para o projeto Museu Digital da U.PORTO. Páginas a&b. S.3, nº especial (2017) 199-229 | DOI 10.21747/21836671/pag2017a13
SOBERÓN, Jorge et al. Assessing completeness of biodiversity databases at different spatial scales. Ecography, v. 30, n. 1, p. 152-160, 2007.
SOBERÓN, Jorge; PETERSON, Townsend. Biodiversity informatics: managing and applying primary biodiversity data. Philosophical Transactions of the Royal Society of London. Series B: Biological Sciences, v. 359, n. 1444, p. 689-698, 2004.
VAIDYA, G.; LOHMAN, D. J.; MEIER, R. SequenceMatrix: Concatenation software for the fast assembly of multi-gene datasets with character set and codon information. Cladistics, v. 27, n. 2, p. 171–180, 2011.
WILSON, Edward O. Systematics and the future of biology. Proceedings of the National Academy of Sciences, v. 102, n. suppl 1, p. 6520-6521, 2005.
[1] Graduado em Ciências Biológicas, Pontifícia Universidade Católica do Paraná (PUC-PR), Paraná, Brasil. Graduado em Eletrônica Industrial, Faculdade de Tecnologia de Curitiba (FATEC) Curitiba, Paraná, Brasil. Mestrando em Gestão da Informação, Universidade Federal do Paraná (UFPR), Curitiba, Paraná, Brasil.
[2] Doutorado em Engenharia Elétrica e Informática, Universidade Tecnológica Federal do Paraná (UTFPR), Curitiba, Paraná, Brasil.
Enviado: Setembro, 2020.
Aprovado: Setembro, 2020.