ARTIGO ORIGINAL
PUTTINI, Volnei Cervi [1]
PUTTINI, Volnei Cervi. Apache Impala: Estudo e aplicação das Funções Definidas pelo Usuário em C++. Revista Científica Multidisciplinar Núcleo do Conhecimento. Ano 05, Ed. 10, Vol. 08, pp. 82-119. Outubro de 2020. ISSN: 2448-0959, Link de acesso: https://www.nucleodoconhecimento.com.br/engenharia-da-computacao/apache-impala
RESUMO
Big Data nos lança constantes desafios técnicos voltados ao campo da infraestrutura de processamento massivo de dados. Na tentativa de obtermos êxito nesta tarefa, hardwares cada vez mais rápidos são utilizados, e consequentemente softwares capazes de aproveitar estes recursos devem ser projetados. O Apache Impala é resultado destes esforços possuindo um núcleo de processamento de alto desempenho totalmente codificado na linguagem C++. Este artigo apresenta um estudo introdutório sobre as técnicas para desenvolvimento das Funções Definidas pelo Usuário (UDF), as quais tiram proveito dessa arquitetura permitindo que algoritmos complexos possam ser escritos. As UDFs codificadas em C++ nos permitem a criação destes algoritmos de maneira qual sejam otimizados tanto no contexto da velocidade quanto do uso dos recursos computacionais disponíveis tais como consumo de memória. No decorrer deste artigo apresentaremos as bases teóricas necessárias para o entendimento da integração e funcionamento das UDFs junto aos mecanismos do Impala. Encerramos com a demonstração por exemplos das principais técnicas aplicadas a codificação na linguagem C++. Quando completadas a fases do desenvolvimento, iremos registrar a função para uso no contexto nativo do Impala, ou seja, na formação das declarações SQL desenvolvidas pelos usuários.
Palavras-Chaves: API, Big Data, C++, Apache Impala, UDF.
1. APRESENTAÇÃO
Com o fenômeno Big Data a comunidade cientifica teve que repensar como os dados deveriam ser tratados nos seus variados aspectos, criando e aprimorando recursos de rede, armazenamento e processamento que garantam a segurança, integridade e disponibilidade destes dados.
Conforme Taurion (2012), ”Big Data vem chamando atenção pela acelerada escala em que volumes cada vez maiores de dados são criados pela sociedade.”. A problemática que envolve o Big Data é ampla, sendo que para Taurion (2012), a sustentabilidade do Big Data é vista sob ”[…] duas óticas: as envolvidas com analytics, tendo Hadoop e MapReduce como nomes principais e a tecnologias de infraestrutura[…]”, que são destinadas ao armazenamento e processamento de dados. O Big Data possui muitas peculiaridades, uma das quais chama a atenção são os dados que na sua maioria são semi estruturados ou desestruturados, não seguindo os modelos tradicionais dos dados estruturados, pois apesar de ser possível armazenar, por exemplo uma imagem em um campo, não se pode aplicar as técnicas de ER[2] comuns para fazer associações à este objeto, daí a necessidade da criação de sistemas de bancos de dados NoSQL[3].
Também é apresentado o desafio de tratarmos os dados em tempo real[4]. Para que isso seja possível e principalmente viável no quesito velocidade, novas tecnologias especializadas foram criadas, tais como o Apache Spark, HBase, Flume, etc.
O Apache Impala, foco deste trabalho, foi desenvolvido como sendo um sistema para consulta e transformação de dados de alto desempenho que acessa dados arquivados no HDFS usando a tradicional linguagem SQL. Suas características apresentadas na Seção 2.3, o tornam ideal para o processamento de dados em tempo real.
Nosso objeto de interesse é explorar a possibilidade de expansão das capacidades de processamento de resultados do Impala mediante a programação de User-Defined Functions (UDFs), utilizando a linguagem C++, que são executadas diretamente nas declarações SQL do usuário do mesmo modo que as funções nativas.
Para alcançarmos nosso objetivo, serão apresentadas as teorias fundamentais que nos farão compreender como as UDFs interagem com os componentes internos do Impala. Iniciamos explanando sobre o frontend e o backend os quais juntos compõem os principais mecanismos de interpretação e execução das declarações SQL e UDFs. Em seguida passamos para a API utilizada pelas UDFs para se comunicar como backend e por fim, exemplos funcionais de UDFs codificadas em C++.
Este trabalho está assim estruturado: O Capítulo 2 são as bases teóricas necessárias para alcançarmos nossos objetivos, apresentando as tecnologias utilizadas. No Capítulo 3, é apresentado trabalhos relacionados os quais também foram fontes de consulta. O Capítulo 4, abrange os conceitos aplicados as Funções definidas pelo Usuário, com enfoque nas características básicas, operacionais e estruturais, necessárias para que possamos compreender como elas funcionam internamente para que possamos então codificá-las, também abrange as instruções DDL[5] necessárias que são usadas para criação das funções no contexto do Impala. O Capítulo 5 é a implementação da solução mediante exemplos. Por fim o Capítulo 6 é o encerramento, no qual expomos nossas considerações sobre os assuntos abordados e projetos futuros.
2. FUNDAMENTAÇÃO TEÓRICA
2.1 AMBIENTE CLOUDERA QUICKSTART
Padronizamos o uso do ambiente Cloudera Quickstart para nossos testes e estudos sobre o tema Big Data, devido sua integração e estabilidade as quais nos permitem efetuar estudos aplicados ao ecossistema Hadoop, mais especificamente em: Hadoop HDFS, Apache Impala, Apache HBase e Apache Hive.
Porém o Cloudera QuickStart não é destinado ao uso em ambientes críticos de produção, sendo destinado para aprendizagem e testes. Apesar dessa aparente limitação, caso esteja instalado em um sistema com grande capacidade de memória e espaço de armazenamento, é possível sua utilização em testes com grandes volumes de dados.
Características da VM Cloudera QuickStart 5.13:
- OS: CentOS 6.7.
- Hipervisor: KVM.
- RAM mínima requerida: 8 GiB.
- Versão do compilador: g++ (GCC) 4.7 20120313 (Red Hat 4.4.7-23).
- Versão do compilador: clang version 4.2 (tags/RELEASE-34/dot2-final).
- Versão do Apache Impala: 10.0-cdh5.13.0 (2511805).
- Sistemas padrão instalados: Hadoop HDFS, Flume, HBase, Hive, Hue, Impala, Key-value, Oozie, Solr, Spark, Sqoop2, YARN,
Ambiente configurado para testes:
- 06 vcpus Intel® Xeon® E1235; 12 GiB RAM; 1 TiB armazenamento.
2.2 LINGUAGEM C++
A linguagem C++ foi criada e é mantida pelo cientista da computação Bjarne Stroustrup e seus colaboradores. Ela foi criada para ser uma linguagem de uso geral, com capacidades suficientes para a programação de grandes sistemas. A princípio C++ pode ser considerada um C aprimorado, porém suas capacidades vão além. C++ é uma linguagem conhecida como multiparadigma, possuindo os mecanismos necessários para programação, tanto no paradigma procedural bem como orientado a objetos. No C++, sua principal característica é a classe, a qual permite a criação de novos tipos de dados totalmente encapsulados, com garantias de gerenciamento de memória e ocultação de dados e funções membros para comunicação entre a classe e mundo externo e vice-versa.
Listagem 1 Exemplo de definição de uma classe.

C++ é uma linguagem compilada, ou seja, o código fonte escrito é totalmente convertido em linguagem de máquina nativa do processador em uso, resultando em um código executável altamente otimizado.
Um ponto recorrente quando falamos de C++ é sobre sua portabilidade, ou seja, sua capacidade de “existir” em sistemas totalmente diferentes seja no nível do hardware como do software, no caso o sistema operacional. Podemos entender o conceito de portabilidade de dois modos: No seu nível mais alto a sintaxe e estrutura geral da linguagem devem ser consistente mesmo quando usamos compiladores ou ambientes diferentes, a segunda diz respeito a capacidade do código objeto gerado poder ser executado em diferentes hardwares devendo então as bibliotecas padrão ou de terceiros serem projetadas objetivando este cenário. C++ abrange estas duas características.
Os comitês ANSI e ISO conseguiram a padronização da linguagem e da biblioteca padrão com um trabalho de alta qualidade nos permitindo utilizar uma linguagem com código fonte muito elegante e organizado além de organização da biblioteca padrão, conforme:
O padrão ISO C++: C++ é padronizado pela ISO (Organização Internacional de Padrões) em colaboração com organizações de padrões nacionais, como ANSI (Instituto Americano de Padrões Americanos), BSI (Instituto Britânico de Padrões), DIN (Organização Nacional de Padrões da Alemanha). O padrão C++ original foi emitido em 1998, uma revisão menor em 2003 e uma atualização importante, C++11, foi lançada em setembro de 2011, e o padrão atual é C++14. Durante seu desenvolvimento, o C++11 foi referido como C++0x. Depois disso, C++ 14 e C++17 foram entregues de acordo com um novo e ambicioso cronograma de três anos. Atualmente, o comitê de padrões está trabalhando para produzir um novo padrão, uma grande revisão, em 2020: C++20. (STROUSTRUP, 2002)
No contexto da geração do código objeto nativo a portabilidade é alcançada através dos mecanismos de Diretivas do Pré-processador, e é conhecida como compilação condicional, a qual é a fase anterior a compilação que permite ao compilador conhecer o ambiente para qual o código objeto deverá ser criado. Tais diretivas são muito flexíveis e abrangentes, sendo possível definir arquiteturas de processadores, sistemas operacionais e modelos de compiladores diferentes dentro mesmo código fonte, permitindo assim criação das instruções regulares para o ambiente alvo.
Listagem 2: Exemplo ilustrativo de instruções para o pré-processador.
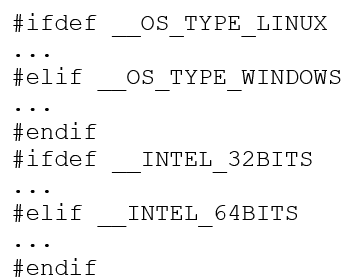
Outro fator que influencia diretamente na portabilidade do código executável refere-se à representação binária dos dados e suas precisões.
Para termos melhores garantias de que não haverá problemas nesse sentido, podemos utilizar tipos de dados definidos na STL para garantir a compatibilidade binária entre sistemas.
Como exemplo dessa implementação o arquivo header cstdint define os tipos inteiros portáveis conforme podemos observar no fragmento de código abaixo:

Desse modo quando queremos que haja garantias de que um número inteiro com sinal tenha suas características binárias mantidas, devemos declará-lo do seguinte modo: int64_t max_counter;
Pois caso ele seja declarado como um tipo ‘long long int’ poderá haver discrepância em sua representação binária entre os sistemas.
Tal implementação de projeto, não se resume a tipos numéricos, sendo estendida aos demais tipos de dados aceitos pelo padrão da linguagem.
Assim usando estas técnicas podemos criar programas realmente portáveis entre, processadores de diferentes arquiteturas, sistemas operacionais e compiladores. Preservando a principal característica da linguagem no que se diz respeito a geração do código de máquina nativo. (STROUSTRUP, 2002)
Com relação á disponibilidade de bibliotecas complementares existem centenas, algumas como a Boost C++ Libraries[7], a qual segue todos os padrões da STL[8] e que melhora em muitos casos nossa produtividade e qualidade do algoritmo de um modo geral, sendo extensivamente utilizada no código fonte do Impala. A biblioteca TensorFlow[9] especializada em IA[10], análise de dados e computação numérica geral pode ser utilizada para se criar algoritmos dedicados a Big Data. Qt[11] é uma framework completa que possui uma biblioteca extensa e padronizada para criação de programas multiplataformas tendo como principal linguagem o C++.
2.3 APACHE IMPALA
Conforme Cloudera (2020b), ”O Impala é um mecanismo de consulta C++ moderno, MPP[12], que permite analisar, transformar e combinar dados de uma variedade de fontes de dados.”.
Quando nos referimos ao Impala como “mecanismo de consultas” significa que ele não é um SGBD[13] padrão como por exemplo o HBase que é um banco de dados orientado a colunas ou o IBM® DB2® relacional. O Impala possui a capacidade ler dados de diversos formatos tais como Parquet, Text, Avro, etc., que estão armazenados no Hadoop HDFS, gerando resultados mediante o uso da linguagem SQL. (KORNACKER et al., 2015)
Como o projeto do Impala é voltado ao desempenho ele implementa uma arquitetura distribuída baseada em processos daemon[14] que são responsáveis por todos os aspectos da consulta execução e que são executados nas mesmas máquinas como o resto da infraestrutura Hadoop.bittorfimpala.
Segundo Yue (2014), o Impala daemon chamado impalad, possui duas funções: a primeira é a de coordenar a execução das consultas, e designar tarefas para outros impalad e coletar os resultados enviados de outros processos. A segunda função executaria as tarefas de outro impalad, operando principalmente dados no HDFS e HBase em operações de E/S locais. Ou seja os daemons impalad se comunicam enviando e recebendo tarefas, efetuando as operações de E/S localmente nos nós do cluster a fim de garantir o melhor desempenho possível em tais operações de consulta.
Figura 1 Arquitetura Apache Impala:
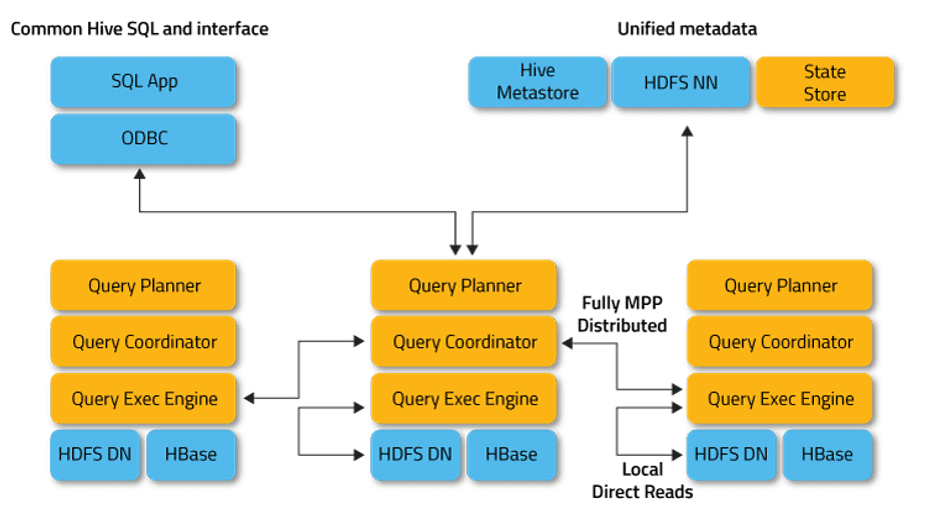
Na Figura 1, os retângulos amarelos identificados por Query Planner, Query Coordinator e Query Exec Engine representam o impalad. Podemos notar a seta que indica a troca de dados entre o Query Exec Planner e o Query Coordinator de outro impalad, conforme explicado acima. Os retângulos identificados como Common Hive SQL and interface, representam as interfaces de interação com o Impala, podendo ser, drivers JDBC/ODBC, Impala-shell e o Hue.
Os módulos identificados por Unified metadata, representam os locais onde os metadados são armazenados e compartilhados. O State Store é responsável por checar o estado de funcionamento dos daemons Impala em todos os nós dentro do cluster Hadoop.
Por fim temos as leituras diretas locais representadas pelo HDFS Namenode(NN) e o banco de dados HBase. (IMPALA, 2020), (DATAFLAIR, 2020).
O Impala na sua estrutura possui dois componentes conhecidos como frontend e backend, ao entendermos suas diferenças e como eles interagem, vemos o quão pode ser apropriado a codificação em C++ das UDFs.
O frontend dentro da arquitetura do Impala é representado pelo Query Planner e Query Coordinator, que conforme Kornacker et al.(2015,tradução nossa), ”O frontend do Impala é responsável por compilar o texto SQL em planos de consulta executáveis pelo backend do Impala.”. Este componente está escrito em Java. Todo o analisador SQL e otimizador, são projetos novos e originais. O Impala, além do SQL básico, suporta VIEWS, consultas correlacionadas ou não e todas as variantes de joins.
Divisão de tarefas executadas pelo analisador:
- Análise da consulta;
- Análise semântica;
- Planejamento/otimização da consulta, sendo esta fase a mais complexa.
O planejador de consultas do Impala recebe uma estrutura de dados em árvore, juntamente com as informações globais da consulta reunidas durante a análise semântica (identificadores de tabela/coluna, classes de equivalência, etc.). Um plano de consulta executável é construído em duas fases: (1) planejamento de nó único e (2) a paralelização e a fragmentação do plano., daí envia os fragmentos da consulta para o que o backend possa executá-los.
O backend possui todos os mecanismos necessários para executar as consultas. A necessidade de alto desempenho e estabilidade nestes processos justificam seu projeto baseado totalmente em C++. O Impala irá priorizar a geração de código em tempo de execução das funções de consulta mediante o uso do LLVM.
O LLVM não é um compilador tradicional, sendo um conjunto de ferramentas, geralmente referenciado como uma infraestrutura para compilação, que provém um otimizador e gerador de código e possui com interface o llvm-gcc e Clang. O backend faz uso intensivo das vantagens da geração de código em tempo de execução as quais são aplicadas em funções com loops internos ou funções que fazem varreduras extensas no banco de dados ou consomem muita memória, podem ser exemplos. A técnicas de geração de código. Esta característica no permite desenvolver bibliotecas no formato Intermediate Representation (IR). O código de IR é semelhante ao código da linguagem Assembly, sendo que suas instruções podem ser diretamente mapeadas para o código de máquina. O modo de utilização é o mesmo das bibliotecas compartilhadas, porém este formato pode ser executado ainda mais rápido e com mais economia de recursos. A principal diferença entre como o código objeto de uma biblioteca compartilha (.so) e executado e o código IR (.ll) gerado está relacionado a otimização. Enquanto toda a otimização esta embutida no arquivo .so, o código IR é incorporado pelo plano de execução e então passa ter todas as vantagens da otimização deste componente. (WANDERMAN-MILNE; LI, 2014), (INFOLAB, 2014).
Como nosso foco no Impala são as UDFs, seguiremos apresentando seu conceitos e como elas se integram ao sistema.
3. TRABALHOS RELACIONADOS
Esta seleção de trabalhos relacionados nos mostram quão desafiador podem ser nossos estudos sobre o tema proposto. As fontes de informação na sua maioria utilizam as mesmas fontes de informações sendo as principais o próprio código fonte do Impala e a documentação do site oficial e o artigo escrito por Kornacker al. (2015).
Este trabalho escrito por Kornarcker et al. (2015), explica como o Impala presta os serviços propostos ao usuário, contemplando todos os seus componentes e como eles se integram. Explica em detalhes quais as funções dos chamados componentes de backend e frontend e o uso da geração de código em tempo de execução.
O artigo escrito por Sharma (2018), apresenta um texto introdutório sobre as vantagens em se utilizar UDFs e como modificá-las, apresentando um ‘case’ no qual o uso de uma UDF para conversão de tipos de dados TIMESTAMP.
Simplilearn (2018), descreve de forma resumida a arquitetura e as funções dos principais componente, além de descrever o fluxo de execução de uma consulta SQL e sobre o uso das UDFs.
Neste tutorial o autor Balena (2016) apresenta como configurar e compilar os exemplos de UDFs e UDAFs disponíveis no código fonte o Impala, o que nos proporciona uma base muito boa para entendermos como deve ser feito, e também como registrar uma função para uso no banco de dados e nas declarações SQL.
Este documento Carnigie Mellon (2020), apresenta um resumo simples, porém bem organizado sobre o que é o Impala e como ele é composto.
Neste documento Infolab (2014), nos fala sobre como se considerou bem vinda a capacidade do Impala em suportar UDFs, e principalmente em se poder além de criá-las no formato de bibliotecas compartilhadas, que é possível usar código LLVM IR e tirar vantagens desse recurso.
De posse do conhecimento acumulado, podemos agora aprofundar nossos estudos codificando, compilando e utilizando os exemplos propostos.
4. CONCEITOS SOBRE AS UDFS[15]
Do ponto de vista do usuário final, uma UDF não difere de uma função interna padrão em nenhum aspecto, já que segue todas as mesmas regras de uso e apresentação de resultados. Porém um aprofundamento nos conceitos estruturais das UDFs são necessários quando nos dispomos a modificá-las.
Características primitivas:
- As UDFs são funções escalares, conforme IBM (2020), são funções que ”produzem um único valor escalar para cada linha que satisfaça a condição de pesquisa da sua consulta.”.
- Os valores produzidos podem ser do mesmo tipo do parâmetro informado na função ou pode ser um valor de outro tipo, ou seja, convertido.
- Podem possuir diversos parâmetros de entrada.
- Podem ou não ser determinísticas. Por exemplo: y = acos(x), sempre retornará o arco-cosseno do angulo dado. Já hora_atual = time(), sempre retornará a hora atual, porém atualizada com o valor no momento da chamada.
- As funções escritas em C++, não podem possuir argumentos ou valores de retorno dos tipos complexos, STRUCT, ARRAY e MAP.
A codificação das UDFs em C++ é fortemente aconselhada porque a biblioteca compilada em código nativo é otimizada levando-se em consideração o melhor aproveitamento possível dos recursos do hardware, além de integrar-se perfeitamente a arquitetura interna do Impala. Este procedimento e incentivado conforme Cloudera, (2020c), ”[…] o tempo de execução da UDF é geralmente 10 vezes mais rápido para uma UDF em C++ do que para sua equivalente em Java.”.
Resumo das considerações de uso:
- Melhorias na persistências da UDF introduzidas no Impala 2.5;
- O arquivo de biblioteca C++ gerado é do tipo shared object[16], ou seja, .so;
- Deve-se utilizar a instrução CREATE FUNCTION para distribuir a função para cada nó do Impala;
- O Impala não possui atualmente nenhuma instrução do tipo ALTER FUNCTION, desse modo, quando se deseja atualizar o arquivo de biblioteca registrado, deve-se sempre usar DROP FUNCTION nome-função(tipo, …) e depois usar a instrução CREATE FUNCTION novamente; ,
- Funções não podem ter seu processamento cancelado. Elas devem tratar uma situação de exceção internamente e retornar ao chamador um valor adequado e uma mensagem indicando o problema ocorrido.
- Podem existir funções com o mesmo nome SQL, porém seus parâmetros devem obrigatoriamente ser diferentes, por exemplo: print(STRING) e print(INT).
- Não pode haver uma UDF com mesmo nome das funções built-in.
- O Impala chama o código subjacente durante a avaliação da instrução SQL, quantas vezes forem necessárias para processar todas as linhas do conjunto de resultados.
- Todas as UDFs são assumidas como determinísticas.
- O Impala pode ignorar ou não algumas invocações de um UDF se o valor do resultado já for conhecido de uma chamada anterior.
- Não é permitido que as funções acessem arquivos ou dispositivos externos ao contexto do Impala.
Persistência das funções: O termo persistência refere-se ao fato de que quando criamos a função ela irá ser permanentemente registrada no metastore[17] do banco de dados, desse modo sobrevivendo as reinicializações. Esta característica não existia nas versões iniciais do Impala, ficando apenas criada na memória do daemon catalogd. Atualmente quando criamos uma função ela é registrada no banco de dados em uso e somente estará visível para ele, não há um conceito de funções/bibliotecas globais realmente. No caso de querermos usar a mesma função em banco de dados diferentes temos algumas opções: Registramos a biblioteca em todos os bancos que serão usados ou nós as referenciamos indicando o nome do banco de dados antes, por exemplo: default.func01(arg).
4.1 DECLARAÇÕES DDL – REGISTRO DA ASSINATURA DA UDF
Apresentamos a sintaxe das instruções DDL para controlar a criação, remoção e visualização da funções:
Sintaxe Geral[18]:

Devemos notar que não é obrigatório que o nome da função que será visível ao usuário do Impala seja o mesmo da função da biblioteca (SYMBOL). Isso é útil para podermos dar nomes as funções mais sugestivos aos usuários. Quando damos o nome da função temos também que indicar qual, ou quais são os tipos dos argumentos de entrada indicados por seu parâmetro, não sendo necessário nomeá-los, mas sim apenas colocar qual é seu tipo. Em seguida o parâmetro RETURNS indicará qual é o tipo de dado esperado como retorno do processamento, no nosso caso um tipo inteiro. O parâmetro LOCATION indica o caminho para o diretório (pasta) onde o arquivo da biblioteca foi copiado para o HDFS e por último o parâmetro SYMBOL sendo o nome interno usado na codificação da função.
Para apagar o registro da função do metastore do banco de dados é necessário usar a instrução DROP FUNCTION nome-da-funcao(tipo), salientamos que esta ação não possui qualquer efeito sobre a biblioteca compartilhada. Exemplo: DROP FUNCTION CnvStringToInt(string);
Para visualizar uma listagem contendo as características das funções criadas devemos utilizar a instrução: SHOW FUNCTIONS;
4.2 ESTRUTURA DA UDF
Para entender como a função do usuário interage com os mecanismos internos do Impala, é preciso estudarmos o principal arquivo da API header udf.h, que pode ser encontrado no diretório /usr/include/impala_udf/, e que contém a abstração desta interface.
O Impala possui um kit de desenvolvimento suficientemente útil e simples, sendo assim composto:

- Tipos de dados internos:
Os tipos primitivos do Impala, STRING, INTEGER, DOUBLE, etc, possuem seus equivalentes internos, os quais são mapeados em estruturas de dados formadas por dois membros, sendo: um tipo booleano que informa se valor passado é o próprio dado ou não, ou seja, usado para validação da entrada. No caso de nenhum valor ser informado ele será nulo (NULL). O outro membro é onde o valor será armazenado para uso.
Podemos notar que alguns tipos aparentemente não são contemplados, tal como o tipo REAL, que neste caso se trata de um apelido para o tipo DOUBLE[19]. Já os demais tipos: VARCHAR(n), CHAR(n), DECIMAL(p,s), são tratados pela função de contexto e adequadamente convertidos.
Tabela 1: Estrutura de Dados – udf.h:
| Estrutura de Dados | Função |
| struct BooleanVal | Representa um atributo BOOLEAN |
| struct TinyIntVal | Representa um atributo TINYINT |
| struct SmallIntVal | Representa um atributo SMALLINT |
| struct IntVal | Representa um atributo INT |
| struct DoubleVal | Representa um atributo DOUBLE |
| struct FloatVal | Representa um atributo FLOAT |
| struct StringVal | Representa um atributo STRING |
| struct TimeStampVal | Representa um atributo TIMESTAMP. Possui um membro de 32-bits que representa uma data Gregoriana e um tipo de 64-bits que representa a data corrente em nanossegundos. |
Fonte: Impala Tutorials.
- API:
A comunicação da UDF com o restante sistema é feita através da classe FunctionContext, tendo como funções examinar o estado do sistema, reportar erros e gerenciar a memória.
- Protótipo geral:
As UDFs devem ter seus protótipos definidos seguindo as seguintes regras:
(a) O primeiro parâmetro deve ser um ponteiro para a API FunctionContext;
(b) A partir do segundo parâmetro deve-se colocar os argumentos de controle ou dados adicionais.
Listagem 3: Exemplo de protótipo geral da função.

É suportado a criação de funções com quantidade de argumentos variáveis, como por exemplo a função concat(string a, string b, …), observando que apenas parâmetros do mesmo tipo podem ser definidos, conforme:
Listagem 4: Exemplo função com argumentos de comprimento variados.

A UDF com argumentos de comprimento variado, possui uma prototipação diferente das com argumentos fixos, conforme o exemplo abaixo:
Listagem 5: Protótipo geral de função com argumentos de comprimento variável.

Durante a chamada da função o Impala se encarrega de passar os valores corretos para num_var_args que é o total dos argumentos, sem contar o primeiro argumento fixo separator e o contador de argumentos, além de um ponteiro para o primeiro argumento da lista que será usado no código da função para os processamentos necessários.
O registro da função no banco de dados possui diferenças, quanto a formato durante a definição dos argumentos, ficando a declaração SQL conforme o exemplo:
Listagem 6:Exemplo de registro e assinatura de UDF tipo variável.
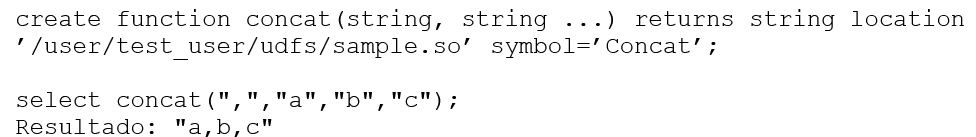
Na Listagem 6, a existência de reticências “…” após a declaração do segundo tipo string, está indicando que é permitido o uso de tantos mais argumentos do mesmo tipo desejados. Outro ponto, é quanto a declaração dos tipos dos parâmetros, ambos do tipo string, sendo que somente o primeiro que representa o argumento separator e o segundo *args devem ser usados.
- Funções Especiais Prepare e Close: São opcionais e normalmente são usadas nos casos específicos que precisam reter dados numa área compartilhada da memória e ou ter seu desempenho geral aprimorado devido ao mecanismo de theads utilizado. Isso permite que a cada nova chamada da função dentro da mesma thread acesse a mesma área de memória com os dados de maneira rápida e segura.
– Preparar (prepare): Esta função é chamada antes da função principal a fim de realizar tarefas relativas a validações, inicializações e alocações de dados na memória, por exemplo de estruturas (struct) ou quaisquer outros processos nos quais a retenção de dados para reutilização sejam necessários. O que irá dizer ao Impala que esta função é um função de preparação é como ela é definida na DDL CREATE FUNCTION, sendo necessário adicionar o parâmetro opcional prepare_fn = ’nome do símbolo’.
– Fechar (close): Esta função somente é chamada após todas as chamadas à UDF principal terem se encerrado. Sua função é basicamente a de desalocar estruturas de dados compartilhados para os quais os resultados não precisam ser mantidos. Do mesmo modo que prepare, esta função deve ser definida na DDL CREATE FUNCTION, usando close_fn = ’nome do símbolo’.
O tratamento de possíveis erros em ambas as funções devem ser feitos localmente, mediante a utilização das funções de contexto FunctionContext::SetError() e FunctionContext:AddWarning() a fim de informar ao usuário dos problemas ocorridos.
Listagem 7: Uso dos parâmetros prepare_fn e close_fn.
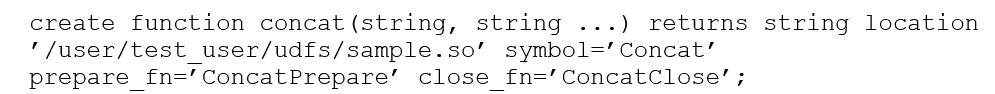
5. IMPLEMENTAÇÃO
5.1 REQUISITOS
- API de apoio:
- h: Arquivo principal de acesso a API.
- h[20]:

Conforme é explicado nos comentários no interior do arquivo, a macro é destinada a permitir que o Impala possa acessar o nome do símbolo quando a biblioteca for registrada no mecanismo interno, ou seja que os símbolos sejam “visíveis”. Caso esta macro já esteja definida no arquivo udf.h, então não há necessidade de usar esta definição. A macro é utilizada sendo declarada antes da assinatura da função como segue:

- Arquivos fontes do usuário: libimpala.h e libimpala.cc
Listagem 8: Arquivo fonte libimpala.h.

5.2 COMPILAÇÃO DA BIBLIOTECA COMPARTILHADA
Em situações mais complexas onde pode haver uma equipe desenvolvendo bibliotecas de UDFs haverá a necessidade de estabelecer um ambiente mais completo, nos dias de hoje com ferramentas ágeis por exemplo. Mas no nosso cenário isto não é necessário sendo apenas preciso criar um script para automatizar a digitação da linha de comando.
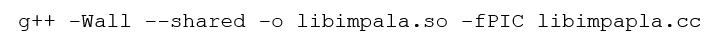
Os parâmetros aplicados ao compilador possuem as seguintes funções:
- Wall: -W (warnings) Indica quais mensagens de advertência mostrar durante a compilação, seguido de all para que qualquer mensagem seja mostrada.
- –shared: Diz ao compilado que deverá ser criada uma biblioteca compartilhada.
- -o: Nome do arquivo objeto gerado.
- -fPIC: PIC (Position-Independent Code) indica que o código objeto gerado pode ser executado em qualquer endereço válido na memória.
5.3 INSTALAÇÃO DA BIBLIOTECA NO HADOOP HDFS
Para que o Impala possa ter acesso à biblioteca, devemos copiá-la para o HDFS. Como o HDFS não é um sistema de arquivos regular, não podendo ser acessado diretamente, é necessário usar o comando hdfs do Hadoop na console do sistema Linux conforme mostrado na Listagem 8.
Listagem 9: Instalação da biblioteca.

5.4 EXEMPLOS
Os exemplos apresentados foram desenvolvidos com a finalidade de mostrar o uso dos componentes da API, e os três tipos fundamentais das UDFs, não havendo um compromisso com a usabilidade no mundo real ou aplicação de técnicas avançadas de programação em C++. As técnicas para construção das UDFs podem ser mescladas da maneira mais conveniente para a solução dos problemas.
No Exemplo 1, a UDF é criada com a estrutura mais generalista. De modo geral muitos casos podem ser assim resolvidos apenas tomando-se os cuidados necessários quanto a qualidade do algoritmo projetado.
No Exemplo 2, usamos a UDF tem a mesma função do Exemplo 1, porém sua construção está baseada no uso de threads. Esse enfoque é necessário quando precisamos de maior desempenho e/ou gerenciamento de dados em memória mais eficiente e seguro. Esta técnica faz uso intensivo de processamento paralelo.
No Exemplo 3, é demonstrado as bases para a construção de uma UDF com argumentos de comprimento variados, em C++ conhecidas como variadic functions.
5.4.1 EXEMPLO 1: RECUPERAÇÃO DE INFORMAÇÕES EM UMA LINHA DE LOG
Uma tarefa muito comum é a coleta de informações de registros de acesso à Internet e que são gravadas diretamente no HDFS ou no HBase. O Impala provém algumas funções de manipulação de strings tais como parse_url() e regexp_extract() que poderiam ser usadas para a recuperação das partes da linha de log. Porém consideramos que uma função dedicada a esta análise pode ser conveniente pois proporciona uma sintaxe simples e constante ao usuário, desenvolvemos então para nosso uso a UDF SquidLogParser() que retorna à porção da linha do log com a informação desejada, para fins das análises.
Para nossa conveniência, o formato da linha de log usado é do tipo CSV, outros tipos de formato não são aceitos pela função.
Listagem 10: Fragmento o arquivo squid.conf.

Sintaxe Geral: SquidLogParser(CAMPO_LOG, “palavra-chave”);
Listagem 11: Código fonte UDF SquidLogParser.






5.4.2 EXEMPLO 2: RECUPERAÇÃO DA INFORMAÇÃO EM UMA LINHA DE LOG USANDO THREADS
Este exemplo é constituído das três funções as quais compõem a estrutura das UDFs, sendo:
Função Preparação: Efetua as alocações de memória para a thread criada. Nos permite fazer teste de integridade dos argumentos.

Função Implementação: Executa a análise da linha de log passada e retorna a parte desejada, baseando-se na palavra-chave informada como argumento.

Função Fechar: Desaloca a memória para o “escopo” alocado pela função de preparação.
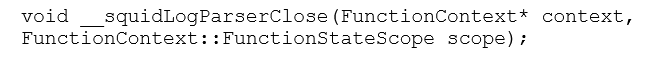
Esta função faz uso do mesmo algoritmo para “tokenizar” a linha do log usado na função __squidLogParser() anterior.
Listagem 12:Código fonte __SquidLogParser().




5.4.3 EXEMPLO 3: FUNÇÃO COM ARGUMENTOS DE COMPRIMENTO VARIÁVEIS
Uma das características muito úteis das UDFs é a possibilidade de criarmos funções de uso múltiplo, ou seja, dada uma única função, e passado um argumento de controle podermos executar diferentes processos em seu interior, relacionados entre si que façam uso dos mesmos argumentos de dados consumidos.
A função apresentada não preza pela sua usabilidade no mundo real, mas sim somente pretende demonstrar ambos os conceitos discutidos, sendo: argumentos de comprimento variados e múltiplo uso, efetuando cálculos estatísticos simples: Média simples, Desvio médio, Variância e Desvio padrão.
Sintaxe:
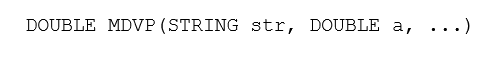
Exemplo:

Argumentos de controle: M = Média; D = Desvio médio; V = Variância; P = Desvio padrão.
Listagem 13: Código fonte função __MDVP().




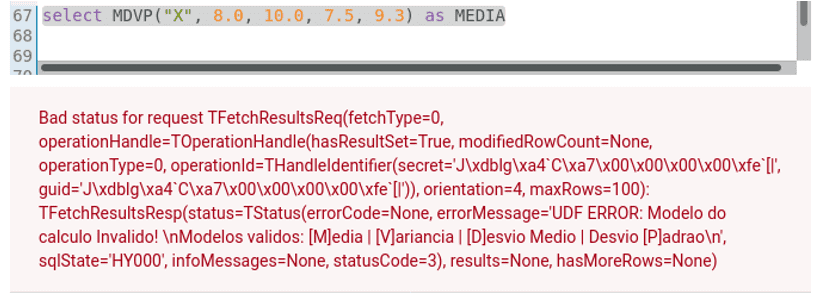
A Figura 2, mostra como as mensagens de erro da função são apresentadas ao usuário. No exemplo o argumento do parâmetro que indica o tipo de cálculo a ser feito não é válido.
Figura 2: Mensagem de erro retornada por MDVP().
5.4.4 REGISTRANDO AS ASSINATURAS DAS FUNÇÕES
Esta Seção destina-se a demonstrar como é feito o registro das assinaturas das funções da biblioteca compartilhada.
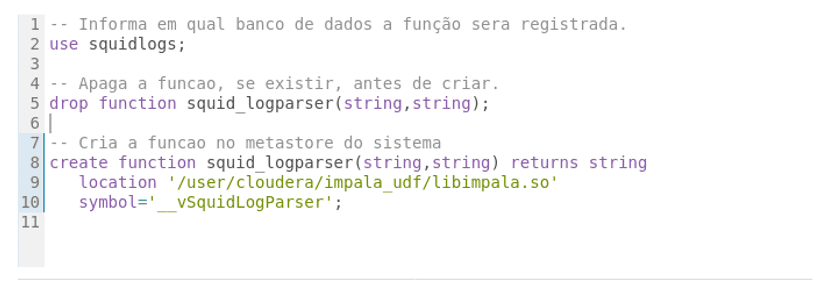
A Figura 3, demonstra como é feito o registro da assinatura da função no seu modo mais tradicional.
Figura 3: squid\_logparser_t(), com uso de paralelismo.
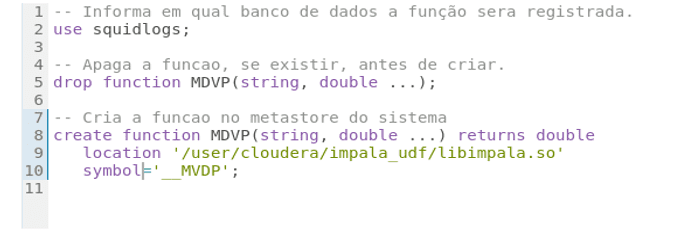
A Figura 4, demonstra como devemos declarar a assinatura de função que suporta argumentos com comprimento variáveis. Devemos notar que após o parâmetro variável em quantidade devemos colocar asterisco como forma de indicar tal característica.
Figura 4:Função do tipo variadic.
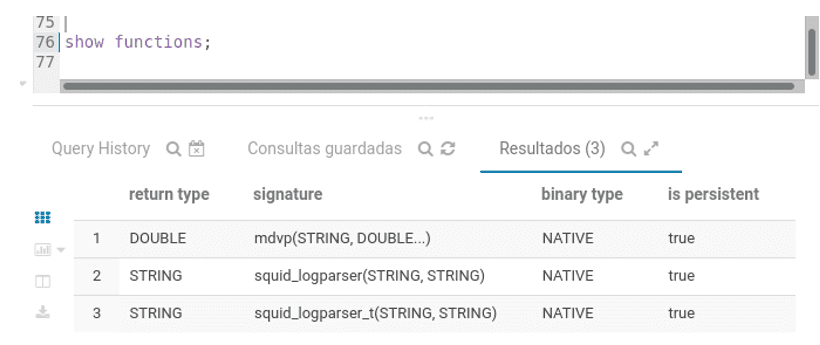
A Figura 5, mostra o resultado de SHOW FUNCTIONS em forma de tabela. Os campos possuem as seguintes designações:
- return type: É o tipo definido para retorno do processamento.
- signature: A assinatura da função, que define suas características, nome e tipos parâmetros e quantidades.
- binary type: Este campo é de nosso interesse, pois é ele que nos informa que as UDFs são ou não nativas do Impala.
- is persistent: Este campo é de nosso interesse, pois quando configurada para true(verdadeiro), indica que a função está gravada no metastore e não será apagada.
Figura 5: Listagem das funções criadas.
5.4.5 APLICAÇÃO DAS FUNÇÕES
Os exemplos apresentados foram executados na plataforma HUE[21], que é uma interface visual destinada a permitir a interação com o Impala e seus dados mediante o uso de declarações SQL, além de outros sistemas tais como Hive, HBase etc.
Figura 6:Exemplo 1: SQL Tradicional sem uso da UDF.
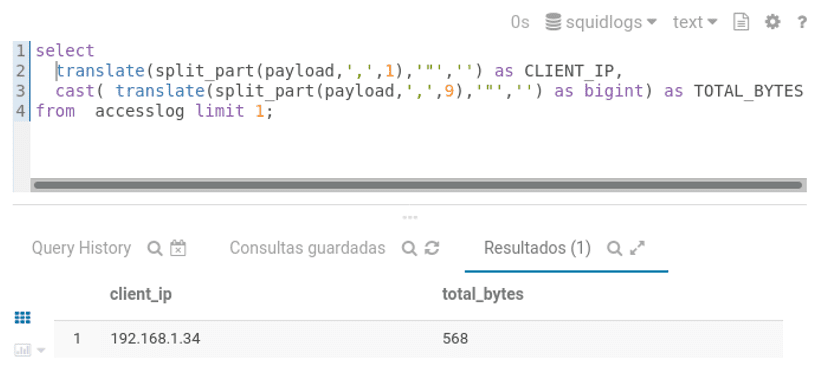
Figura 7:Exemplo 2: Declaração simplificada pelo uso da UDF.

Na Figura 6, usamos uma possível combinação de funções internas do Impala para recuperar as informações referentes ao endereço IP do cliente e total de bytes da requisição. A função split_part(), irá separar a linha de log mediante a informação do tipo do separador dos campos utilizado, e retorna a parte da linha de log que queremos mediante a informação numérica da posição do campo. O resultado dessa função é uma string nesse formato por exemplo: “192.168.1.100”, notar as aspas que fazem parte do resultado, para eliminarmos as aspas utilizamos a função translate(), que efetua a troca das aspas por um caractere nulo. Para o total de bytes é usada a mesma técnica, porém desejamos que o valor retornado seja convertido em um tipo bigint, que para isso usamos cast(a as T).
Na Figura 7, efetuamos a mesma consulta, porém usando nossa UDF, podemos notar que a declaração SQL fica com leitura e objetivos mais claros além de termos que utilizar menos funções.
A função squid_logparser_t(string, string), é usada do mesmo modo e produz os mesmos tipos de resultados. Sua principal diferença é arquitetural pois faz uso de threads.
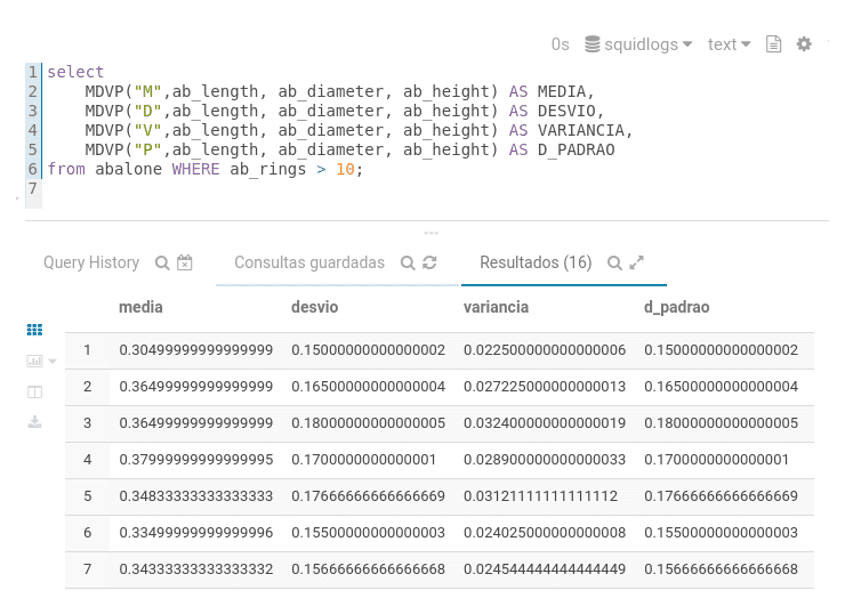
Na Figura 8, podemos ver o uso da função MDVP(). A função afeta os atributos da linha recuperada do banco de dados. Como qualquer outra função que se enquadra na classe das funções matemáticas pode ser combinada com outras para formar fórmulas mais complexas se necessário.
Figura 8: Resultado dos cálculos hipotéticos para o Abalone DataSet.
6. CONSIDERAÇÕES FINAIS E TRABALHOS FUTUROS
As principais fontes de pesquisa para o desenvolvimento deste artigo foram os manuais oficial do Apache Impala, o código fonte do Impala e o artigo Kornacker et al. (2015). Devido à natureza do assunto abordado, há certa escassez de publicações e em geral são fragmentadas ou mesmo simples adaptações dos originais. Assim nossa principal contribuição é a compilação das bases teóricas em um documento abrangente que permita ao leitor compreender as tecnologias envolvidas na codificação das UDFs e tentar desmistificar seus conceitos incentivando seu estudo e utilização pela comunidade.
Conforme apresentado neste artigo a UDF é uma ferramenta poderosa e eficaz que proporciona a versatilidade adicional para a solução de uma variada gama de problemas. Os processos envolvendo ETL[22], podem afetar trilhões de registros, e o tempo despendido no processamento é crítico e milissegundos economizados são importantes, sendo por si só este fato um grande incentivo a adoção das UDFs.
Ao unirmos as vantagens de desempenho com a utilização de bibliotecas especializadas em processamento numérico, aprendizado de máquina e afins, ampliamos enormemente a gama de soluções para problemas relacionados ao contexto do Big Data.
Não podemos ignorar as complexas lógicas em SQL, as quais também contribuem para baixos desempenhos. Ao transportarmos as partes pertinentes destes algoritmos para as UDFs, além do ganho na velocidade de execução contribuímos para a produtividade do analista SQL abstraindo problemas complexos os quais podem não estar totalmente na sua alçada, entregando funções úteis, eficientes e padronizadas no formato nativo do Impala.
As UDFs, podem ser úteis tanto no processamento em lote com em tempo real, neste último, seus benefícios podem ser aplicados na diminuição do uso das rotinas de Serialização/Deserialização(SERDE) durante a coleta dos dados. Ao simplificarmos os algoritmos de SERDE, podemos diminuir as latências envolvidas nesse processo, dando ao coletor a oportunidade de consumir menos tempo na sanitização dos dados de entrada melhorando sua capacidade de transmissão ao destino quando este fator é crítico, a exemplo de IoT.
Em trabalhos futuros pretendemos estudar as User-Defined Aggregate Functions (UDAFs). As UDAFs são um modelo diferente de UDFs, as quais são utilizadas para efetuar cálculos que agreguem valores baseados em conjuntos de dados processando as linhas das tabelas. Seu uso mais comum é relativo a operações de somatórios e contagens ou nas cláusulas de agregação HAVING, por exemplo, select max(salario_base) from tabfolha group by fund_id having max(salario_base) > 2500.00. Apesar de grande parte das bases teóricas serem as mesmas apresentadas para as UDFs, sua codificação possui características próprias as quais serão abordadas em um artigo próprio.
REFERÊNCIAS
BALENA, S. Creating UDF and UDAF for Impala. Hadoop Online Tutorial, 2016. Disponivel em: <https://hadooptutorial.info/creating-udf-and-udaf-for-impala/>. Acesso em: 15 jan. 2020.
CARNIGIE MELLON, D. G. Database of Databases – Impala. Database of Databases, 2020. Disponivel em: <https://dbdb.io/db/impala>. Acesso em: 01 mar. 2020.
CLOUDERA. Impala. GitHub, 2020. Disponivel em: <https://github.com/cloudera/impala>. Acesso em: 10 jan. 2020.
CLOUDERA. Overview. Apache Impala, 2020. Disponivel em: <https://impala.apache.org/overview.html>. Acesso em: 10 jan. 2020.
CLOUDERA. User-Defined Functions (UDFs). Cloudera Documentation, 2020. Disponivel em: <https://docs.cloudera.com/documentation/enterprise/5-13-x/topics/impala_udf.html>. Acesso em: 05 jan. 2020. Tópico: Native Impala UDFs.
DATAFLAIR. Components of Impala. Impala Architecture, 2020. Disponivel em: <https://data-flair.training/blogs/impala-architecture/>. Acesso em: 05 mar. 2020.
IBM. Funções Escalares. Knowledge Center, 2020. Disponivel em: <https://www.ibm.com/support/knowledgecenter/pt-br/SS9UMF_12.1.0/ugr/ugr/tpc/dsq_work_single_data_value.html>. Acesso em: 05 mar. 2020.
IMPALA, A. Apache Impala Guide. Apache Impala, 2020. Disponivel em: <https://impala.apache.org/docs/build/impala-2.12.pdf>. Acesso em: 13 fev. 2020.
INFOLAB, E. Perfomance Evaluation of User Definied Functions for Impala. Exascale Infolab, 2014. Disponivel em: <https://exascale.info/c++/impala/Perfomance-Evaluation-of-User-Definied-Functions-for-Impala/>. Acesso em: 27 fev. 2020.
KORNACKER, M. et al. Impala: A Modern, Open-Source. CIDR, 2015. Disponivel em: <cidrdb.org/cidr2015/Papers/CIDR15_Paper28.pdf>. Acesso em: 05 out. 2019. Cloudera: http://impala.io.
SHARMA, S. Impala UDF in C++. Clairvoyant, 2018. Disponivel em: <https://blog.clairvoyantsoft.com/impala-udf-in-c-cf8a8f4a17c9>. Acesso em: 05 jan. 2020.
SIMPLILEARN. Working with Apache Impala Tutoral. Simplilearn, 2018. Disponivel em: <https://www.simplilearn.com/working-with-impala-tutorial-video>. Acesso em: 05 jan. 2020.
STROUSTRUP, B. A Linguagem de Programação C++. Tradução de María Lúcia Blanck Lisbôa e Carlos Arthur Lang Lisbôa. 3. ed. Porto Alegre: Bookman, v. 3, 2002.
WANDERMAN-MILNE, S.; LI, N. Runtime Code Generation in Cloudera Impala. Semantic Scholar, 2014. Disponivel em: <https://www.semanticscholar.org/paper/Runtime-Code-Generation-in-Cloudera-Impala-Wanderman-Milne-Li/bac4169d6b6f713c76271b5ccf3d45293351f785>. Acesso em: 05 fev. 2020.
YUE, C. Cloudera Impala Source Code Explanation and Analisys. SlideShare, 2014. Disponivel em: <https://pt.slideshare.net/dataera/impala-source-code-analysis>. Acesso em: 17 fev. 2020.
APÊNDICE – REFERÊNCIAS DE NOTA DE RODAPÉ
2. Entidade Relacionamento.
3. NoSQL: not only SQL.
4. Neste contexto usamos o termo tempo real, para designar dados tipo streaming.
5. DDL – Data Definition Language: Classe de declarações SQL que permitem alterações nas configurações do banco de dados.
6. Fonte: <https://github.com/isocpp/CppCoreGuidelines/blob/master/CppCoreGuidelines.md#Rc-org>
7. Home Page: https://theboostcpplibraries.com
8. Standard Library.
9. Home Page: https://www.tensorflow.org/
10. Inteligência Artificial
11. Home Page: https://www.qt.io
12. MPP: Massive Parallel Processing.
13. SGBD: Sistema Gerenciador de Banco de Dados.
14. Daemon (Disk And Execution MONitor) é um programa executado em segundo plano, que entre outras funções aguarda por conexões e/ou controla fluxo de dados.
15. Além das referências explícitas é baseado em Apache Impala Tutorials. https://docs.cloudera.com/documentation/enterprise/5-13-x/topics/impala-tutorial.html.
16. Biblioteca de funções reutilizáveis para uso compartilhado pelos programas.
17. Repositório central de metadados do Apache Hive. Fonte: < https://data-flair.training/blogs/apache-hive-metastore/>
18. Fonte: <https://impala.apache.org/docs/build/html/topics/impala_create_function.html>
19. https://impala.apache.org/docs/build/html/topics/impala_double.html
20. Fonte: https://github.com/cloudera/impala-udf-samples
21. HUE: <http://gethue.com>
22. Extract, Transform and Load. Ferramentas destinadas à extração, transformação e carga de dados. Fonte: https://www.igti.com.br/blog/o-que-e-etl-bi/.
[1] Especialista em Business Intelligence e Big Data – Centro Universitário Padre Anchieta Jundiaí; Tecnólogo em Redes de Computadores – Faculdades Anhanguera de Jundiaí; Especialista em Sistemas Operacionais Unix/Linux; Especialista em Linguagem C++; Especialista em Banco de dados – Impala, Hive e Hadoop HDFS.
Enviado: Abril, 2020.
Aprovado: Outubro, 2020.
