CARVALHO, Valter Pereira de [1], DA SILVA, Leandro Augusto [2]
CARVALHO, Valter Pereira de. Previsão de Vendas no Varejo Através de Rede Neural. Revista Científica Multidisciplinar Núcleo do Conhecimento. Ano 03, Ed. 05, Vol. 03, pp. 131-149, Maio de 2018. ISSN:2448-0959
RESUMO
Esse artigo de caráter multidisciplinar, envolvendo as áreas de Marketing, Economia e Computação, tem por objetivo mostrar como as técnicas de Data Mining (mineração de dados) são importantes quando aplicadas nas atividades do varejo e no caso aqui analisado mostraremos como utilizar a rede neural artificial para prever as vendas futuras com base em um aprendizado fundado em dados históricos de vendas. O uso das redes neurais, diverso dos processos de regressão linear e regressão múltipla, oferece a condição de responder de forma bastante eficiente às séries temporais com pontos de grande alteração no comportamento dos dados (não linearidade). Esse processo é bastante útil tanto na implementação de processos de compras, como nas ações de marketing e gestão de caixa, pois os resultados são bem próximos do real e fornece uma informação muito útil para a empresa como um todo. Logicamente que se trata de um artigo que não busca esgotar o assunto, mas sim fornecer um caminho alternativo para essa implementação e fornecendo fundamentos que serão uteis nas melhorias que se seguirem.
Palavras-chave: Rede Neural, Previsão de Vendas, Marketing, Data Mining, Mineração de Dados.
1. INTRODUÇÃO
A administração de empresas nas áreas de gestão de compras, gestão de custos, gestão de estoque, gestão de logística e gestão financeira, percebe-se que praticamente toda a organização, sempre foi preocupada com os resultados das áreas de marketing e vendas, buscando fórmulas que consigam lhes dar algum subsídio eficiente para suprir as demandas dessas áreas e manter as atividades de vendas sempre em condições de atendimento aos clientes.
Buscar previsões de vendas em período futuro sempre figurou como o grande “sonho de todas as organizações”, pois não errando no abastecimento, seja para mais como para menos, é condição necessária para garantir uma boa operação da empresa. Para isso as empresas sempre se valeram de áreas de planejamentos onde equipes multidisciplinares formadas por matemáticos, estatísticos, contadores e gestores de lojas se debruçavam sobre anotações de vendas e metas a serem atingidas para minimizar os problemas de abastecimentos e distribuições.
Com o desenvolvimento da tecnologia e o barateamento, até certo ponto, dos sistemas integrados de softwares conhecidos como ERP (Enterprise Resources Planning – Sistema de Gestão Empresarial) que tem o propósito de gerenciar todas as operações da empresa e os CRM (Customer Relationship Management – Gestão de Relacionamento com Clientes) com propósito de manter um histórico de todos os relacionamentos da organização com os seus clientes – as empresas passaram a ter um conjunto enorme de dados sobre suas operações, elementos esses que se bem analisados podem fornecer inúmeros subsídios para melhoria de suas operações negociais.
Com o grande avanço da capacidade de processamento dos computadores nos últimos anos e o seu fácil acesso, houve um grande impulso para os profissionais passarem a intensificar o uso de métodos quantitativos em Administração, fazendo crescer nas empresas o número de suas aplicações e a distribuição das tarefas em razão da capacidade de distribuição do processamento de dados (BERRY e LINOFF, 1997; GARGANO e RAGGAD, 1999). Dessa feita o momento é de especializar os processos de busca do conhecimento com base em dados e assim precisar ainda mais as operações.
2. MINERAÇÃO DE DADOS (DATA MINING)
O advento da microeletrônica e a chegada da computação pessoal deu novo impulso ao conhecimento humano, tal qual ocorreu com a escrita, com o papel e com a imprensa em períodos remotos. A utilização da computação digital é hoje parte integrante e praticamente indissociável da vida do ser humano seja em qualquer em de suas áreas de atividades. A captura e o armazenamento de dados é hoje o grande mote de nossa civilização, os dados são capturados por sensores, digitados em computadores e smartphones, obtidos por áudio, vídeo e mesmo digitalização de documentos e livros. O poder computacional que um cidadão carrega hoje no bolso é algo inimaginável há cinquenta anos atrás e a sua capacidade de comunicação a mesma coisa.
A todo momento milhões e milhões de bits de dados são gerados em algum lugar e armazenados em servidores espalhados ao longo do planeta o que vem a formar um grande universo de dados, conhecido como Big Data. Explorar esses dados de forma inteligente, desvendando suas relações e transformando-os em informação é a grande tarefa dos profissionais denominados cientistas de dados (data scientists).
Dentre as várias atividades do cientista de dados está a da mineração de dados, do inglês data mining, que consiste na descoberta do conhecimento nessas grandes bases de dados. O conhecimento pode ser extraído diretamente de um banco de dados ou a partir de um armazém de dados, denominado de Data Warehouse (Elmasri e Navathe, 2002). Para essa extração, são necessárias ferramentas de exploração que podem incorporar técnicas estatísticas e/ou de inteligência artificial, capazes de fornecer respostas as várias questões ou descobrir novos conhecimentos (Romão et al., 2005).
O termo data mining é muito usado por estatísticos, pesquisadores de banco de dados e comunidades de negócio, constituindo uma das ferramentas mais utilizadas para extração de conhecimento ou informações relevantes, a partir de bancos de dados, nos meios comercial ou científico (“Data mining overview”, 2005; Silberschatz, 1999; Elmasri e Navathe, 2002). Esse termo, a partir do tratamento de grandes quantidades de dados armazenados diretamente em repositórios e por meio da utilização de tecnologias baseadas em ferramentas quantitativas de reconhecimento de padrões, refere-se ao processo de descobrimento de correlações significativas, padrões, tendências, associações e anomalias. Portanto, busca-se, de maneira automática, descobrir regras e modelos estatísticos a partir dos dados (“Data mining overview”, 2005; Silberschatz, 1999; Elmasri e Navathe, 2002; Grupo Gartner, citado por Larose, 2005).
Alguns autores e vamos segui-los nesse trabalho, exploraram a previsão de venda de produtos de maneira individualizada, a partir de séries históricas das vendas de cada produto (BARASH e MITCHELL, 1998; GORDON, 1998; ALIBAIG e LILLY, 1999). Esses estudos
utilizaram técnicas de modelagem de séries temporais, tomando como entrada dos modelos os valores históricos das vendas de cada produto no tempo, e construíram um modelo distinto para a previsão de vendas de cada produto. Esse processo será tomado por objetivo uma vez que o propósito desse trabalho é o de mostrar de forma simplificada a possibilidade de ser obter bons resultados de previsão considerando apenas o comportamento das vendas, todavia, caso haja o desejo de refinar o modelo outras variáveis que tem impacto direto sobre as vendas poderão serem consideradas, tais como: investimento em publicidade digital em sites de buscas como Google e redes sociais como o Facebook, logicamente que esses investimentos tem impacto relevante e o trabalho pode inclusive ser estendido para a determinação do melhor momento para o uso de tais verbas em campanhas de marketing. Portanto, esse trabalho apenas abre um horizonte e não tem o condão mínimo de buscar esgotar o assunto.
2.1 EXEMPLOS DE USOS DA MINERAÇÃO
Já nos anos 80 a rede de supermercados americana Wal-Mart fazia uso de data mining em servidores de data warehouse para acompanhar os perfis de compras de seus clientes que tinham cadastro no plano de fidelidade da rede Sams Club. No cruzamento da compra atual do cliente com o seu padrão e das paridades de produtos adquiridos costumeiramente os operadores de caixas tinham meios de ofertar produtos que o cliente eventualmente estivesse esquecendo de comprar.
Hoje a rede Wal-Mart é conhecida tanto por sua política de baixos níveis de estoque e ressuprimento constante de produtos (baixos lotes e alta freqüência), como por sua política agressiva com os concorrentes regionais. Utilizando ferramentas de data mining, que auxiliam na previsão de cada item transacionado nas lojas da empresa, essa empresa modificou seus sistemas de ressuprimento automático de produtos. Além disso, identificou padrões de consumo, em cada loja, para a escolha do mix de produtos a ser ofertado (Rodrigues, 2005), Destaca-se inclusive contabilmente suas operações por operar com níveis mínimos mas suficientes de estoque.
Um outro caso de sucesso é o do Banco Itaú que costumava enviar mais de um milhão de malas diretas aos correntistas, com uma taxa de resposta de apenas 2%. Com um banco de dados contendo as movimentações financeiras de seus milhões de clientes, durante 18 meses, e utilizando ferramentas de data mining, conseguiu reduzir em um quinto a conta com despesas postais e, ainda, aumentou sua taxa de resposta para 30% (Rodrigues, 2005);
Importante considerar como exemplo de mineração de dados os trabalhos realizados nas empresas de comércio eletrônico, iniciados pela Amazon, que com base no histórico de compras de clientes utilizam a relação entre os produtos para no momento da compra de um deles por um novo cliente, possa sugerir os demais. Temos aqui uma sugestão de venda cruzada onde um produto tem sua venda associada a venda de outros para um mesmo cliente. Sem o cruzamento de dados e um processo específico de mineração essas alavancagens de vendas não seria possível.
Com o advento das redes sociais as empresas estão criando áreas de inteligência de dados contratando cientistas de dados para atividades de busca de conhecimento e novas oportunidades de negócios juntos aos clientes antigos e prospecção de novos. Em tempo curto nenhuma ação de marketing será tomada sem que se receba resultados de estudos realizados com data mining.
3. O PROCESSO DE PREVISÃO DE VENDAS
A previsão de vendas é uma estimativa de quanto será a receita da empresa em determinado período de tempo. Esta informação auxilia os gestores a fazer planejamentos e identificar onde é preciso melhorar e investir. A previsão de vendas é uma importante aliada para empresas que buscam consolidação no mercado.
Uma projeção de vendas tem como intuito nortear a empresa para que a mesma tenha um crescimento escalável e sustentável em determinado período de tempo.
De forma prática, imagine que você queira triplicar o faturamento da sua empresa no próximo ano. Para isso você vai precisar montar uma projeção de vendas que possibilite tal aumento, e mais importante, definir as ações que irão possibilitar que isso ocorra.
É importante ressaltar que a projeção de vendas está completamente ligada com o setor comercial e a atual situação da empresa. Por isso é importante que tais projeções sejam realistas e que reflitam a capacidade de venda do seu produto/serviço.
3.1 TIPOS DE PREVISÃO DE VENDAS
- ) Previsão baseada em margem de contribuição
Este tipo de previsão de vendas deve ser feito em conjunto com outros métodos, por ser voltada para cenários gerais. Antes de fazer este tipo de previsão, calcule a margem de contribuição e o ponto de equilíbrio.
- ) Previsão baseada em mercado
Se o seu volume de vendas é afetado pela sazonalidade, esta é a previsão mais indicada para o seu negócio. Para fazê-la, é preciso se basear em um negócio da mesma área de atuação, que seja localizado próximo ao seu e que seja semelhante ao seu.
- ) Previsão baseada em experiências passadas
Se para você o melhor é fazer projeções com base em suas próprias experiências, então esta é a previsão mais indicada para a sua empresa. Para cada mês, destaque uma ação realizada que influenciou no resultado. Analise se o resultado foi positivo ou negativo. Um lembrete: para fazer este tipo de previsão, sua empresa precisa ter, no mínimo, seis meses de vida.
3.2 VANTAGENS DA PREVISÃO DE VENDAS
Empresas que fazem previsão de vendas conseguem ter uma visão real do próprio negócio, evitando otimismo excessivo e estagnação da organização. Além disso, a previsão de vendas dá um melhor direcionamento aos investimentos que devem ser feitos, já que o gestor sabe o que trouxe resultados positivos e o que precisa ser melhorado. Com as informações obtidas por meio dessa projeção, o gestor também se torna capaz de adaptar as estratégias e planejar campanhas específicas para determinados períodos, aumentando suas vendas com assertividade.
4. ANÁLISE DOS DADOS HISTÓRICOS DE VENDAS
Os dados históricos das operações de vendas de uma empresa empiricamente permite que se conheça o comportamento dos seus clientes. A análise dos pedidos com mais de um item comprados permitem análises de referências cruzadas da demanda, quando é possível identificar o quanto os preços ofertados por um produto implicam na demanda de outros. Essa relação será utilizada nos experimentos para a determinação da previsão nesse trabalho.
4.1 MIX DE MARKETING DE KOTLER
Um dos conceitos mais famosos quando estudamos Publicidade e Marketing é o Mix de Marketing, criado pelo professor Jerome McCarthy e difundido por Philip Kotler. Quem já estudou o assunto provavelmente dedicou uma parcela do seu tempo para ter na ponta da língua o significado dos 4 Ps do Marketing: Produto, Preço, Praça e Promoção — em inglês: Product, Price, Placement, Promotion.
Dos quatro elementos citados inúmeras variáveis podem interferir diretamente nas vendas de uma empresa, nesse trabalho considera-se que os quatro elementos serão mantidos constantes entre os períodos de treinamento e da previsão, desta forma esse estudo estará se baseando exclusivamente nas vendas históricas, não havendo nenhuma outra circunstância a ser considerada, ou como se diz na economia: Ceteris paribus que é usada para fazer uma análise de mercado da influência de um fator sobre outro, sem que as demais variáveis sofram alterações).
5. A REDE NEURAL
51. CONCEITO DE REDES NEURAIS ARTIFICIAIS (RNA)
Em sua obra ??, p.24) afirma que rede neural é um processador maciçamente paralelamente distribuído, constituído de unidades de processamento simples, que têm a propensão natural para armazenar conhecimento experimental e torná-lo disponível para uso. Ela assemelha- se ao cérebro em dois aspectos: (1) o conhecimento é adquirido pela rede a partir de seu ambiente através de um processo de aprendizagem; (2) forças de conexão entre neurônios (os pesos sinápticos) são utilizadas para armazenar o conhecimento adquirido.
A base de uma rede neural são os neurônios artificiais que “copiam” ou “simulam” o funcionamento dos neurônios biológicos de um cérebro humano. Por analogia, as entradas (inputs) para os neurônios chegam através dos dendritos, esses por sua vez também podem agir como saídas (outputs) interconectando os outros neurônios. Matematicamente, por analogia os dendritos seriam o somatório. Os axônios, por outro lado, são encontrados somente nas células de saída, cuja função sináptica e quando ativos transmitem um sinal elétrico. São responsáveis também por conectar os demais neurônios através de seus dendritos.
A característica mais relevante do uso das Redes Neurais é a capacidade de aprendizado por meio de exemplos, no qual a rede consiste de um processo iterativo de ajuste de parâmetros e está relacionado com a melhoria do desempenho da rede, sendo que o erro deve diminuir na medida em que o aprendizado prossiga. A Rede Neural possui duas fases de processamento, a de aprendizado e a de utilização ou aplicação e ambas as fases são distintas e ocorrem em momentos diferentes.
5.2 ESTRUTURA DAS REDES NEURAIS ARTIFICIAIS
As redes neurais artificiais são criadas a partir de algoritmos projetados para uma deter- minada finalidade. É impossível criar um algoritmo que aprende com base em exemplos sem ter conhecimentos de modelos matemáticos que simulem o processo de aprendizado do cérebro humano. Basicamente, uma rede neural se assemelha ao cérebro em dois pontos: o conhecimento é obtido através de etapas de aprendizagem e pesos sinápticos são usados para armazenar o conhecimento.
Uma sinapse é o nome dado à conexão existente entre neurônios. Nas conexões são atribuídos valores, que são chamados de pesos sinápticos. Isso deixa claro que as redes neurais artificiais têm em sua constituição uma série de neurônios artificiais (ou virtuais) que serão conectados entre si, formando uma rede de elementos de processamento.
A figura abaixo ilustra um neurônio artificial com os seguintes elementos: Entradas, Pesos (pesos sinápticos), Função Soma, Função de Ativação e Saída.
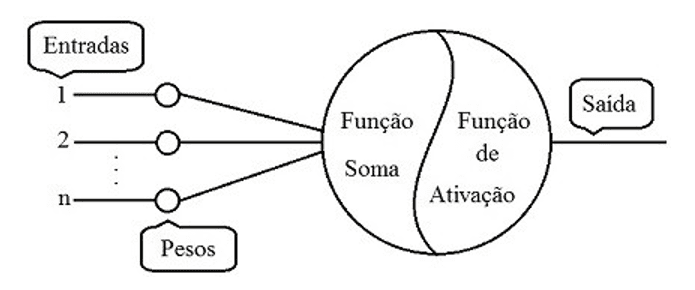
Na figura em sua operação as entradas 1,2 e n são multiplicadas pelos respectivos pesos sinápticos e então são somadas e processadas por uma função de ativação. A função de ativação avalia o resultado obtido de acordo com os limites definidos para depois calcular e gerar as saídas desejadas.
As funções de ativação cuja função é executar o processamento nos neurônios são: Função Ativação Linear, Função de Ativação com Limite (Threshold), Função de Ativação Sigmoid e Função de Ativação Tangente Hiperbólica dentre outras mas aqui estão as mais utilizadas, devendo ser escolhida de acordo com a funcionalidade desejada.
5.3 REDE NEURAL MLP
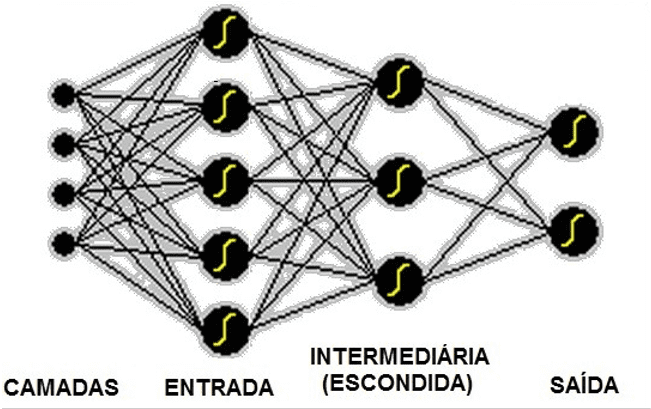
A rede MLP (Multilayer Perceptrons) é estruturada em três tipos de camadas neurais: entrada, intermediária e saída. A camada de entrada é responsável por receber os estímulos do ambiente a ser classificado e conectá-los à camada intermediária, que têm a função de extrair a maioria das informações comportamentais da aplicação, essa por sua vez é conectada a saída que informa a que classe pertence à amostra recebida na entrada.
No caso de redes com múltiplas camadas não é possível obter o erro diretamente através da diferença entre a saída desejada e a saída recorrente da rede, pois não existem saídas desejadas definidas para camadas intermediárias. O problema é calcular ou estimar o erro das camadas intermediárias.
Qualquer Perceptron com pelo menos uma camada escondida é um Perceptron Multicamada. Cada neurônio recebe várias entradas da camada anterior e calcula uma combinação linear dessas variáveis.
O algoritmo capaz de treinar as redes perceptron de multicamadas é o algoritmo de retropropagação ou Backpropagation, onde o princípio do seu cálculo é utilizar o gradiente descendente e estimar o erro das camadas intermediárias pela estimativa do resultado encontrado no erro da camada de saída.
O Backpropagation é um tipo de algoritmo supervisionado que utiliza pares de entrada e saída da rede para, por meio de um mecanismo de correção de erros, ajustarem os pesos da rede. O erro da saída da rede é calculado, sendo retroalimentado para as camadas intermediárias, possibilitando o ajuste desses pesos.
As redes multi-camadas têm um potencial computacional muito maior que os perceptrons de uma camada, justamente por conseguirem tratar dados não linearmente separáveis. É o número de camadas da rede que define a potencialidade de processamento da rede.
A figura abaixo ilustra uma rede Perceptron Multicamadas.
5.4 USO DA REDE NEURAL
Os dados das janelas de análise serão divididos em 80% para treinamento e 20% para previsão, todavia, é importante ressaltar que os intervalos acima são inicialmente estimados, devendo ser depurado ao longo dos testes operacionais da rede neural para se obter o intervalo ótimo ou que melhor se aproxime dos resultados reais.
5.4.1 MODELO MATEMÁTICO
Para os experimentos desse trabalho foi escolhido um modelo autorregressivo de ordem 5, onde cada saída é determinada em função das quantidades vendidas nos cinco dias anteriores, conforme abaixo:
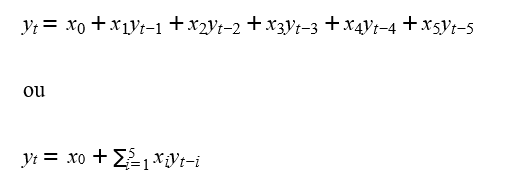
A função para os pesos é dado por:
W (k + 1) = W (k) + µ(−∇kE) – Equação I
E foi utilizado o Gradiente do Erro Quadrado Instantâneo para estimativa obtido através da função abaixo:
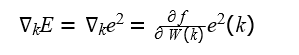
Se a função de Erro é e(k) = d(k) −y(k) e a função de saída da rede é dada por y(k) = W (k)T x(k) temos que:
∇kE = ∂ E(k)
∂W (k)
que aplicando a regra da cadeia obtemos:
∇kE = ∂ E(k) ∂ e(k) ∂ y(k)
∂ e(k) ∂ y(k) ∂W (k)
Desenvolvendo cada um dos fatores temos:
∂ E(k) = ∂ e2(k) = 2e(k)
∂ e(k) ∂ e(k)
∂ e(k) = ∂ (d(k)−y(k)) = −1
∂ y(k) ∂ y(k)
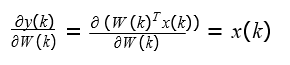
Assim temos o resultado da derivada completa agora com:
∇kE = −2e(k)x(k) – Equação II
Aplicando II em I vem a equação do peso:
W (k + 1) = W (k) + 2µe(k)x(k)
onde:
µ é o grau de aprendizagem,
e(k) é o erro na posição de execução k do vetor,
x(k) é a entrada
6. EXPERIMENTOS
Para esse trabalho foi utilizada uma base de dados de uma empresa varejista que atua tanto com lojas físicas como a loja virtual no comércio eletrônico digital comercializando utensílios domésticos. Por questões jurídicas o nome da empresa não será declinado, uma vez que não há permissão expressa, todavia, as informações são reais de suas operações. Os dados referem-se as vendas apenas no comércio eletrônico no período compreendido de 2014 a 2017, num total de 1.300.000 registros de vendas, que compreende todo o mix de produtos disponibilizados no site de compras.
Esses dados passaram por um processo de consistência e redução, obtidos de um banco de dados relacional, o MS-SQLServer, dessa forma foram ajustados de forma a minimizar as ações de processamento da rede neural. Para os dados tem-se as seguintes tabelas relacionais: Produtos, Marcas, Departamentos e Vendas diárias por pedido dos produtos.
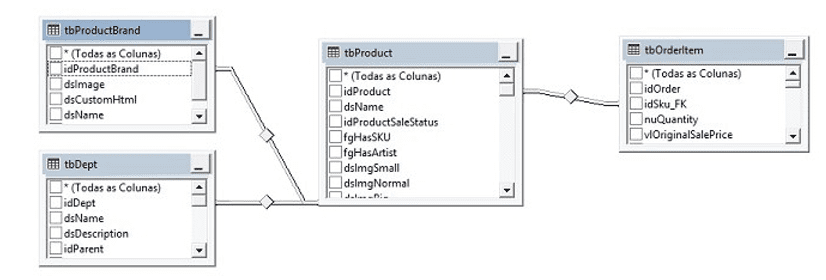
6.1 CRITÉRIOS PARA SELEÇÃO E TRATAMENTO DOS DADOS DA AMOSTRA
Os dados utilizados estão organizados em 5 (cinco) departamentos principais e seus sub-departamentos. Como a departamentalização aplicada implica em agrupar produtos correlacionados ou similares as amostras foram tomadas em nível de departamento para o treinamento da rede e em seguida selecionado um produto para o devido teste de previsão.
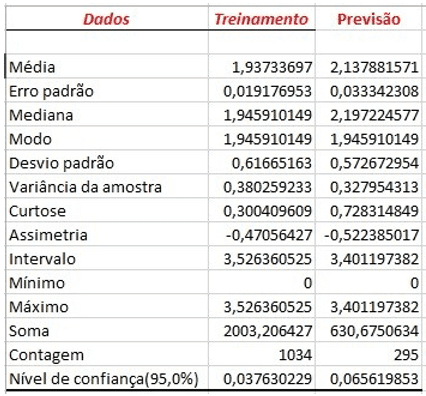
Da análise dos valores das quantidades vendidas verificou-se que são números inteiros e maior que a unidade, assim, para um melhor resultado na operação da rede neural todos os valores foram normalizados, aplicando-se a função log. Ainda sobre os dados selecionados foram aplicadas análises estatísticas no sentido de verificar a posição e dispersão dos dados. A figura seguinte mostra a Estatística Descritiva da amostra de dados obtidas para o treinamento e previsão. Da análise dos resultados tem-se que a amostra não apresenta dispersão, logo os dados são viáveis para o processamento em questão.
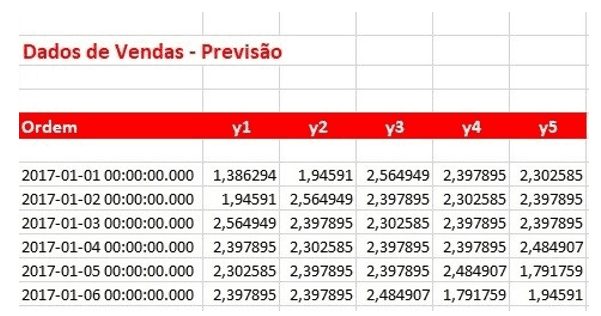
Para o treinamento da rede local foram selecionados 1034 registros de vendas no período de 01/01/2014 a 30/12/2016 e 295 registros de vendas para a previsão, classificados cronologica- mente, conforme as figuras seguintes. É importante ressaltar que a quantidade de registros para treinamento da rede neural é uma quantidade pequena, dessa forma o número de interação da rede (épocas) deverá ser razoavelmente grande para que haja convergência, bem como uma alta taxa de aprendizagem conforme veremos adiante.
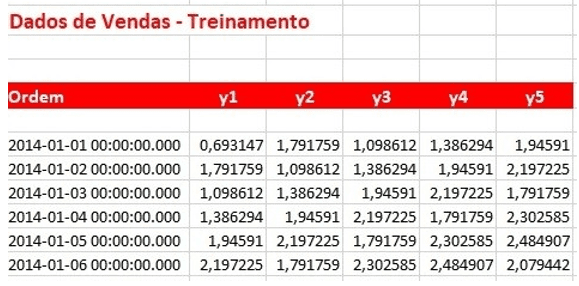
Percebe-se da análise das figuras que os dados estão deslocados de um dia, onde na diagonal verifica-se o mesmo valor.
6.2 PROCESSAMENTO DOS DADOS EM REDE NEURAL
Para os experimentos foram utilizados várias ferramentas de softwares escritas nas linguagens de programação Python, C# e R, os melhores resultados foram obtidos com o uso do software R associado aos pacotes NEURALNET, FORECAST e TSERIES. Para uma melhor performance na carga dos dados e minimização do tempo de processamento a carga dos dados foi feita com os dados em planilhas MS-Excel, uma vez que a execução de Stored Procedure diretamente no banco de dados com a carga para o ambiente se mostrou muito lento.
Com a finalidade de adequar o software às necessidades do algoritmo de minização do erro, Gradiente do Erro Quadrado Instantâneo, o pacote NEURALNET foi customizado para ser utilizado nesses experimentos.
Os testes de rede neural foram feitos por várias rodadas de execuções, com várias configurações, todavia, serão apresentadas as duas rodadas de execuções que tiveram os melhores resultados para o tema aqui abordado e que serão explanados e explicados a seguir.
7. RESULTADOS OBTIDOS
Para os testes foram executadas simulações no software R com o pacote NeuralNet customizado e fazendo uso dos algoritmos: BackPropagation e Random Walk. Os resultados serão apresentados e avaliados com base nesses dois algoritmos. Em todos os testes foram utilizados 1034 registros para treinamento e 295 registros para a previsão.
As mudanças entre os experimentos podem ocorrer nos seguintes parâmetros: número de neurônios, número de épocas, número de camadas intermediárias, taxa de aprendizagem e função de ativação. Logicamente que executar todos os testes possíveis com essas variáveis não é escopo desse trabalho, mas as mudanças feitas já permitirá perceber as alterações nos resultados obtidos.
7.1 EXPERIMENTO
O experimento 1 consistiu em tomar os dados de previsão e aplica-los na rede com os parâmetros constantes da figura 8. Vale considerar o número de épocas aplicado para o processamento, qual seja 1.000.000 (um milhão) de interações, pois para o número de neurônios e camadas aplicadas com valores inferiores a esse a rede não convergia e portanto nenhum resultado era gerado. Também foi percebido que o número de épocas também é função da taxa de aprendizado da rede, uma vez que para valores muito pequenos o número de interações precisa ser aumentado para que haja a convergência da rede.

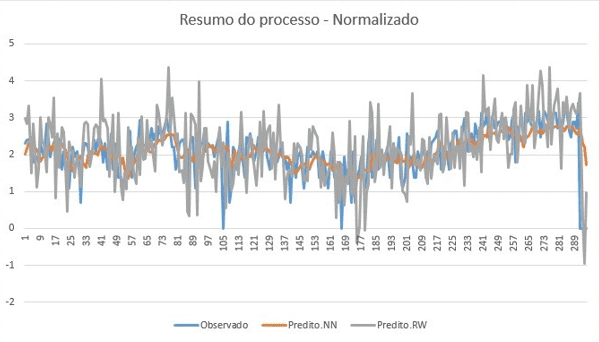
Do resultado apresentado, conforme o gráfico da figura 9, ve-se que o algoritmo BackPropagation mantém valores mais próximos dos valores informados, diverso do algoritmo Random Walk que nesse caso apresenta sempre resultados superiores ao informado.
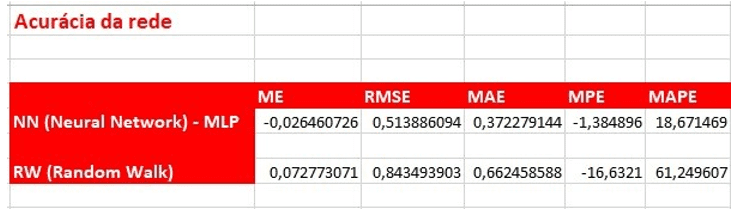
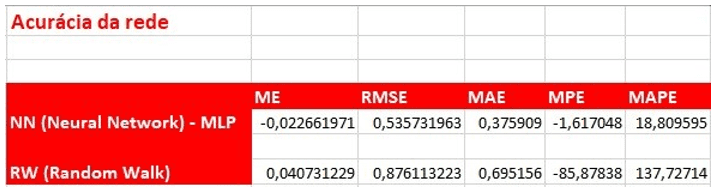
A análise da acurácia das redes conforme mostrado na figura 10, ve-se que o algoritmo Backpropagation é o que apresenta os melhores resultados na configuração de rede apresentada. Os dados aqui apresentados são obtidos baseados em cada linha da previsão previsão.
Da análise do R-Quadrado (Coeficiente de Determinação), figura 11, ve-se que apenas os valores obtidos para o algoritmo BackPropagation é explicado em 31% pelas variáveis de entrada, diverso do algoritmo Random Walk onde a resposta tem explicação em 17%. Assim verifica-se que o algoritmo Backpropagation nessas circunstâncias da rede é o melhor algoritmo a ser aplicado na previsão.

7.2 EXPERIMENTO 2
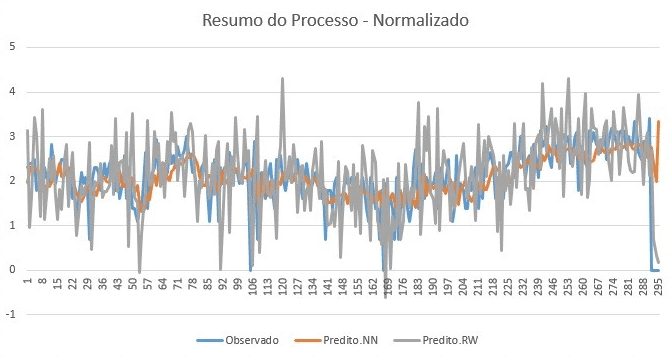
No experimento 2 foi feita alteração apenas no número de neurônios conforme a figura 12, dessa alteração conclui-se que apenas aumentar o número de neurônios não é suficiente para mudar de forma satisfatórias os resultados obtidos por uma rede neural, seja no algoritmo Backpropagation como no Random Walk, todavia, olhando para as figuras que se seguem, análogas às exibidas no experimento anterior, é possível identificar que o algoritmo que melhor se comportou nessa configuração foi o Backpropagation.
Em estudos seguintes é possível obter um maior refinamento dos resultados das redes neurais executando simulações outras alterando os demais parâmetros como por exemplo a taxa de aprendizado e o número de camadas intermediárias, como dito anteriormente esse trabalho não tem a pretensão de esgotar o assunto mas de encaminhar para outras pesquisas e melhorias.

Do resultado apresentado conforme o gráfico mostra ve-se que o algoritmo BackPropagation mantém valores mais próximos dos valores informados, diverso do algoritmo Random Walk que nesse caso apresenta sempre resultados superiores ao informado.

CONSIDERAÇÕES FINAIS
De posse dos resultados dos experimentos e da facilidade em se trabalhar com as redes neurais em comparação com outros processos, a exemplo da Regressão Múltipla, conclui-se que as Redes Neurais Artificiais são uma boa proposta para a previsão de vendas no varejo e podem ser consideradas pelas áreas de planejamentos como mais uma ferramenta a ajudar no processo.
Há atualmente vários estudos que envolvem o uso de redes neurais em processos ligados ao varejo, seja nas vendas como no marketing de vendas, todavia, coube a esse trabalho apenas a tarefa de conceituar os mecanismos e estimular o seu uso. Da bibliografia anexa que instrumen- talizou esse trabalho há inúmeras obras de grande valor acadêmico e prático que em muito pode ajudar os interessados em evoluir com a ideia proposta nesse trabalho.
REFERÊNCIAS BIBLIOGRÁFICAS
A., J. R. e R. Approximate option valuation for arbitrary stochastic processes. v.10, p.347-370. USA: Journal of Finance, 1982.
AL, B. G. et. Modelo de avaliação de opções para processos de difusão e salto. v. 39, p. 147-166. Foz do Iguaçu: XXIII ENANPAD, 1999.
AMIM K. E JARROW, E. Pricing options on risky assets in a stochastic interest rate economy. v.2, p.217-237. USA: Mathematical Finance, 1992.
BONOMO, M. Finanças aplicadas ao Brasil. 1. ed. Rio de Janeiro: FGV, 2002.
CAMPBELL, J. Y. e. a. The Econometrics of Financial Markets. 1. ed. Princeton, N.J.: Princeton University Press, 1997.
CHANG, E. MADAN D. e. The VG option pricing model, Working paper. 1. ed. USA: University of Maryland and Georgia Institute of Technology, 1996.
CHRYSSOLOURIS, G. M. L. e. A. R. Confidence interval prediction for neural network models. Vol. 7, no. 1, pg.229-232. EUA: IEEE Transactions on Neural Networks, 1996.
COX J. E ROSS, S. The valuation of options for alternative stochastic processes. v.3, p.145-166. USA: Journal of Financial Economics, 1976.
DUPIRE, B. Pricing with a smile. v.7, n.1,p. 18-20. USA: Risk, 1994.
GEMAN, S. E. B. e. R. D. Neural networks and the bias/variance dilemma. Vol. 4, pg. 1-58. EUA: Neural Computation, 1992.
GESKE, R. The valuation of compound options. n. 7, p. 63-81. USA: Journal of Financial Economics., 1979.
HAYKIN, S. Neural networks and learning machines. 2. ed. London: Pearson Education, 1999.
HESTON, S. A closed-form solution for options with stochastic volatility with applications to bond and currency options. v.6, p.327-343. USA: Review of Financial Studies, 1993.
HULL, J. Introdução aos mercados futuros e de opções. 1. ed. São Paulo: BM&F, 1996. HULL, J. Opções, futuros e outros derivativos. n. 7, p. 63-81. São Paulo: BM&F, 1998.
KON, S. J. Models of stock returns – a comparison. v. 39, p. 147-166. USA: Journal of Finance, 1984.
LANARI, C. S. O efeito “sorriso”da volatilidade implícita do modelo de Black e Scholes: estudo empírico sobre as opções Telebrás PN no ano de 1998. 1. ed. Belo Horizonte: Dissertação de Mestrado. CEPEAD/UFMG., 2000.
LO, A. AIT-SHALAIA e Y. Nonparametric estimation of state-price densities implicit in financial asset prices. 1. ed. USA: University of Chicago and MIT, 1996.
MENDES, L. S. Avaliação de opções: uma comparação do desempenho de métodos distintos de se estimar a volatilidade. 1. ed. Belo Horizonte: Dissertação de Mestrado. CEPEAD/UFMG., 2000.
MERTON, R. C. Theory of rational option pricing. n. 4, p. 141-183. USA: Bell Journal of Economics and Management Science., 1973.
MERTON, R. C. Option pricing when underlying stock returns are discontinuous. n. 3, p.125-144. USA: Journal of Financial Economics., 1976.
NETO, L. A. S. Opções: do tradicional ao exótico. 1. ed. São Paulo: Atlas, 1996.
R., B. W. S. The pricing of stock index options in a general equilibrium model. v.24, p.1-12. USA: Journal of Financial and Quantitative Analysis, 1993.
RUBINSTEIN, M. Implied binomial trees. v. 49, n. 3, p. 771-818. USA: Journal of Finance., 1994.
S., M. A. e T. Misspecification and the pricing and hedging of long-term foreign currency options. v.14, p.373-393. USA: Journal of International Money and Finance, 1995.
S., M. A. T. Pricing foreign currency options with stochastic volatility. v.45, p.239-265. USA: Journal of Econometrics, 1990.
SAMUELSON, P. Proof that Properly Anticipated Prices Fluctuate Randomly. 1. ed. Chicago-USA: Industrial Management Review, 1965.
SCOTT, L. O. Option pricing when the variance changes randomly: theory, estimation, and an application. vol. 22, p. 419-438. USA: Journal of Financial and Quantitative Analysis, 1987.
SCOTT, L. O. Option pricing when the variance changes randomly: theory, estimation, and an application. vol. 22, p. 419-438. USA: Journal of Financial and Quantitative Analysis, 1987.
STEIN E. E STEIN, J. Stock price distribuitions with stochastic volatility. v.4, p.727-752. USA: Review of Financial Studies, 1991.
V., A. K. N. Option valuation with systematic stochastic volatility. v. 48, p.881-910. USA: Journal of Finance, 1993.
WIGGINS, J. B. Option values under stochastic volatility: theory and empirical estimates.
Vol. 19, 1987, p.351-372. USA: Journal of Financial and Quantitative Analysis, 1987.
Z., B. G. e CAO C. e C. Empirical performance of alternative option pricing models. v.52, n.5, p.2003-2049. USA: Journal of Finance, 1997.
[1] Mestrando em Engenharia Elétrica e Computação na Universidade Presbiteriana Mackenzie
[2] Engenheiro Elétrico e da Computação, M.Sc., Ph.D pela Universidade de São Paulo (USP) – Coordenador do Mestrado de Engenharia Elétrica e Computação da Universidade Presbiteriana Mackenzie
