ARTIGO ORIGINAL
LEAL, Helio Gonçalves [1], COSTA, Rogério Homem da [2]
LEAL, Helio Gonçalves. COSTA, Rogério Homem da. Qualidade de dados no Data Warehouse de uma empresa de E-Commerce. Revista Científica Multidisciplinar Núcleo do Conhecimento. Ano 04, Ed. 10, Vol. 06, pp. 49-63. Outubro de 2019. ISSN: 2448-0959, Link de acesso: https://www.nucleodoconhecimento.com.br/tecnologia/qualidade-de-dados
RESUMO
O sucesso da implementação de um Data Warehouse em uma empresa está inextricavelmente ligado a qualidade de dados entregues. Porém para garantir tal qualidade é necessário implementar alguma metodologia que auxilie neste propósito. Neste artigo, discorreremos sobre a metodologia TDQM e como uma estrutura similar a ela foi utilizada em uma empresa brasileira de e-commerce.
Palavras chave: Data Warehouse, qualidade de dados, metodologia, TDQM.
1. INTRODUÇÃO
Os dados gerados nas grandes empresas crescem exponencialmente todos os dias [17]. O volume desses dados é muito alto e sua variedade bem diversificada, sem contar a rapidez com que as informações são geradas [9]. No contexto desse crescimento surge o termo Big Data, que se baseia em três pilares, que são: volume, variedade e velocidade, popularmente conhecidos como os três “Vês” do Big Data. Todavia, outros autores como Taleb, Dssouli e Sherhani [18], falam sobre quatro “Vês” do Big Data e acrescentam a veracidade aos três anteriores. Indo além, autores como Anuradha [1] e Demchenko [5] falam de cinco “Vês”, acrescentando o valor, e outros como Gani [8] chegam até seis “Vês”, incluindo ao conjunto a variabilidade. Para efeito deste trabalho serão considerados os quatro “Vês” apresentados por Taleb, Dssouli e Sherhani [18], que são: volume, variedade e velocidade e veracidade. Quando se trata de projetos de Big Data no contexto de Data Warehouse (DW) e Business Intelligence (BI) a baixa qualidade dos dados pode causar sérios problemas para as empresas, principalmente nos processos de tomada de decisão. Se uma decisão for tomada com base em dados ruins as consequências de tal ação podem ser catastróficas, por isso a total qualidade de gerenciamento dos dados, Total Data Quality Management (TDQM), é imprescindível nessas organizações [12]. Com isto, uma das principais preocupações das empresas, e desafios da área de tecnologia da informação, é a garantia de qualidade dos dados [17].
Nesse sentido, Shankaranarayanan [16] propõe uma estrutura baseada em TDQM que pode ser utilizada em todas as fases que formam o DW. Essa estrutura deve auxiliar o tomador de decisões na análise da qualidade dos dados em todas as fases intermediárias, não somente na fase final. Um outro ponto muito importante nessa estrutura é o entendimento claro das informações de entrada em cada fase do processo, pois em cada fase do processo será efetuada uma verificação de qualidade e a fase sucessora somente iniciará em caso de sucesso da etapa corrente.
Após pesquisas sobre qualidade de dados nos repositórios de trabalhos acadêmicos brasileiros, observou-se que não existem muitos artigos científicos relacionados à qualidade de dados voltados para DW e com solução utilizando o TDQM. Este artigo, portanto, tem como objetivo apresentar um panorama sobre o conceito de gerenciamento de qualidade de dados usando TDQM, bem como discorrer como uma estrutura similar a apresentada por Shankaranarayanan [16] foi aplicada em uma empresa brasileira de e-commerce e por fim, mostrar os resultados obtidos.
2. REFERENCIAL TEÓRICO
2.1 BIG DATA
Para Ticiana [4], o termo “Big Data” representa a prática de coleta e análise de um grande volume de dados, podendo eles serem estruturados ou semiestruturados. Taleb, Dssouli e Sherhani [18] acreditam que o Big Data é imprescindível para obtenção de informações preciosas em grandes volumes de dados, pois auxilia na aquisição, no processamento e em suas análises. Os autores descrevem as características fundamentais do Big Data como os quatro “Vês”, que são: Volume, Velocidade, Variedade e Veracidade. Para Tiago Cruz [7], Volume está ligado ao processamento de uma grande quantidade de dados, Velocidade tem relação com a rapidez com que os dados são processados e variedade tem relação com as diversas fontes diferentes de entrada. Já Veracidade, para Taled [19], descreve que tem ligação direta com a qualidade dos dados que são entregues.
Neste trabalho, a empresa brasileira de e-commerce estudada utiliza como padrão os quatro “Vês” do Big Data, citados anteriormente, em seus processos.
2.2 DATA WAREHOUSE
Segundo Mattioda e Favaretto [14], o primeiro a utilizar o termo Data Warehouse foi Inmon quando propôs, em 1997, ser um DW basicamente um repositório de dados dividido por assuntos (Data Marts), não volátil, integrado e com objetivo de auxiliar na tomada de decisões. Dizem, ainda, que um DW contém informações de diversas e distintas fontes de dados, que podem ser acessadas por meio de um local centralizado e de maneira integrada.
Para se desenhar um DW, alguns autores indicam uma técnica conhecida como Modelagem Dimensional (MD), que, para Hokama [11], visa trazer mais desempenho às consultas realizadas em um DW e trazer informações de maneira mais clara para os usuários. Essa abordagem auxilia também na utilização de ferramentas que usam o processamento analítico online, ou Online Analytical Processing (OLAP), cujo objetivo é o de trazer informações em tempo real para o usuário final. Na modelagem relacional a normalização é uma técnica que possui um grande número de junções e isso torna a consulta mais demorada, já no caso da MD a estratégia é diferente, sendo elencado um assunto principal, conhecido como “fato”, que se traduz nas principais tabelas da MD, elas armazenam as métricas numéricas da empresa. Por exemplo, o assunto “vendas” poderia ser considerado um fato, pois possui valores numéricos de interesse de uma organização, por exemplo: o valor do produto e quantidade de itens comprados. Nesse contexto, para saber, por exemplo, o cliente de uma venda aplicamos o conceito de dimensões, que trata das diferentes perspectivas envolvidas em um fato. No exemplo anterior loja, data, cliente e região poderiam ser consideradas dimensões.
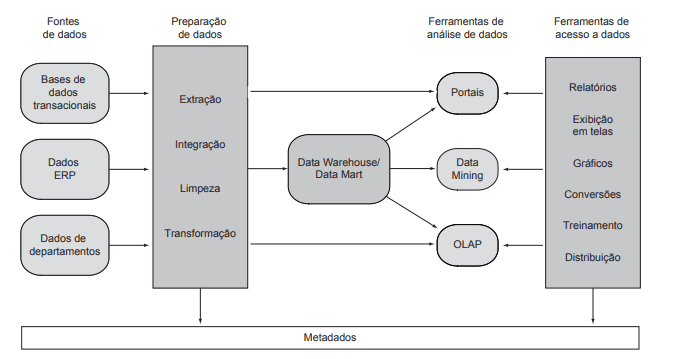
Na Figura 1 é apresentada a arquitetura de um DW e seus cinco componentes principais. O primeiro é a fonte de dados original, ou seja, onde as informações desejadas estão armazenadas; o segundo é a preparação dos dados, onde entra o processo de extração, transformação e carga dos dados, ou Extract, Transform & Load (ETL); o terceiro é o armazenamento dos dados transformados em um DW com a modelagem dimensional aplicada; o quarto é relacionado a ferramenta de análise de dados, que é a maneira como os dados do DW serão consumidos, podendo ser consumidos por um portal, e/ou por meio de Data Mining, e/ou por meio de uma ferramenta de OLAP; o quinto componente compreende as ferramentas de acesso a dados, e corresponde, basicamente à maneira como as informações chegam no usuário final, podendo ser por meio de relatórios, exibição em telas, gráficos, conversões, treinamentos ou distribuição [15].
Figura 1: A arquitetura e processo de um DW.
2.3 PRODUTO DE INFORMAÇÃO (PI)
Shankaranarayanan [16] utiliza o termo Abordagem de Produto de Informação, ou Information Product Approach (IP-Approach), que consiste em determinar as saídas de informação como produtos, para ele um produto de informação, ou Information Product (IP), deve ser considerado como um produto físico, que passa por um processo de armazenamento, coleta, inspeção, processamento e a saída, assim como um produto físico, visto ser uma informação útil ao usuário final. O IP-Approach pode ser gerenciado utilizando metodologias como TDQM
2.4 GERENCIAMENTO TOTAL DE QUALIDADE DE DADOS (TDQM)
Para Norizam e Kamsuriah [12] diversos projetos de DW não dão certo, pois as empresas não se atentam a questão de qualidade de dados e sempre deixam o assunto em segundo plano. Em alguns casos isso ocasionou no insucesso do projeto de DW, pois algumas decisões importantes foram tomadas baseada em dados inconsistentes e o DW acabou perdendo credibilidade, deixando de ser utilizado e por fim, ficando obsoleto. Eles defendem a utilização de TDQM para solucionar problemas de qualidade de dados afim de obter sucesso no projeto de DW.
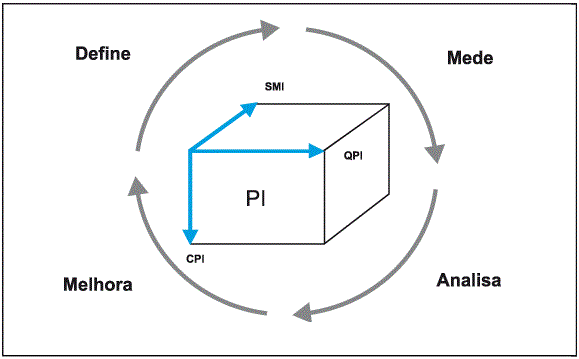
Para Alexandre Costa [2], o sucesso de um DW está diretamente ligado ao sucesso de uma organização e um DW de sucesso possui dados bons. Para que um DW possua dados bons, ele deve implementar alguma metodologia que auxilie no gerenciamento de qualidade de dados. A metodologia utilizada no caso abordado neste artigo é a TDQM, que tem como foco principal a análise de um Produto de informação (PI) e que se assemelha em conceito ao ciclo PDCA – Plan, Do, Check e Act. Pois ambos possuem o conceito de melhoramento contínuo e não possuem um fim. Porém, no TDQM as nomenclaturas são diferenciadas e correspondem a: definir, medir, analisar e melhorar (Figura 2). Na etapa definir, segundo Mattioda e Favaretto [14], são definidas as características do produto de informação (CPI), definidas também as necessidades de qualidade para o produto de informação (QPI) e identificado o sistema de manufatura das informações (SMI); medir consiste da criação de métricas para avaliar a qualidade dos dados; analisar trata da verificação dos resultados e entendimento da origem do problema; e melhorar, etapa final, visa eliminar as causas do problema para que ele não ocorra novamente. A partir daí, retorna-se para a primeira etapa formando assim um modelo iterativo.
Figura 2: Modelo TDQM para melhoria contínua da qualidade dos dados.
3. METODOLOGIA
O método de abordagem utilizado neste artigo foi um estudo de caso e teve como intuito observar, acompanhar e apresentar como uma empresa brasileira de grande porte na área de e-commerce trabalha a qualidade de dados em seu DW, utilizando um conceito similar ao de TDQM.
A pesquisa utilizada foi a descritiva e as coletas de dados foram feitas por meio de entrevistas, observações e acompanhamento.
As etapas para seleção da amostra e aplicação da pesquisa foram:
1. Identificar uma empresa que tenha implementado um DW e que tenha os seguintes pré-requisitos: elevado grau de informatização, tempo de implementação do DW de no mínimo dois anos e número de usuários acima de cinquenta.
2. Visitar a empresa, para o levantamento dos itens a serem analisados e coleta de informações com os usuários, um dos principais objetivos deste tópico é encontrar o produto de informação a ser analisado na pesquisa, bem como suas características vindo de encontro ao passo “definir” do TDQM.
3. Determinar junto a um ou mais usuários, duas dimensões para serem medidas e como o acompanhamento delas será feito – este passo vem de encontro à etapa “medir” do TDQM.
4. Observar e acompanhar as dimensões no período dezesseis semanas e verificar as correções e melhorias aplicadas – este passo vem de encontro as etapas “analisar” e “melhoria”, respectivamente, do TDQM.
5. Apresentar as informações coletadas.
6. Redigir o relatório final.
3.1 ESTUDO DE CASO
A partir de uma conversa com um gerente na área de Business Intelligence da empresa, identificou-se que os pré-requisitos: elevado grau de informatização, tempo de implementação do DW de no mínimo dois anos e número de usuários acima de cinquenta, foram atendidos. Solicitou-se ao gerente a possibilidade de efetuar o estudo, e apresentar os resultados. A solicitação foi aceita. A empresa é atuante no mercado há mais de cinco anos e como dito anteriormente, é uma empresa brasileira da área de e-commerce, com diversos escritórios na América Latina.
Após a definição inicial, foi feita uma visita a empresa e efetuadas algumas entrevistas com usuários e donos das ferramentas com o intuito de coletar informações para a pesquisa, as entrevistas são apresentadas na tabela 1.
Tabela 1: Usuários entrevistados.
| Área | Função | Indagação |
| BI | Analista de DW Júnior | Levantar informações sobre o DW e como é feito o acompanhamento e controle da qualidade de dados, bem como quais ferramentas são utilizadas. |
| BI | Especialista de DW | Mesma do de cima com o intuito de complementar as informações obtidas. |
| BI | Gerente de BI | Identificar como entrega os dados e principais relatórios. |
| Marketing | Gerente de Marketing | Identificar como usa os dados e principais relatórios. |
Fonte: Elaborada pelo autor.
As informações extraídas com base nas entrevistas com o Gerente de BI e Gerente de Marketing, foi que o principal relatório utilizado na empresa trata de um relatório que contém as vendas e investimentos de marketing do mês, iniciando no primeiro dia útil do mês corrente até o dia atual menos 1 dia, ou ainda d-1. O relatório é gerado com base em processos cujas origens dos dados são diversas (para dados sobre vendas, são coletados dados do ERP da empresa, do sistema de vendas online entre outros. E para investimentos de marketing são coletados dados de redes sociais como Facebook, Instragram e sites de busca, como por exemplo Google), contendo dados estruturados e semiestruturados, e que possui grande volume de dados vindouros dessas fontes. Este relatório é considerado de extrema importância para a empresa e que deve ser entregue antes do início do expediente e que as informações contidas nele devem ser confiáveis. Devido à relevância deste relatório para empresa, ele foi escolhido como PI para ser acompanhado.
Uma entrevista foi realizada com um analista de DW Júnior e um especialista de DW, e após conversa, foi levantado que o DW da empresa conta com mais de 40 fontes de dados de origem distintas e contém mais de 15 Data Marts. Foi verificado também que o DW da empresa conta com uma estrutura de componentes similar à citada neste artigo por Mattioda e Favaretto [14]. O primeiro componente são as fontes de dados originais, onde os dados ali contidos, são uma cópia da origem, na empresa esse componente é popularmente conhecido como camada Raw. Depois tem o processo de integração de fontes distintas e padronização de alguns termos, na empresa esse componente é popularmente conhecido como camada Integration. Por fim, temos a camada onde a modelagem dimensional é aplicada, na empresa esse componente é popularmente conhecido como camada Business.
Outro levantamento junto ao analista de DW Júnior e o especialista de DW foi sobre as ferramentas utilizadas por eles. A equipe utiliza basicamente três ferramentas para acompanhar e controlar o carregamento dos dados para o DW, essas ferramentas, cujos nomes, funções e tipos de licenças de uso, são listadas na tabela 2.
Tabela 2: Ferramentas.
| Ferramenta | Função | Licença |
| Jenkins | O Jenkins é um servidor que pode ser usado para automatizar vários tipos de tarefas como construção, testes e entrega contínua de Software [13]. | Open Source |
| Hanger | O Hanger é uma ferramenta gráfica que é utilizada como plugin do Jenkins, ela é utilizada para controlar as dependências de um determinado assunto, bem como pode ser utilizada para qualidade de dados por meio de verificações em determinadas partes do processo [10]. | Open Source |
| Data Integration – Kettle | O Kettle é uma ferramenta desenvolvida pela empresa Hitachi e tem serve para o desenvolvimento de processo de ETL. [3] | Open Source |
Fonte: Elaborada pelo autor.
4. RESULTADOS
Este estudo acompanhou a aplicação do TDQM em dois ciclos para os dois principais problemas do relatório de vendas e investimentos de marketing e os resultados obtidos são apresentados nesse capítulo.
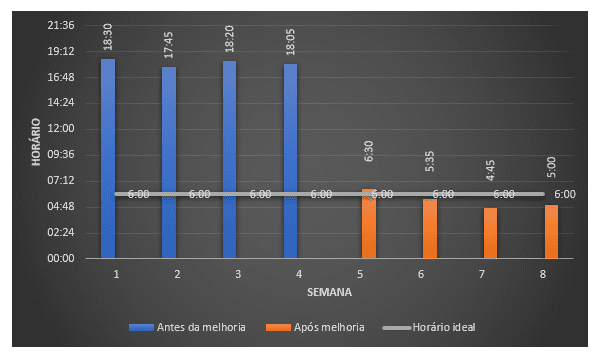
No primeiro ciclo, foi definido que o horário de entrega do PI deveria ser acompanhado. A medição deste problema foi feita com base no horário de entrega final do relatório no dia corrente. Na etapa de análise foi feito acompanhamento de quatro semanas, e, notou-se que o relatório estava sendo entregue na maioria das vezes no final do horário de expediente, pois havia diversos problemas relacionados as dependências atreladas ao PI e que havia grande dificuldade em rastrear quais eram as dependências com problemas, isso ocasionava lentidão até que o relatório fosse gerado por completo. Após essa análise, na etapa de melhoria, foi feito um trabalho pela equipe de BI que foi, em primeira instância, mapear as dependências do Data Mart de vendas e, a partir daí, cadastrar todas essas dependências na ferramenta Hanger para que ela possa efetuar o controle das cargas até a entrega do PI. Após aplicação desta melhoria, notou-se, após acompanhamento de quatro semanas, que o relatório de vendas passou a ser entregue na maioria das vezes, antes do início do expediente, e quando ocorria erro em alguma das dependências, era muito mais fácil identificar onde ocorreu o problema, ou seja, qual foi o ponto específico onde ocorreu falha.
Gráfico 1: Horário de entrega do PI.
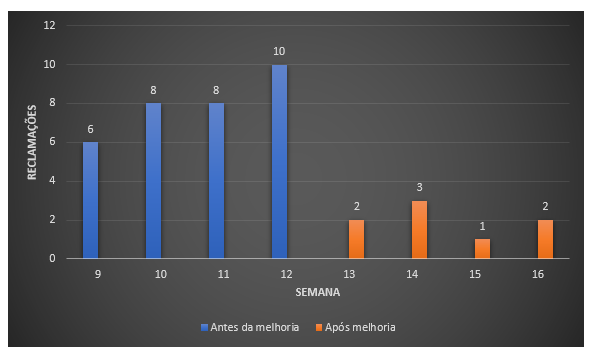
No segundo ciclo, foi definido que a veracidade dos dados do PI deveria ser acompanhada. Os dados gerados devem ser fiéis ao valor real de vendas efetuadas e os investimentos de marketing devem estar corretos. Na etapa de análise foi feito acompanhamento de quatro semanas, e, notou-se reclamações constantes dos usuários finais sobre números incorretos apresentados no relatório (média de oito reclamações por semana), um exemplo desses números incorretos é o valor total de vendas realizado em D-1 e/ou o custo de marketing gasto pela empresa em D-1. Os usuários que desconfiavam dos números, efetuavam consultas para saber se o número estava correto direto na fonte de dados de origem. Após essa análise, na etapa de melhoria, foi feito um trabalho pela equipe de BI que consiste em efetuar uma verificação em cada um dos componentes que formam o DW, essa verificação vem de encontro com a estrutura proposta por Shankaranarayanan [16]. Essa verificação foi feita utilizando a ferramenta Hanger e teve como objetivo colocar, basicamente, uma contagem comparando a fase anterior com a fase atual e se o número estiver divergente, um alerta é enviado ao e-mail da equipe de BI e assim, os analistas podem efetuar a verificação e correção de uma possível inconsistência. Em alguns casos foi adicionado uma ação automática disponível na própria ferramenta Hanger que se refere basicamente se alguma validação falhar, o processo anterior é rodado novamente com o intuito de corrigir o problema automaticamente. Após aplicação dessa melhoria, notou-se, após acompanhamento de quatro semanas, que as reclamações de números incorretos diminuíram de forma considerável (média de duas reclamações por semana) pois quando algo estava fora do correto, era possível para os analistas de BI saberem de antemão que algo não estava correto e em alguns casos o problema era corrigido automaticamente pela própria ferramenta.
Gráfico 2: Reclamações por semana.
5. CONCLUSÃO
Como pode ser mostrado neste artigo, a adoção de uma metodologia aplicada à melhoria da qualidade de dados em projetos de DW, é positiva para que se obtenha sucesso na implementação deste tipo de projeto. Para tanto, o presente estudo acompanhou a equipe de BI de uma empresa brasileira de e-commerce com o intuito de observar, acompanhar e descrever como a metodologia TDQM é utilizada no cotidiano da equipe de BI e como eles controlam a qualidade de dados em seu DW.
Quando indagado, o gerente de BI, disse que após a utilização dos conceitos do TDQM e a implementação das ferramentas citadas, principalmente o Hanger, a empresa obteve mais qualidade nos dados entregues e redução das reclamações advindas dos usuários, consequentemente, teve mais credibilidade com as áreas de negócio da empresa. Ainda que não tenha sido objeto deste estudo, pode-se observar reflexos positivos também nos custos de produção da informação, visto que menos esforços manuais passaram a ser aplicados na produção desta informação, assim como reduziu-se o número de reclamações sobre a qualidade da informação contida no relatório e também processos obsoletos, que foram excluídos. Reduções estas, que, se medidas e expressas em quantidade de homens/hora poderiam, certamente, revelar números significativos para os gestores empresariais contribuindo para o reforço das vantagens da aplicação da metodologia estudada.
Por fim, concluímos que a utilização de metodologias para acompanhar a qualidade de dados em um DW como TDQM e ferramentas, como as citadas neste artigo ou similares, pode auxiliar empresas a enxergarem pontos de melhoria e gargalos em todos os componentes do DW e auxiliar na correção categórica dos processos.
6. REFERÊNCIAS
1. ANURADHA, J. et al. A brief introduction on Big Data 5Vs characteristics and Hadoop technology. Procedia computer science, v. 48, p. 319-324, 2015.
2. COSTA, Alexandre Manuel Pereira Mendes da. A gestão da qualidade dos dados em ambientes de data warehousing na prossecução da excelência da informação. 2006. Tese de Doutorado.
3. Data Integration – Kettle. Disponível em: https://community.hitachivantara.com/s/article/data-integration-kettle. Acesso em: 23 de set. 2019.
4. DA SILVA, Ticiana LC et al. Análise em Big Data e um Estudo de Caso utilizando Ambientes de Computação em Nuvem. 2013.
5. DEMCHENKO, Yuri et al. Addressing big data issues in scientific data infrastructure. In: Collaboration Technologies and Systems (CTS), 2013 International Conference on. IEEE, 2013. p. 48-55.
6. FAVARETTO, Fábio. Experimento para análise da implantação da medição da qualidade da informação. Associação Brasileira de Engenharia de Produção, v. 17, n. 1, 2007.
7. FRANÇA, Tiago Cruz et al. Big Social Data: princípios sobre coleta, tratamento e análise de dados sociais. XXIX Simpósio Brasileiro de Banco de Dados–SBBD, v. 14, 2014.
8. GANI, Abdullah et al. A survey on indexing techniques for big data: taxonomy and performance evaluation. Knowledge and information systems, v. 46, n. 2, p. 241-284, 2016.
9. GAO, Jerry; XIE, Chunli; TAO, Chuanqi. Big Data Validation and Quality Assurance–Issuses, Challenges, and Needs. In: 2016 IEEE symposium on service-oriented system engineering (SOSE). IEEE, 2016. p. 433-441.
10. Hanger. A graphical tool for ETL process orchestration and data quality. Disponível em: <https://github.com/dafiti-group/hanger>. Acesso em: 23 de set. de 2019.
11. HOKAMA, Daniele Del Bianco et al. A modelagem de dados no ambiente Data Warehouse. São Paulo, p. 32, 2004.
12. IDRIS, Norizam; AHMAD, Kamsuriah. Managing Data Source quality for data warehouse in manufacturing services. In: Electrical Engineering and Informatics (ICEEI), 2011 International Conference on. IEEE, 2011. p. 1-6.
13. Jenkins User Documentation. Open source automation server which can be used to automate all sorts of tasks related to building, testing, and delivering or deploying software. Disponível em: <https://jenkins.io/doc/>. Acesso em: 23 de set. de 2019.
14. MATTIODA, R. A.; FAVARETTO, F. Qualidade da Informação em Duas Empresas que Utilizam Data Warehouse na Perspectiva do Consumidor de Informação–um estudo de caso. Universidade Federal do Paraná, 2009.
15. SANTOS, Ricardo S. et al. Data Warehouse para a saúde pública: estudo de caso SES-SP. In: Anais do X Congresso Brasileiro de Informática em Saúde. 2006. p. 53-58.
16. SHANKARANARAYANAN, G. Towards implementing total data quality management in a data warehouse. Journal of Information Technology Management, v. 16, n. 1, p. 21-30, 2005.
17. SIDI, Fatimah et al. Data quality comparative model for data warehouse. In: Information Retrieval & Knowledge Management (CAMP), 2012 International Conference on. IEEE, 2012. p. 268-272.
18. TALEB, Ikbal; DSSOULI, Rachida; SERHANI, Mohamed Adel. Big data pre-processing: a quality framework. In: Big Data (BigData Congress), 2015 IEEE International Congress on. IEEE, 2015. p. 191-198.
19. TALEB, Ikbal et al. Big data quality: A quality dimensions evaluation. In: 2016 Intl IEEE Conferences on Ubiquitous Intelligence & Computing, Advanced and Trusted Computing, Scalable Computing and Communications, Cloud and Big Data Computing, Internet of People, and Smart World Congress (UIC/ATC/ScalCom/CBDCom/IoP/SmartWorld). IEEE, 2016. p. 759-765.
[1] Tecnólogo em Análise e Desenvolvimento de Sistemas pelo IFSP – campus Guarulhos e cursando especialização em Gestão de Sistemas de Informação no IFSP – campus Guarulhos.
[2] Especialista em Administração de Sistemas de Informação pela Universidade Federal de Lavras, UFLA.
Enviado: Outubro, 2019.
Aprovado: Outubro, 2019.
